







0. 简介
很多工作围绕NERF+BEV做自监督三维占用预测。这样其实省去了3D激光雷达标注所需要的时间,完全可以通过2D的结果来进一步完成自监督3D占用预测。而随着3DGS的爆火, 相比于NERF而言更具有优势,GaussianOcc是一种系统方法,它研究了Gaussian Splatting的两种用途,用于在环视图中实现完全自监督且高效的3D占用率估计。首先,传统的自监督3D占用率估计方法在训练过程中仍然需要来自传感器的真实6D姿态。为了克服这一限制,这里提出了用于投影的Gaussian Splatting(GSP)模块,以通过相邻视图投影为完全自监督训练提供准确的尺度信息。此外,现有方法依赖于volume渲染,利用2D信号(深度图、语义图)进行最终的3D体素表示学习,这既耗时又低效。这里提出了来自体素空间的Gaussian Splatting(GSV),以利用Gaussian Splatting的快速渲染特性。相关代码已经发在GIthub上了。如果对3DGS不太了解的可以看一下《3D Gaussian Splatting是什么以及为什么这么火》这篇文章。
1. 主要贡献
环视3D占用率估计已成为一项核心感知任务,并有望成为鸟瞰图(BEV)方法的有前途的替代方案。为了促进3D占用率估计,已经开发了几种用于监督训练的基准,但这些基准在3D标注方面需要付出巨大努力。为了减轻标注负担,已经提出了基于volume渲染的自监督和弱监督学习方法。volume渲染允许使用2D监督信号(如2D语义图和深度图)进行3D表示学习,从而消除了训练过程中需要大量3D标注的需要。
为了解决上述限制,我们探索了一种完全自我监督且高效的三维占用估计方法,基于高斯溅射技术 [1, 27]。具体而言,我们引入高斯溅射技术来执行跨视图溅射,其中渲染图像构建了一个跨视图损失,该损失在与6D姿态网络的联合训练中提供了尺度信息。这消除了训练过程中对真实6D姿态的需求。为了提高渲染效率,我们摒弃了传统体积渲染中所需的密集采样。相反,我们提出直接从三维体素空间进行高斯溅射。在这种方法中,体素网格中的每个顶点被视为一个三维高斯分布,我们直接优化这些高斯分布的属性——例如语义特征和不透明度——在体素空间内。通过这种新颖的方法,我们提出的GaussianOcc在实现完全自我监督和高效的三维占用估计方面取得了进展,如图1所示。(这样做就不需要提供特征点或者Sfm的稀疏点了)。
本工作的主要贡献总结如下:
- 我们提出了首个完全自我监督的高效周围视图三维占用估计方法,探索了高斯溅射技术。
- 我们提出了用于跨视图投影的高斯溅射,这可以提供尺度信息,从而消除训练过程中对真实6D姿态的需求。
- 我们提出了从体素空间进行高斯溅射的方法,与传统体积渲染相比,实现了训练速度提高2.7倍和渲染速度提高5倍的竞争性能。
2. 预备知识
在本文中,我们研究了使用三维高斯溅射 [27] 进行完全自我监督的三维占用估计。三维高斯溅射(3D-GS)是一种利用点原语对静态三维场景建模的技术。每个点被表示为一个缩放的高斯分布,其特征由三维协方差矩阵 Σ \Sigma Σ 和均值 μ \mu μ 描述。点 X X X 的高斯分布表示为: (点的高斯分布涉及到协方差,中心点这些因素)
G ( X ) = e − 1 2 ( X − μ ) T Σ − 1 ( X − μ ) (1) G(X) = e^{-\frac{1}{2}(X - \mu)^T \Sigma^{-1}(X - \mu)} \tag{1} G(X)=e−21(X−μ)TΣ−1(X−μ)(1)
为了通过梯度下降实现高效的优化,协方差矩阵 Σ \Sigma Σ 被分解为一个缩放矩阵 S S S 和一个旋转矩阵 R R R,具体如下(高斯分布协方差矩阵如何转化为缩放和旋转,通过拟合这个协方差来填充整个空间,优化的也是这个参数):
Σ = R S S T R T (2) \Sigma = RS S^T R^T \tag{2} Σ=RSSTRT(2)

将高斯分布从三维空间投影到二维图像平面涉及视图变换 W W W 和投影变换的仿射近似的雅可比矩阵 J J J。二维协方差矩阵 Σ ′ \Sigma' Σ′ 的计算公式为:
Σ ′ = J W Σ W T J T (3) \Sigma' = J W \Sigma W^T J^T \tag{3} Σ′=JWΣWTJT(3)

随后,应用了一种与 NeRF [36] 中使用的技术类似的 alpha-blend 渲染方法。其公式为:
C color = ∑ i ∈ N c i α i ∏ j = 1 i − 1 ( 1 − α i ) (4) C_{\text{color}} = \sum_{i \in N} c_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_i) \tag{4} Ccolor=i∈N∑ciαij=1∏i−1(1−αi)(4)
在这里, c i c_i ci 表示每个点的颜色,而密度 α i \alpha_i αi 由二维高斯分布与协方差 Σ ′ \Sigma' Σ′ 及学习得到的每点不透明度的乘积决定。颜色则使用球谐(SH)系数定义,如 [10, 27] 中所述。

总之,基本的三维高斯点云渲染方法通过以下属性来表征每个高斯点:(1) 三维位置 X ∈ R 3 X \in \mathbb{R}^3 X∈R3,(2) 由 SH 系数定义的颜色 c ∈ R k c \in \mathbb{R}^k c∈Rk(其中 k k k 表示 SH 基的维度),(3) 由四元数表示的旋转 r ∈ R 4 r \in \mathbb{R}^4 r∈R4,(4) 一个缩放因子 s ∈ R + 3 s \in \mathbb{R}^3_+ s∈R+3,以及 (5) 不透明度 α ∈ [ 0 , 1 ] \alpha \in [0, 1] α∈[0,1]。
3. 提出的 GaussianOcc 概述
GaussianOcc 的概述如图 2 所示。其主要贡献在于引入了跨视角高斯点云渲染以实现尺度感知训练,以及体素网格高斯点云渲染以加快渲染速度。与用于场景特定三维重建的原始高斯点云渲染不同,我们探索了一种设置,其中高斯属性在二维和三维网格中均良好对齐。这种方法将三维场景在二维图像平面中建模为深度图,并在三维网格空间中建模为体素(占用)格式。
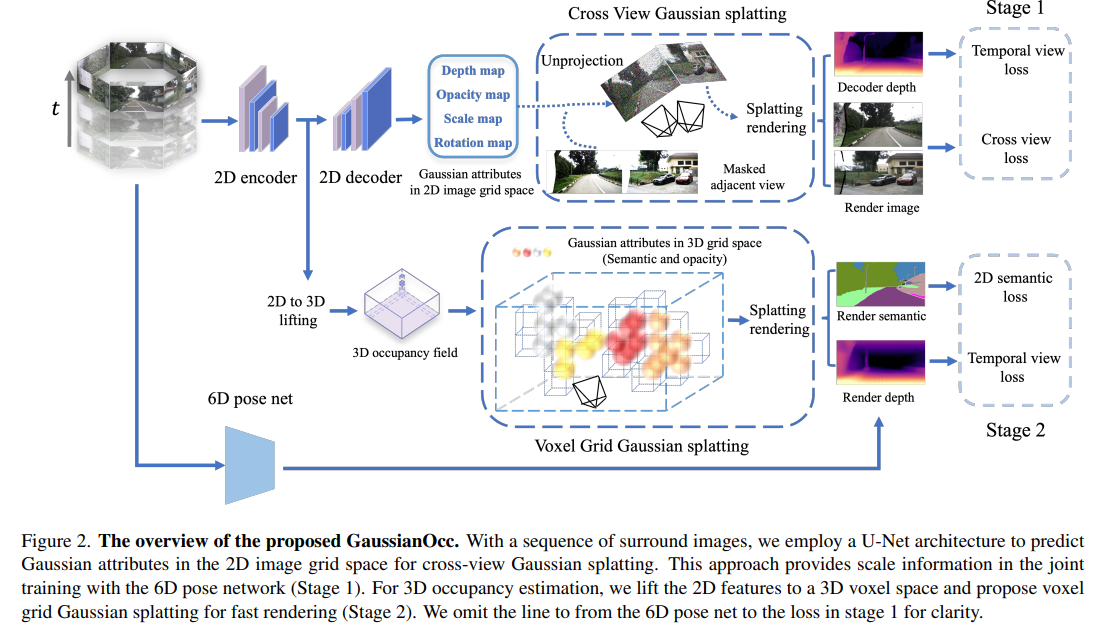
图 2. 提出的 GaussianOcc 概述。通过一系列周围图像,我们采用 U-Net 架构在二维图像网格空间中预测高斯属性,以实现跨视角高斯点云渲染。这种方法在与 6D 位姿网络的联合训练中提供了尺度信息(阶段 1)。对于三维占用估计,我们将二维特征提升到三维体素空间,并提出体素网格高斯点云渲染以实现快速渲染(阶段 2)。为清晰起见,我们省略了从 6D 位姿网络到阶段 1 损失的连接线。
4. 基于高斯点云渲染的尺度感知训练
来自空间相机装置的尺度信息与之前的工作 [16, 44] 类似,尺度信息来自周围的相机装置。具体而言,可以通过利用相机的外部矩阵来获取真实世界的尺度,这涉及在两个相邻视图之间的重叠区域使用空间光度损失,即将 I t i I^i_t Iti 变形为 I t j I^j_t Itj:
p t i → j = K j ( T j ) − 1 T i D t i ( K i ) − 1 p t i (5) p^{i \to j}_t = K^j (T^j)^{-1} T^i D^i_t (K^i)^{-1} p^i_t \tag{5} pti→j=Kj(Tj)−1TiDti(Ki)−1pti(5)
其中 K i K^i Ki 和 T i T^i Ti 分别是第 i i i 个相机的内外部矩阵, D t i D^i_t Dti 是第 i i i 个相机的预测深度图, p t p^t pt 是在变形过程中对应的像素。变形操作通过双线性插值与相应的 p t i → j p^{i \to j}_t pti→j 实现。然而,正如 [44] 所指出的那样,在如此小的重叠区域中,映射 p t i → j p^{i \to j}_t pti→j 容易超出图像边界,且监督信号较弱。我们的实践也验证了这一限制。为了提供更强的监督信号,[44] 提出了利用运动结构(SFM)提取稀疏深度信息以进行尺度感知训练的方法,但这既耗时又不够直接。与此不同,我们提出使用高斯点云渲染进行尺度感知投影,以实现跨视角立体约束。
高斯点云渲染用于投影(GSP)
如图 2 所示,我们使用深度网络预测二维网格空间中的高斯属性,包括深度图、尺度图和旋转图。对于每个相邻视图,我们首先计算重叠区域的掩膜,然后将这些重叠区域的一侧进行掩蔽。由于另一侧的重叠区域的存在,未投影的三维场景保持完整,这对于提供尺度训练至关重要,如实验部分所示。然后,我们对相邻视图进行点云渲染,以获得渲染图像。如果深度图被准确学习,渲染图像应与原始图像相似,从而为整个流程提供必要的尺度信息。
获取重叠掩膜的过程如图 3 所示。重叠掩膜的获取基于体积渲染。我们在一个视图中沿光线密集采样点,如果在相邻视图中有多个采样的三维点落入同一像素,则该像素被视为重叠区域的一部分。请注意,在 DDAD 数据集 [14] 中,我们排除了自遮挡的区域(例如车辆车身的部分)。最后,我们对掩膜应用来自 OpenCV 库 [2] 的腐蚀操作以进行净化。
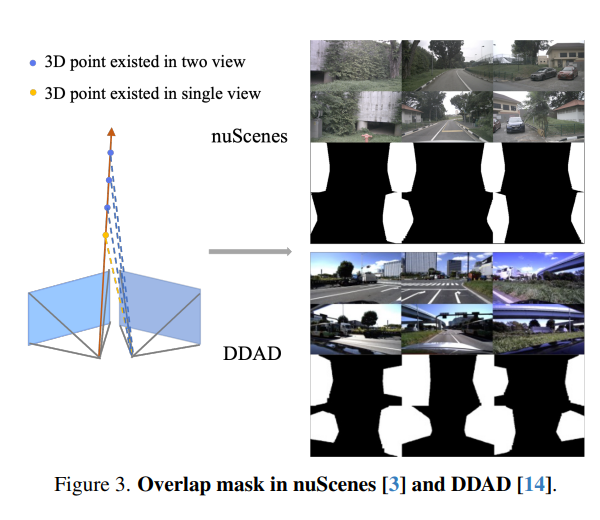
图 3. nuScenes [3] 和 DDAD [14] 中的重叠掩码



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











