







Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。通过链接注册并联系客服,可以获得20元代金券(相当于6-7H的免费GPU资源)。欢迎大家体验一下~
0. 简介
虽然轻地图这套方案已经被业内广泛接受并使用,但是我们发现,对于地图的依赖仍然不可或缺,只是从HD(高精地图)降到了车道级地图(LD Map)乃至标准地图(SD Map)。所以说,我们如果高效的去获取向量化的道路还是非常关键的。《Segment Anything Model for Road Network Graph Extraction》一文。这是对 Segment Anything Model (SAM) [29] 的一种改进,用于从卫星图像中提取大规模、矢量化的道路网络图。为了预测图形几何结构,我们将其形式化为一个密集语义分割任务,利用了 SAM 的固有优势。SAM 的图像编码器经过微调后可生成道路和交叉口的概率掩码,从中通过简单的非极大值抑制提取图的顶点。为了预测图的拓扑结构,我们设计了一种轻量级的基于Transformer的图神经网络,该网络利用 SAM 图像嵌入来估计顶点之间边的存在概率。我们的方法直接预测大区域的图顶点和边,而无需昂贵和复杂的后处理启发式方法,并能够在几秒钟内构建跨越多个平方公里的完整道路网络图。凭借其简单、直接和极简的设计,SAM-Road 在 City-scale 数据集上实现了与最先进方法 RNGDet++[61] 相当的精度,同时速度快 40 倍。因此,我们展示了基础视觉模型在图学习任务中的强大功能。代码可在Github上获取。
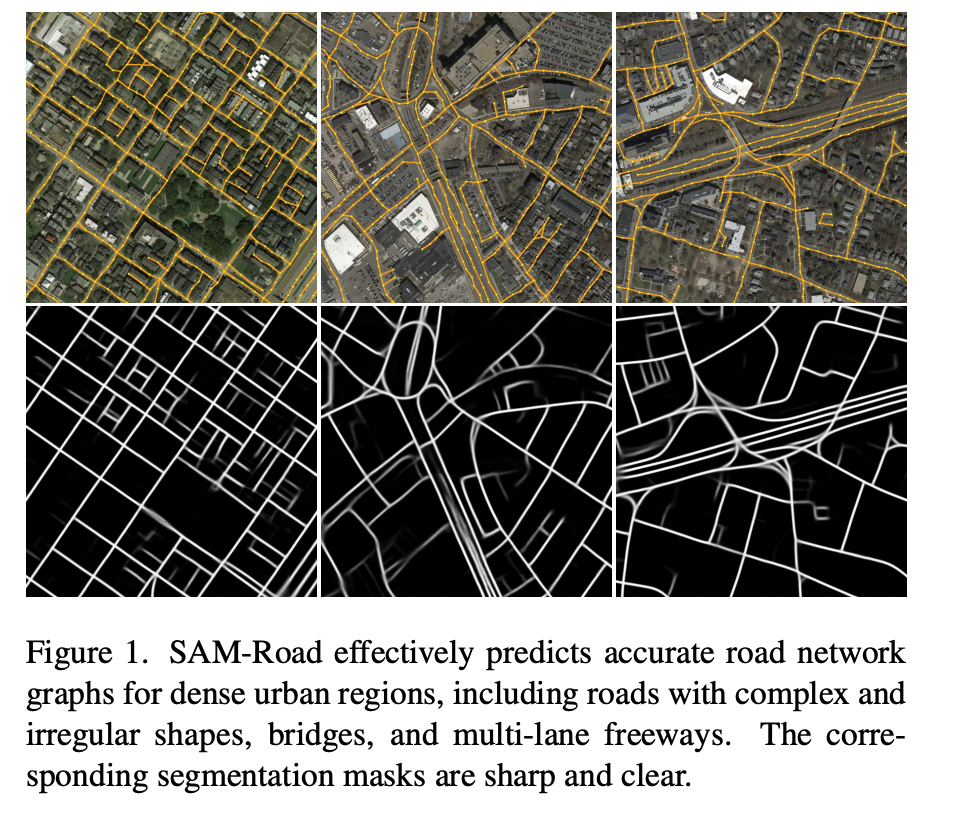
图 1. SAM-Road 能有效预测密集城市区域的准确道路网络图,包括形状复杂和不规则的道路、桥梁和多车道高速公路。相应的分割掩码清晰锐利。
1. 主要贡献
-
SAM-Road 模型:发挥了SAM模型的能力,结合了语义分割和图神经网络。模型可以直接预测图的顶点和边,无需复杂的后处理启发式方法。
-
图形几何和拓扑预测:使用密集语义分割来预测图形的几何结构,并使用轻量级的基于Transformer的图神经网络来预测拓扑结构,从而实现准确和快速的预测。
-
效率和速度:在城市数据集上的处理速度比现有最先进的方法快 40 倍,同时不牺牲准确性,能够在几秒钟内构建跨越数平方公里的完整道路网络图。
2. 具体框架
SAM-Road 的整体结构如图 2 所示。它包含一个来自预训练 SAM [29] 的图像编码器,一个几何解码器和一个拓扑解码器。模型以 RGB 卫星图像作为输入。首先,图像编码器生成图像特征嵌入。然后,几何解码器预测每个像素的存在概率,包括道路和交叉口。这些掩码通过一个简单的非极大值抑制过程(详见算法 1)提取出表示 2D 位置的图顶点集合
V
=
{
v
i
∈
R
2
}
V = \{v_i \in \mathbb{R}^2\}
V={vi∈R2}。在预测的顶点给定的情况下,拓扑解码器遍历每个顶点,并根据其局部上下文确定是否应连接到其给定半径
R
n
b
r
R_{nbr}
Rnbr 内的附近顶点。对于边
(
v
i
,
v
j
)
(v_i, v_j)
(vi,vj),它预测其存在的概率。一条边可能被预测多次,其最终得分将是平均值。最终,道路网络图
G
G
G被预测为顶点集合
V
V
V 和边集合
E
E
E。
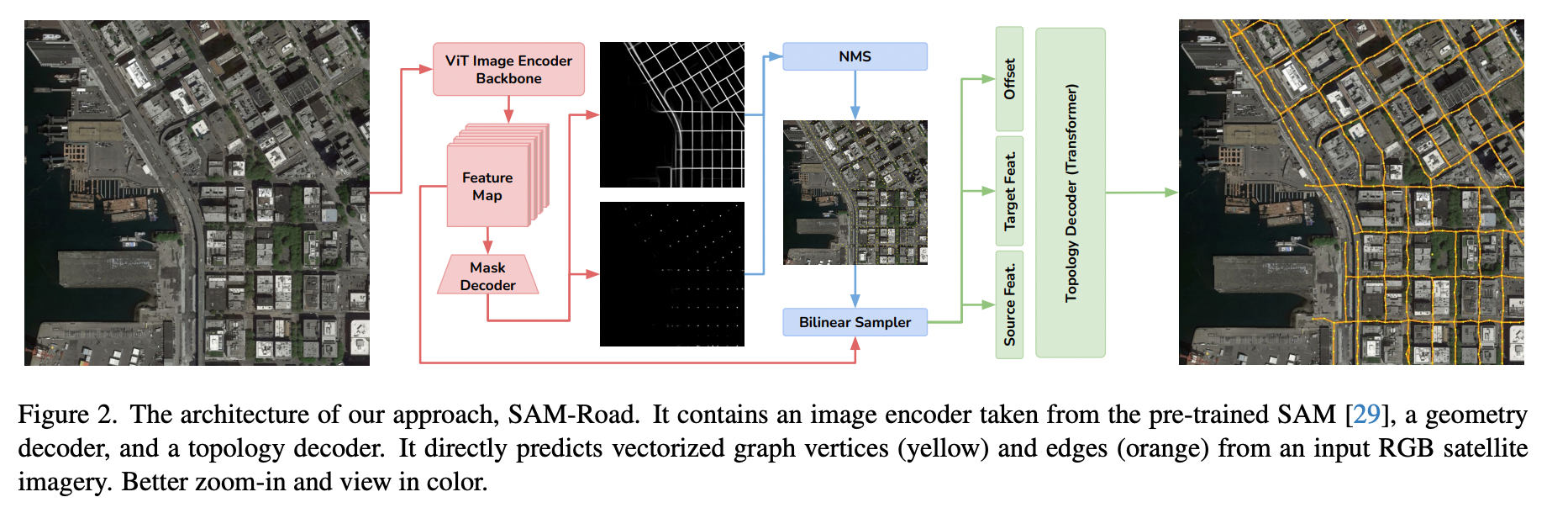
图 2. 我们的方法 SAM-Road 的架构。它包含一个来自预训练 SAM [29] 的图像编码器,一个几何解码器和一个拓扑解码器。它直接从输入的 RGB 卫星图像中预测矢量化的图形顶点(黄色)和边(橙色)。请放大查看,并使用彩色显示以获得更好的效果。
3. 图像编码器
图像编码器取自预训练的 Segment Anything Model。我们使用了最小的 ViT-B 变体,它大约有 8000 万个可训练参数。它采用适用于高分辨率图像的 ViT [16] 架构,如 ViTDet [32] 中所述。图像编码器将一个 ( H i m g , W i m g , 3 ) (H_{img}, W_{img}, 3) (Himg,Wimg,3)的 RGB 图像转换为 ( H i m g / 16 , W i m g / 16 , D f e a t ) (H_{img} / 16, W_{img} / 16, D_{feat}) (Himg/16,Wimg/16,Dfeat) 的特征图,以供解码器使用。图像首先被划分为 16×16 的非重叠块,然后每个块被编码为一个嵌入向量,生成一个 ( H i m g / 16 , W i m g / 16 , D f e a t ) (H_{img} / 16, W_{img} / 16, D_{feat}) (Himg/16,Wimg/16,Dfeat)的张量。12 层多头自注意力层的堆栈处理这个张量,交替使用窗口化 [38] 和全局自注意力。特征尺寸在整个过程中保持不变。在训练过程中,我们以 0.1 倍的基础学习率微调整个图像编码器,以适应卫星图像。
4. 几何解码器
图形几何预测被表述为一个密集的语义分割任务。这有两个主要好处:首先,这种表述利用了 SAM 的强大功能;其次,每像素的自下而上的表示可以处理任意复杂的道路结构。
掩码解码器的设计非常简约:它只是 4 层转置卷积层,每层使用 3 × 3 的卷积核和步幅 2,每层将空间特征分辨率加倍并减少通道数。最终,它生成两个概率图,作为一个 ( H i m g , W i m g , 2 ) (H_{img}, W_{img}, 2) (Himg,Wimg,2)的张量,与输入图像大小相同,代表交叉点和道路的存在概率。这个掩码解码器包含大约 17 万个可训练参数。
在获得掩码后,从中提取图形顶点。这个过程将密集的掩码图像转换为一组稀疏顶点,顶点之间的间隔大致相同,记为
d
v
d_v
dv。选择
d
v
d_v
dv 时需确保稀疏的同时不损害几何精度。具体实现为简单的非极大值抑制:首先丢弃低于概率阈值
t
t
t 的像素,然后按概率的降序遍历它们。移除当前像素
d
v
d_v
dv 半径范围内的像素。剩余像素的
(
x
,
y
)
(x, y)
(x,y) 位置形成图形顶点
V
=
{
v
i
∈
R
2
}
V = \{v_i \in \mathbb{R}^2\}
V={vi∈R2}。详见算法 1。

我们为交叉口和道路分别预测掩码,以在交叉口处获得更准确的图形结构。如果只有道路掩码,无法保证交叉口的中心点会被保留,可能会产生如图 6 所示的误差模式。为了解决这个问题:1). 使用相同的非极大值抑制(NMS)算法从两个掩码中提取顶点。2). 将两组顶点合并,所有交叉口顶点的得分都高于任何道路顶点。3). 对合并后的集合再次进行 NMS 处理以生成最终结果。这确保了尽可能多地保留交叉点。

图 6. 左图:标准的 SAM-Road。中图:无交叉口掩码。交叉口明显更加噪杂。右图:使用 A* 算法进行拓扑预测,导致许多错误的正连接。
5. 拓扑解码器
拓扑解码器将预测的图顶点“连线”成正确的结构。它是一个基于Transformer的图神经网络,预测边的存在性。它在每个顶点周围的小局部子图中预测边存在的概率。具体来说,对于给定的源顶点,在半径 R n b r R_{nbr} Rnbr内找到最多 N n b r N_{nbr} Nnbr个最近的顶点。这些顶点构成目标顶点。拓扑解码器根据它们的空间布局和图像上下文来预测源顶点是否应与每个目标连接。
这里的连接定义为“图上两个顶点是否是直接相邻的”。即,想象一下从源顶点在道路网络图上进行广度优先搜索,当 a) 遇到目标顶点或 b) 深度(搜索半径)超过
R
n
b
r
R_{nbr}
Rnbr 时停止扩展——只有当目标顶点被搜索访问时才与源顶点连接。图 3 对此进行了进一步说明。

图 3. 拓扑标签定义的示意图。在 (a) 中,白色虚线圆表示 R n b r R_{nbr} Rnbr;大点是源节点,较小的黄色点是目标节点。橙色线是连接的对。在 (b) 中,显示了一些用于训练的实际拓扑样本。查询一个源节点用相同的颜色表示。白色线是正标签,没有线的对是负标签。
我们将拓扑预测任务表述为一个条件在图像上下文上的二元分类问题,针对 ( v s r c , v t g t ) (v_{src}, v_{tgt}) (vsrc,vtgt)顶点对。解码器的输入是一系列高维特征向量 { ( f s r c , f k t g t , d k ⃗ ) ∣ 0 ≤ k < N n b r } \{(f^{src}, f^{tgt}_{k}, \vec{d_k}) \mid 0 \le k < N_{nbr}\} {(fsrc,fktgt,dk)∣0≤k<Nnbr},其中 f s r c f^{src} fsrc 和 f k t g t f^{tgt}_{k} fktgt是顶点特征。它们是通过双线性采样从 SAM 图像特征图在源和目标顶点位置获取的图像嵌入向量。 d k ⃗ \vec{d_k} dk 是从源到第 k 个目标的偏移量,编码感兴趣顶点的相对空间布局。这些向量被连接成一个形状为 ( N n b r , 2 D f e a t + 2 ) (N_{nbr}, 2D_{feat} + 2) (Nnbr,2Dfeat+2) 的张量,然后投影到 ( N n b r , D f e a t ) (N_{nbr}, D_{feat}) (Nnbr,Dfeat)特征张量。我们将 N n b r N_{nbr} Nnbr 维度视为序列长度,通过 3 层具有 ReLU 激活的多头自注意力层进行消息传递,以理解多跳结构。交互后的特征序列形状为 ( N n b r , D f e a t ) (N_{nbr}, D_{feat}) (Nnbr,Dfeat),被输入到一个线性层,以获得 N n b r N_{nbr} Nnbr 个二元分类对数。一个 sigmoid 层将这些转换为 (0, 1) 概率,指示边存在的可能性。
6 .标签生成
6.1 掩码标签
对于道路掩码标签,我们将地面真实道路线栅格化,绘制每条边为宽度为 3 像素的线段。线段覆盖的像素设置为 1,其他像素设置为 0。对于交叉口标签,我们找到所有度不等于 2 的图顶点,并将它们渲染为半径为 3 像素的圆。这部分灵感来自 OpenPose [8] 的工作,该工作将人体关键点图表示为热图。
6.2 拓扑标签
在训练过程中,我们不运行顶点提取过程。拓扑解码器以教师强制 [55] 方式进行训练,即被询问的顶点不是来自模型预测,而是从地面真实道路网络图中采样以模拟预测。这是通过先细分地面真实图,然后运行与推理阶段相同的 NMS 过程来实现的。为了模拟各种 NMS 结果,给每个细分顶点分配一个均匀的随机分数。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











