







0. 简介
深度强化学习(Deep Reinforcement Learning, DRL)作为工业系统决策与控制的利器,正推动机器人控制、自动驾驶等领域的快速发展。然而,基于值函数的方法普遍面临一个棘手问题——过估计(Overestimation)。这种现象指的是算法在估计状态-动作价值时,往往高估了真实值,进而可能导致策略学习偏离最优,甚至训练不稳定。
本文将带你深入了解清华大学团队提出的 值分布强化学习(Distributional Soft Actor-Critic, DSAC) 系列算法,如何从根本上缓解过估计问题,并在强化学习领域实现性能与稳定性的双重飞跃。
1. 过估计问题的本质与挑战
过估计问题主要源自于Q值更新中的最大化操作符。当使用神经网络逼近动作价值函数时,估计误差不可避免,最大化操作会放大正向误差,导致Q值系统性偏高。这种偏差不仅误导智能体选择次优动作,还会引发训练过程震荡,降低算法的泛化能力。
2. DSAC系列算法:从期望值到价值分布
引言
近年来,强化学习(Reinforcement Learning, RL)在人工智能领域取得了显著进展,成为研究者们关注的核心领域之一。然而,尽管强化学习在许多应用中取得了突破,仍然面临着诸如策略评估不稳定和过估计等挑战。尤其是Q值的过估计问题,往往导致算法在训练过程中无法准确评估策略,从而影响优化效果。为了解决这一难题,值分布强化学习(Distributional Reinforcement Learning, DRL)应运而生,它通过显式建模价值的分布,缓解了过估计现象,并增强了策略优化的精度与鲁棒性。
基于这一思想,清华大学团队在2021年提出了DSAC(Distributional Soft Actor-Critic)算法,通过引入值分布方法有效减少了过估计带来的不利影响,并在多种强化学习任务中取得了显著的性能提升。然而,DSAC-v1在训练稳定性和处理复杂环境时仍存在一些挑战。为此,团队在DSAC-v1的基础上进行了三项关键性创新改进,推出了DSAC-T(DSAC-v2)。
传统强化学习方法通常只学习累计奖励的期望值(即单一的Q值)。DSAC系列则采用值分布强化学习思想,直接建模累计折扣奖励的完整概率分布,为解决过估计提供了新路径。
2.1 DSAC-v1:自适应步长抑制过估计
2021年,清华团队提出了第一代DSAC算法(DSAC-v1),将值分布学习与高效的连续控制算法Soft Actor-Critic(SAC)结合,利用参数化高斯分布来近似奖励分布。
-
核心创新:通过学习奖励分布的方差,动态调节Q值更新的步长。当估计不确定性高(方差大)时,自动减小更新步长,抑制因噪声引起的过度更新,缓解过估计。
-
局限性:由于值分布学习本身复杂,DSAC-v1在训练过程中存在不稳定,尤其是对奖励尺度敏感,固定的目标回报裁剪边界限制了算法跨任务的适应性。
2.2 DSAC-T(DSAC-v2):三大关键改进,性能再跃升
针对DSAC-v1的不足,2024年团队发布了第二代算法DSAC-T,提出三项关键改进(见图1):
-
期望值替代(Expected Value Substitution)
用目标回报的期望值代替随机目标回报计算均值梯度,显著降低梯度方差,提升学习稳定性。 -
基于方差的值函数梯度调整(Variance-Based Critic Gradient Adjustment)
将固定裁剪边界替换为动态自适应边界,依据当前值分布方差调整梯度步长,增强算法对不同奖励尺度的鲁棒性。 -
孪生值分布学习(Twin Value Distribution Learning)
训练两个独立值分布网络,更新时选择均值较小的网络输出,进一步压制过估计,避免策略陷入局部最优。
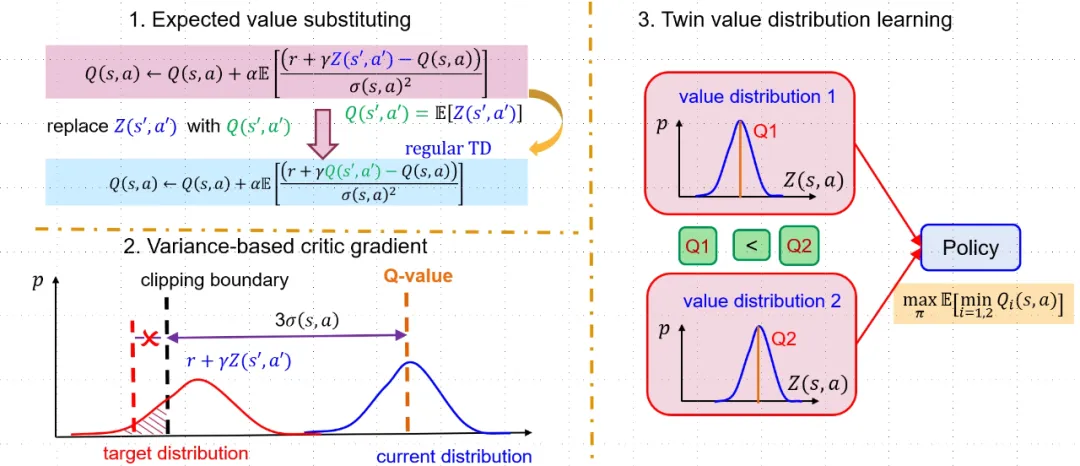
这三项改进协同作用,不仅继承了DSAC-v1的核心理念,更解决了稳定性和调参难题,使DSAC-T成为鲁棒且性能领先的强化学习算法。
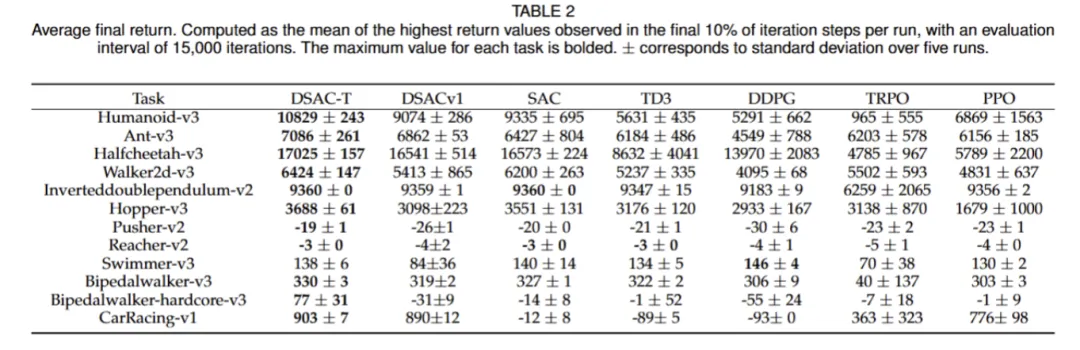
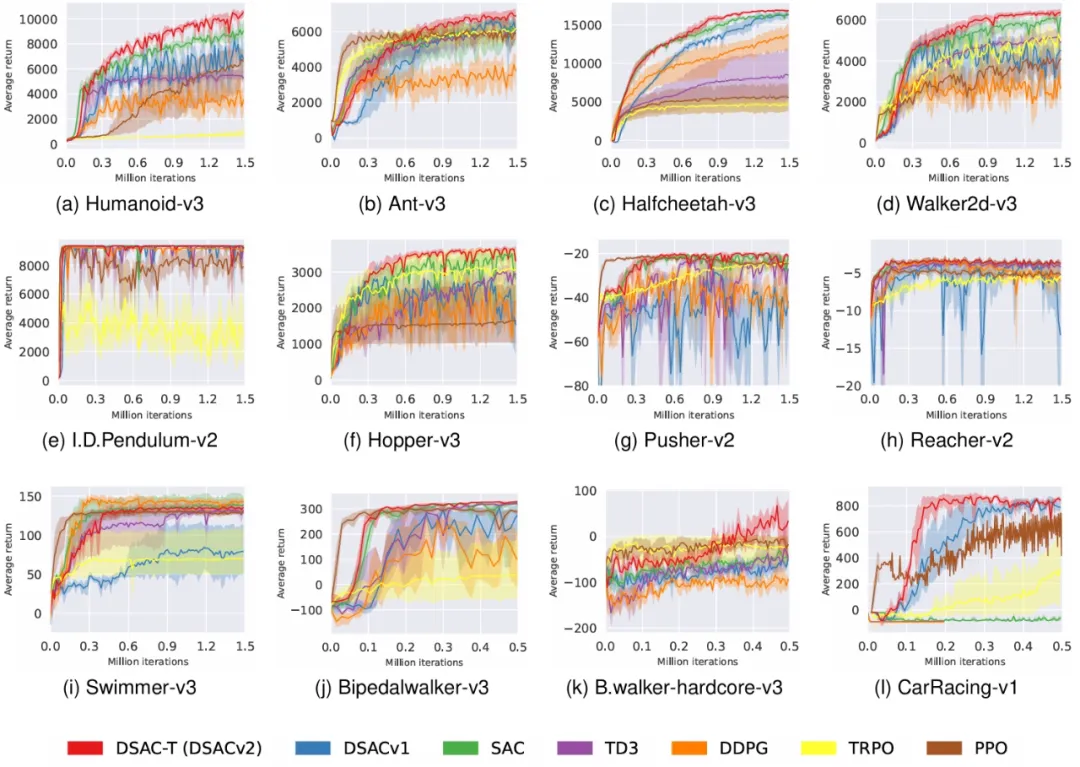
3. DSAC-T的实证优势
DSAC-T在MuJoCo等多个连续控制任务中表现卓越(见图2训练曲线):
-
性能领先:无需针对单个任务调整超参数,性能普遍优于SAC、TD3、PPO、TRPO、DDPG等主流算法。
-
训练稳定:曲线平滑,收敛速度快,训练过程波动小。
-
鲁棒性强:跨不同奖励尺度任务均表现稳健,验证了基于方差的自适应调整机制的有效性。
-
有效缓解过估计:Q值估计偏差显著降低,避免策略陷入局部最优。
4. DSAC与GRPO:两种强化学习算法的对比
近期在大型语言模型(LLM)推理任务中,另一种强化学习算法——组相对策略优化(Group Relative Policy Optimization, GRPO)备受关注。它与DSAC-T有以下显著区别:
| 维度 | DSAC-T | GRPO |
|---|---|---|
| 核心框架 | 基于Actor-Critic,训练值分布网络估计状态-动作价值分布 | 无值网络,通过组内相对比较获得策略更新信号 |
| 价值估计 | 显式建模累计奖励分布,指导连续动作优化 | 基于组内奖励相对排名,适合离散输出评估 |
| 适用场景 | 连续控制任务,如机器人运动、自动驾驶轨迹规划 | LLM推理任务,评估输出质量(如数学题正确性) |
| 计算资源 | 中小规模模型,计算和内存需求可控 | 大规模模型,需处理海量参数和复杂评估 |
简而言之,DSAC-T更适合需要精细价值估计和连续动作控制的工业应用,而GRPO则针对LLM中策略优化的特殊需求设计。
5. DSAC-T 代码结构与实现分析
DSAC-T(DSAC-v2)的代码实现遵循模块化设计原则,结构清晰易于扩展。以下是关键组件及其实现细节。
5.1 核心模块结构
DSAC-T 的代码主要由以下几个部分组成:
DSAC-v2/
├── dsac_v1.py # DSAC-v1 算法实现
├── dsac_v2.py # DSAC-T (DSAC-v2) 算法实现
├── example_train/ # 训练示例脚本
│ ├── main.py # Pendulum 环境训练入口
│ └── dsac_mlp_humanoidconti_offserial.py # Humanoid 环境训练入口
├── utils/ # 工具函数
├── results/ # 训练结果保存目录
└── DSAC2.0_environment.yml # 环境配置文件
5.2 算法实现关键组件
5.2.1 ApproxContainer 类实现
ApproxContainer 类封装了 DSAC-T 所需的神经网络模型:
class ApproxContainer(torch.nn.Module):
"""
网络容器类,包含策略网络和Q网络
"""
def __init__(self, **kwargs):
super().__init__()
# 如果启用 CNN 特征共享
if kwargs["cnn_shared"]:
feature_args = get_apprfunc_dict("feature", kwargs["value_func_type"], **kwargs)
kwargs["feature_net"] = create_apprfunc(**feature_args)
# 创建双Q网络 (孪生网络结构)
q_args = get_apprfunc_dict("value", kwargs["value_func_type"], **kwargs)
self.q1: nn.Module = create_apprfunc(**q_args) # Q网络1
self.q2: nn.Module = create_apprfunc(**q_args) # Q网络2
self.q1_target = deepcopy(self.q1) # Q1目标网络
self.q2_target = deepcopy(self.q2) # Q2目标网络
# 创建策略网络
policy_args = get_apprfunc_dict("policy", kwargs["policy_func_type"], **kwargs)
self.policy: nn.Module = create_apprfunc(**policy_args)
self.policy_target = deepcopy(self.policy)
# 设置目标网络参数为不可训练
for p in self.policy_target.parameters():
p.requires_grad = False
for p in self.q1_target.parameters():
p.requires_grad = False
for p in self.q2_target.parameters():
p.requires_grad = False
# 创建熵调节系数 (自适应温度参数)
self.log_alpha = nn.Parameter(torch.tensor(1, dtype=torch.float32))
# 创建优化器
self.q1_optimizer = Adam(self.q1.parameters(), lr=kwargs["value_learning_rate"])
self.q2_optimizer = Adam(self.q2.parameters(), lr=kwargs["value_learning_rate"])
self.policy_optimizer = Adam(
self.policy.parameters(), lr=kwargs["policy_learning_rate"]
)
self.alpha_optimizer = Adam([self.log_alpha], lr=kwargs["alpha_learning_rate"])
5.2.2 DSAC-T 算法核心实现
DSAC-T 的核心改进在 DSAC_V2 类中实现:
class DSAC_V2:
"""DSAC_V2(DSAC-T) 算法实现
论文: https://arxiv.org/abs/2310.05858
参数:
gamma: 折扣因子
tau: 目标网络软更新系数
auto_alpha: 是否自动调整温度参数
alpha: 初始温度参数值
delay_update: 策略网络延迟更新步数
tau_b: 标准差滑动平均更新系数
"""
def __init__(self, **kwargs):
super().__init__()
self.networks = ApproxContainer(**kwargs)
self.gamma = kwargs["gamma"]
self.tau = kwargs["tau"]
self.target_entropy = -kwargs["action_dim"]
self.auto_alpha = kwargs["auto_alpha"]
self.alpha = kwargs.get("alpha", 0.2)
self.delay_update = kwargs["delay_update"]
# 存储标准差的滑动平均值,用于动态调整梯度步长
self.mean_std1 = -1.0 # Q1网络的标准差平均值
self.mean_std2 = -1.0 # Q2网络的标准差平均值
self.tau_b = kwargs.get("tau_b", self.tau) # 标准差更新系数



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











