







养成习惯,先赞后看!!!
前言
在之前的博客里面我们已经简单的讲解了ES的安装以及基本的增删改查,但是在讲解增删改查操作之前呢,忘记了一点就是教大家怎么安装 可视化界面Kibana .这里呢,跟大家讲一下.
还有一个就是ES的中文分词的问题.这个具体可以看我关于ES的第一篇博客,里面我详细讲解了ES的搜索算法的重要原理—(倒排索引),正是因为这个,所以我们还需要配置ES的中文分词.
可视化界面Kibana
大家使用Mysql数据库的时候肯定使用过像Navicat等这些数据库的可视化工具,那么显然Mysql有的,ES肯定也有,ES的可视化工具叫做Kibana,作用呢和Navicat的功能其实是类似的,也是帮助我们能够更加直观的观察ES中各节点以及节点中的相关数据的信息.
了解完Kibana的大体作用之后,我们就来了解一下怎么安装Kibana吧.
-
上传并解压
cd /opt/es tar -zxvf kibana-6.3.1-linux-x86_64.tar.gz这个过程会比较的长
并不是文件大,而是因为文件的数量比较多

-
在kibana中配置ES的信息
vi kibana.yml

如果是云服务器的话,那么这里ES的访问地址就填你服务器的公网地址就行了,不用像之前 配置ES的时候填写外网地址了.
保存退出
-
启动kibana
cd ../bin nohup ./kibana &

这样我们的kibana就已经启动
这时候我们在地址栏里面去查看一下我们的Kibana页面:
IP地址:5601
即可访问Kibana的页面了

看到这样的页面就说明我们的Kibana已经成功启动并且成功连接到我们的服务器的ElasticSearch了
并且之前我们所有的操作都是在这个界面里面执行的:
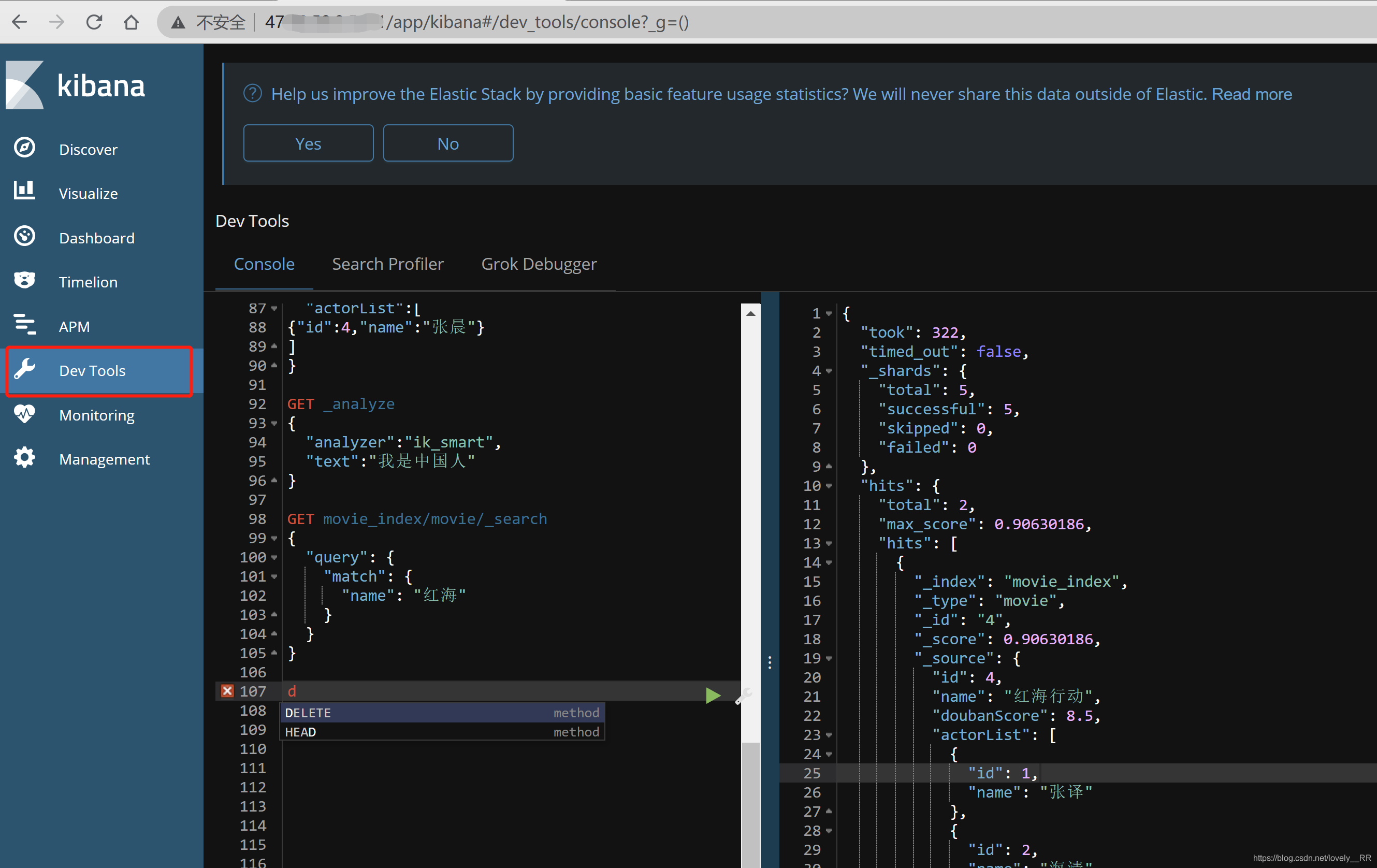
ES中文分词
还记得我们之前讲过的,ES内部的算法是通过 倒排索引 的方式来进行的,并且当初我们讲的关于倒排索引的第一步就是先将我们存入数据库的内容进行 分词 的处理,所以我们现在就需要测试一下ES的分词操作是否能够正常执行完毕.
我们先来测试一下ES对英文的分词是怎么样的,通过下图我们就能够看出来ES对英文的分词是完全可以的

但是很显然我们之后操作的数据肯定都是中文的,所以我们现在需要来测试一下看看ES是否能够识别我们的中文.

可以看到执行完毕之后我们发现ES是不能够识别中文的分词的.他只能将中文看成是单个字的集合,并不能够理解词语这个概念,既然不能够正确识别我们的词语,那么我们现在就需要配置相关的中文分词插件.
我们需要将我们的IK分词器上传到我们ES的plugins目录下面,在这里我们需要注意一点就是plugins目录下面是专门用来存放我们的插件的,并且这之后我们需要注意一点就是在:plugins目录下面都是将单个目录识别成一个插件的,不能够将一个插件解压成多个文件夹,并且必须是一个单个的文件夹里面包含该插件的所有配置信息,并且不能是多层目录嵌套的那种,否则都是识别不出来的,具体解压的格式应该是下面这种格式的.

这样的格式才是正确的格式.
解压完成之后,我们就需要将我们的ES重启,这样我们的插件才能够生效.

ES重启之后我们再去看看我们的分词器是否能够正常使用了.我们安装的分词插件是一个叫做IK的分词插件.这个插件有两种分析语法,一种是ik_smart,另外一个就是ik_max_word.
ik_smart就是比较简单的分词器
ik_max_word则是一个功能更加强悍的分词器
这里我们通过下面这个例子就能够看出来了.
这是我们指定分词器是 ik_smart 后的分词结果:

这是我们指定分词器是 ik_max_word 后的分词结果:

对比上面的结果,我们就能发现的确能够比较明显的看出来ik_max_word分词器的效果是更加强悍的.他不仅是将一句话拆成多个连续的词语,并且像 “中国人” 这个词语,他还能分解成 “中国人,中国,国人” 三个词语.这样就能够更好的实现分词的效果.
了解完分词之后,我们再来看看分词结果的各个属性分别代表什么意思

这时候大家可能又要说了,为什么需要产生这么一些分词结果呢?这里就要提到我们之前说过的一个概念就是 相关性算分 .因为这个相关性算分可能需要知道这个分词是在那里出现的,一共出现了几次等等,这些都是会直接影响相关性算分的结果的,所以分词结果才是这样的.
这样我们的ES中文分词就已经配置完毕了.
原创不易,码字不易.如果觉得对你有帮助的话,可以关注我的公众号,新人up需要你的支持!!!

不点在看,你也好看!
点点在看,你更好看!














 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









