






数据库中高级诊断订阅课程小伙伴群中,一个朋友反馈了他们维护的某大客户核心系统,使用了superdome flex 跑Oracle集群,发现性能似乎都快扛不住了。
我们首先来看看这个牛叉的机器到底有多强悍:
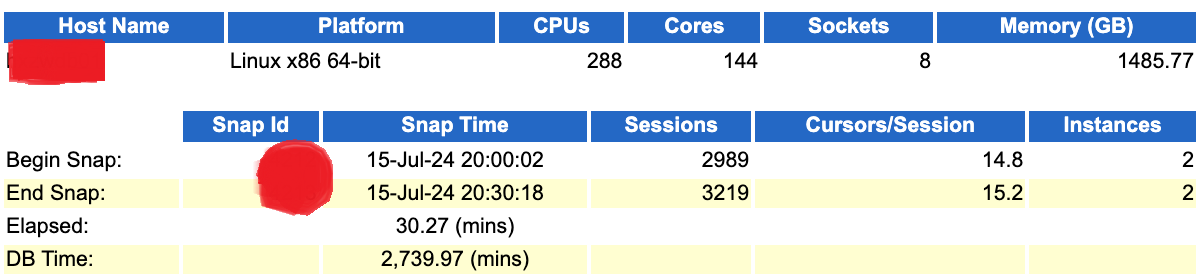
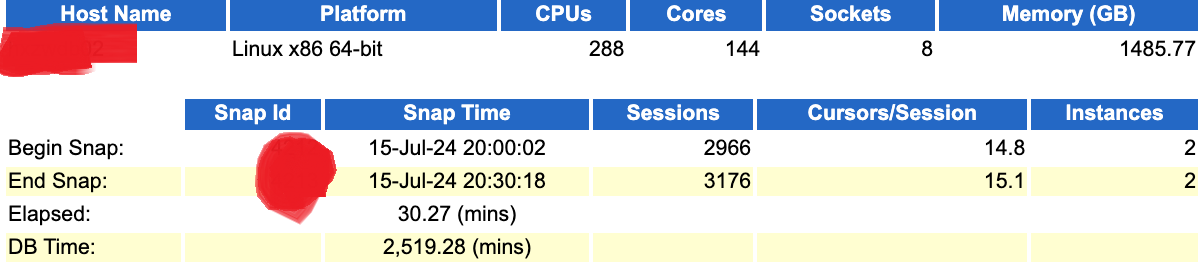
从数据来看,数据库服务配置真的非常强悍,288c,1.5TB内存,至于存储,我想应该也是顶级全闪阵列了,否则不搭配呀。同时我们可以到就算是晚上跑批阶段,数据库压力也不小,每个节点session都在3000出头。
根据群友的反馈,正常情况下跑批20分钟完成,异常情况下跑了1小时左右,也就是说慢了3倍左右!
跑批快的性能数据
我们来看下此时节点1的load profile负载(反馈跑批正常的阶段):
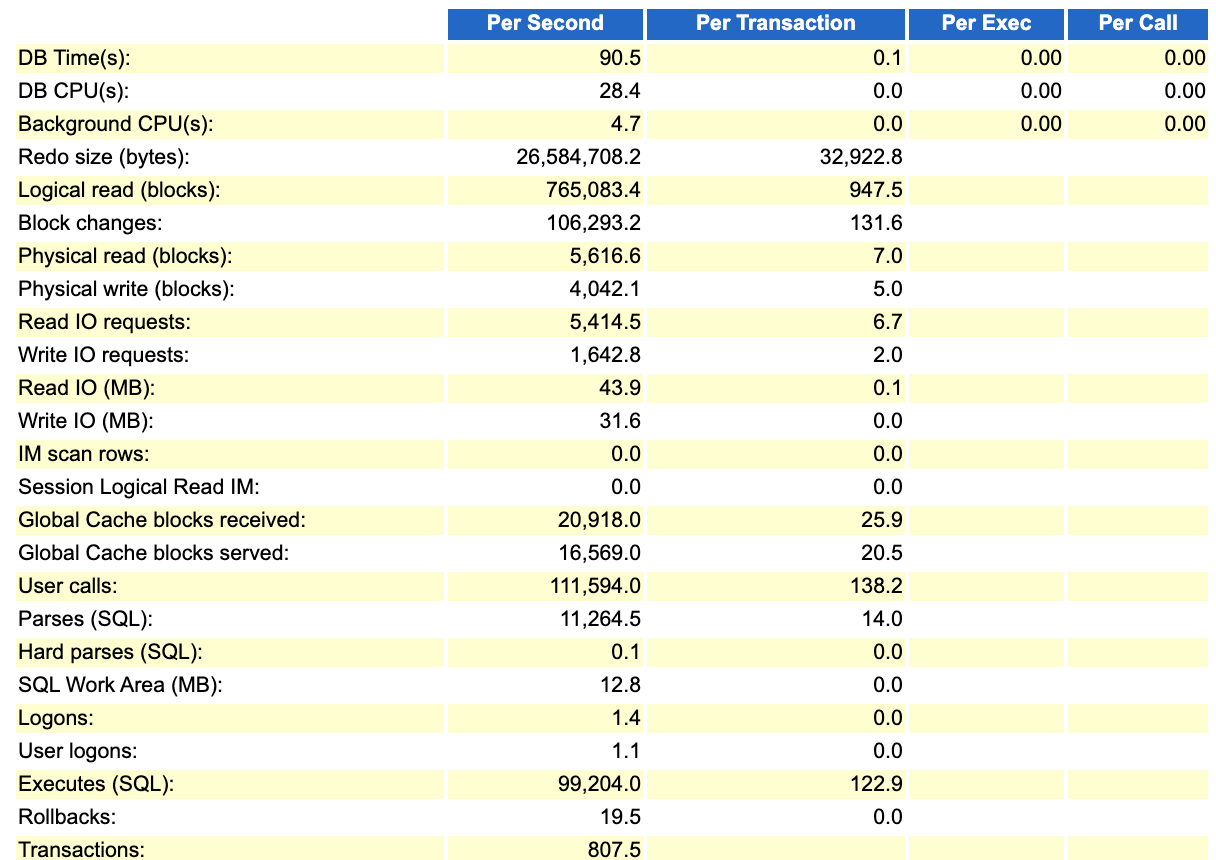
另外一个节点数据差不多,就不再贴了。从单节点的数据来看,每秒redo 高达25MB,sql execute 接近10万,其中每秒的block changes大概是10.6万(单节点)。
此时的top event如下(群友反馈是跑批较快):
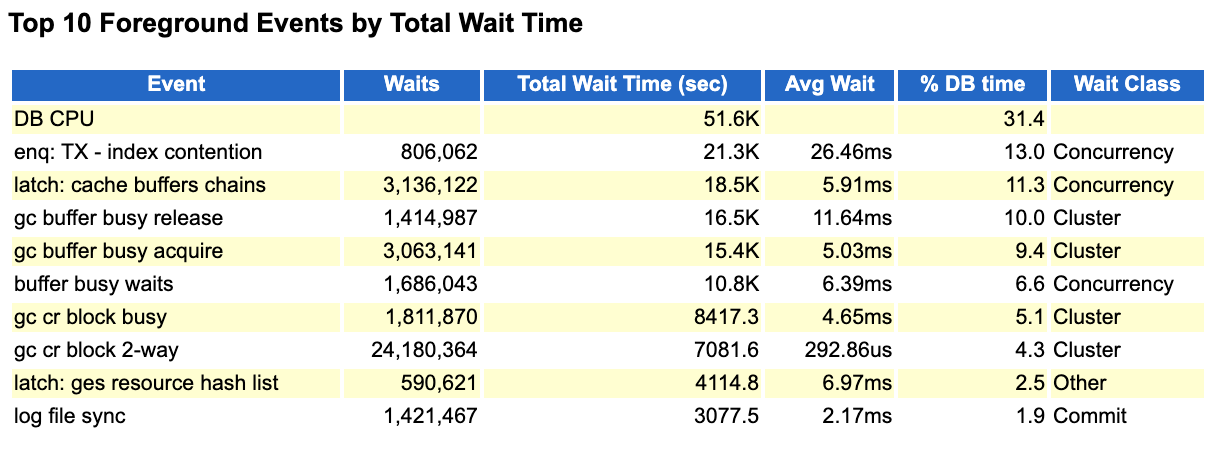
老实说,单纯的看这个top event,我甚至都有点怀疑是不是发错awr或者搞反了。从top event来看,索引分离比较严重,另外gc也是比较高的,看了下此时集群的心跳通信数据,每秒超过了300MB/s.
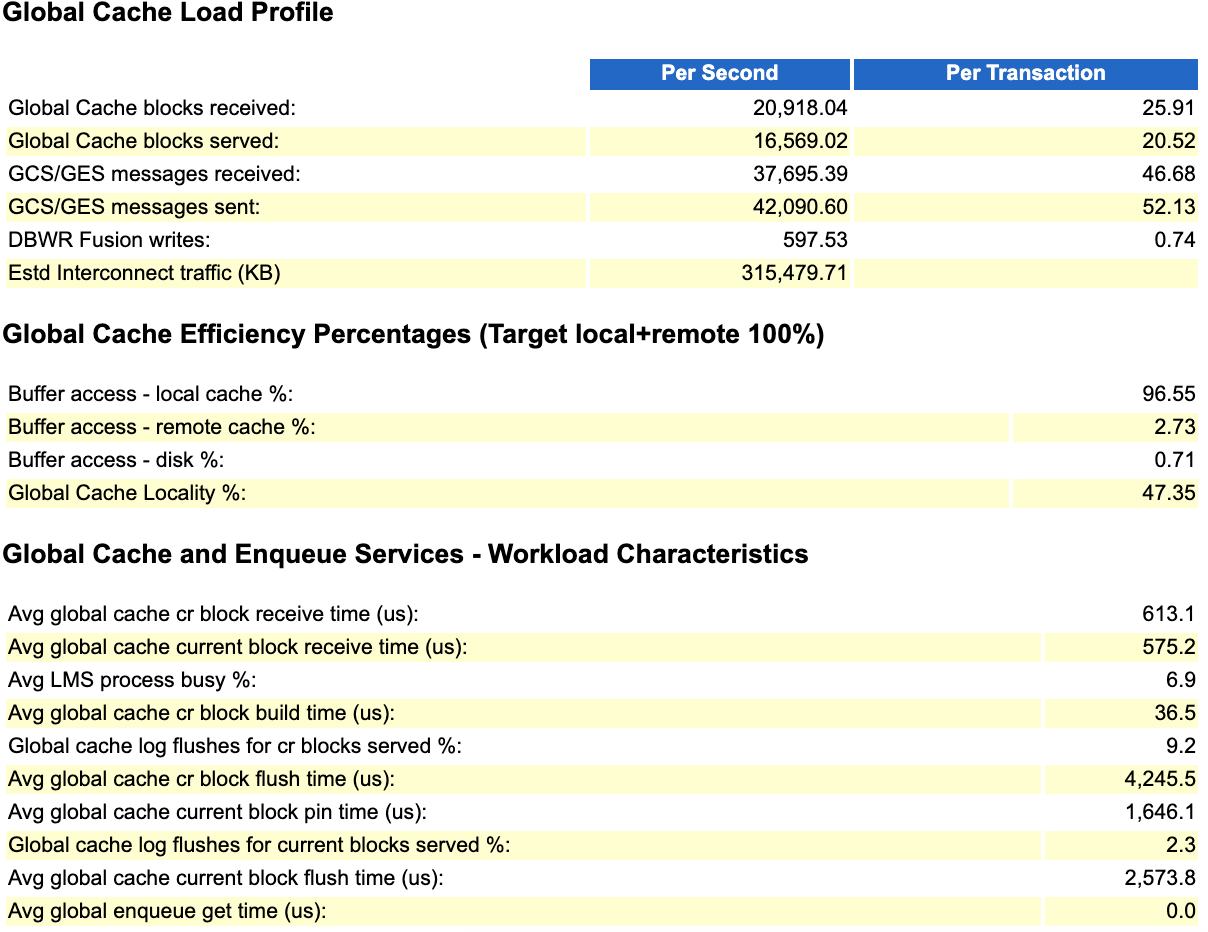
虽然群友说这个awr报告的时间段,跑批很快,但是从rac 的数据,我们可以看到,其实有几个指标还是点略高,比如Avg global cache cr block flush time,Avg global cache current block pin time,Avg global cache current block flush time。
既然上面是业务跑的快的数据。那么我们来看看跑批很慢的数据究竟是如何的。
跑批慢的性能数据
我们先来看看awr的load profile数据:
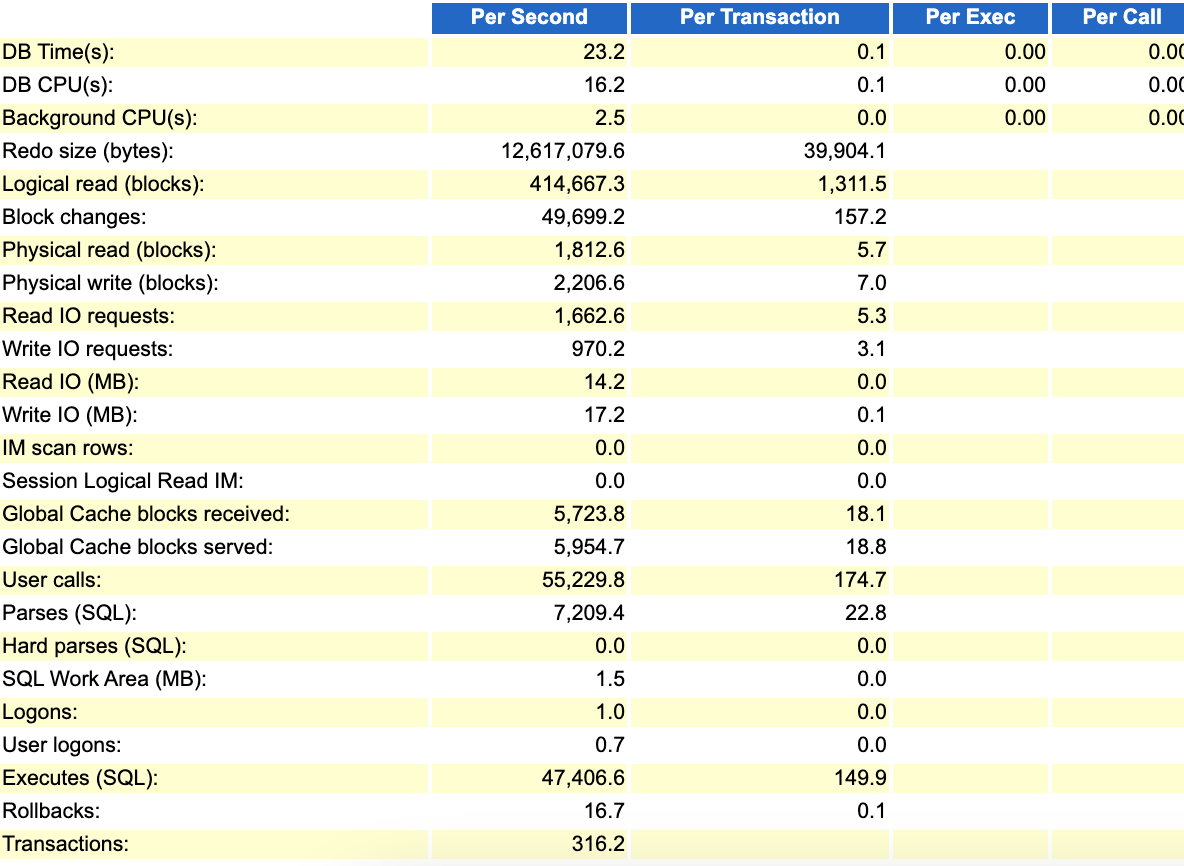
从load profile数据来看,似乎比前面正常的数据,几乎低了一倍。这也难怪说跑的慢了。
但是对比发现background 相关event的平均等待似乎都差不多: 正常:
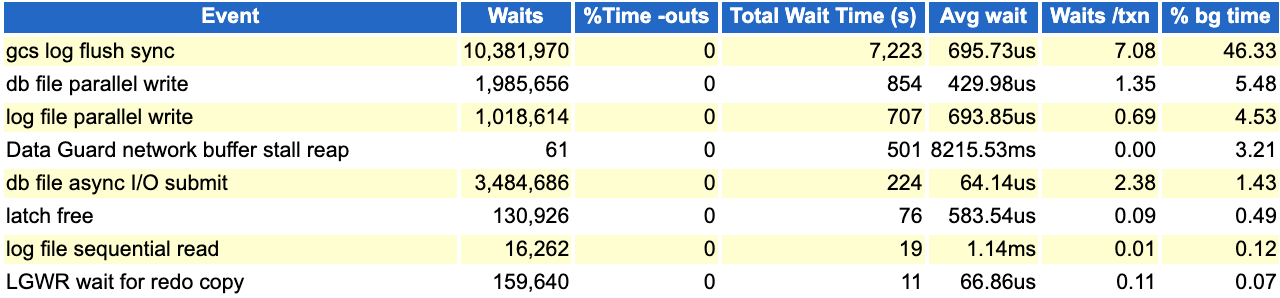
异常:
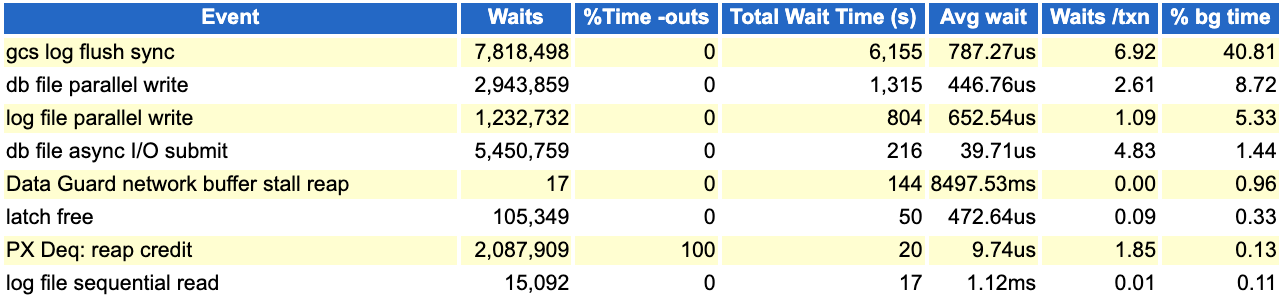
接下来我们继续看下异常时间段的ash数据:
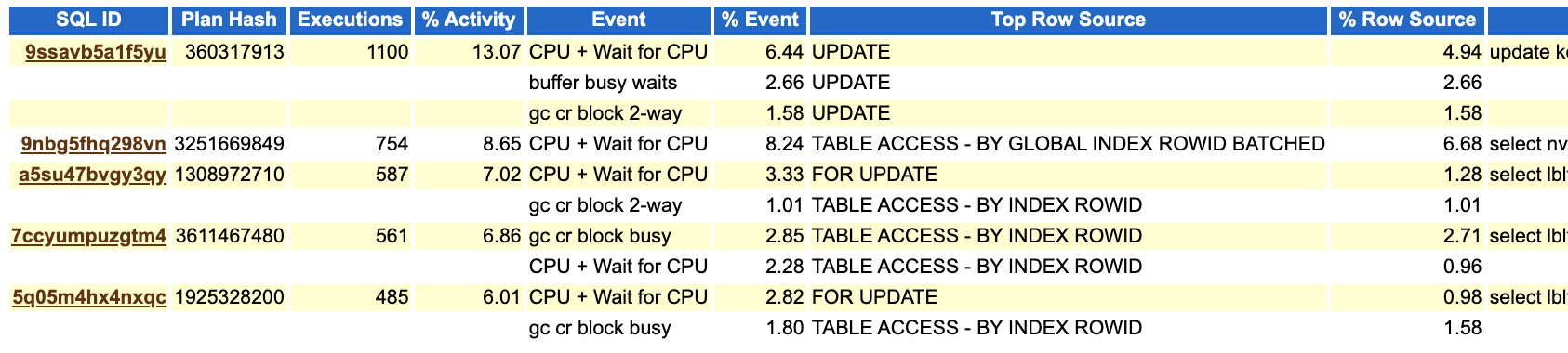
此时ash top sql对应的sql逻辑读情况:
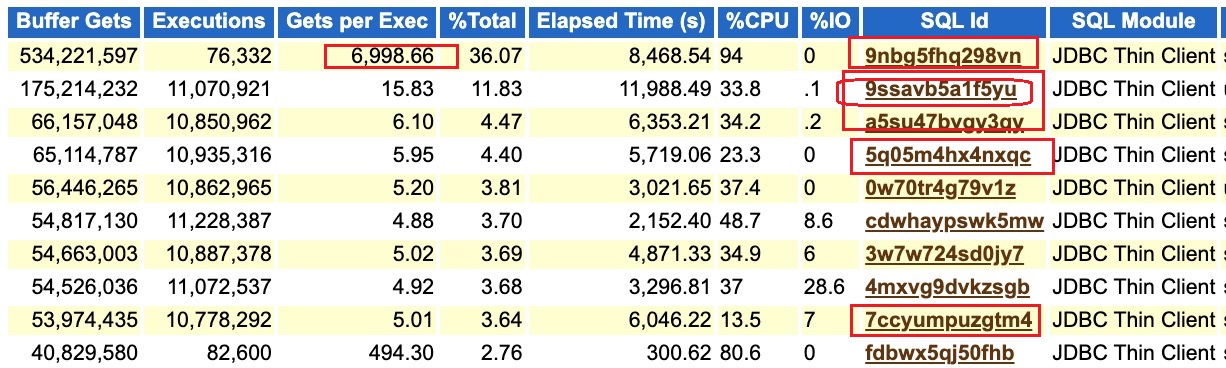
接下来我们对比下正常时间点的上述5个top sql的逻辑读情况:
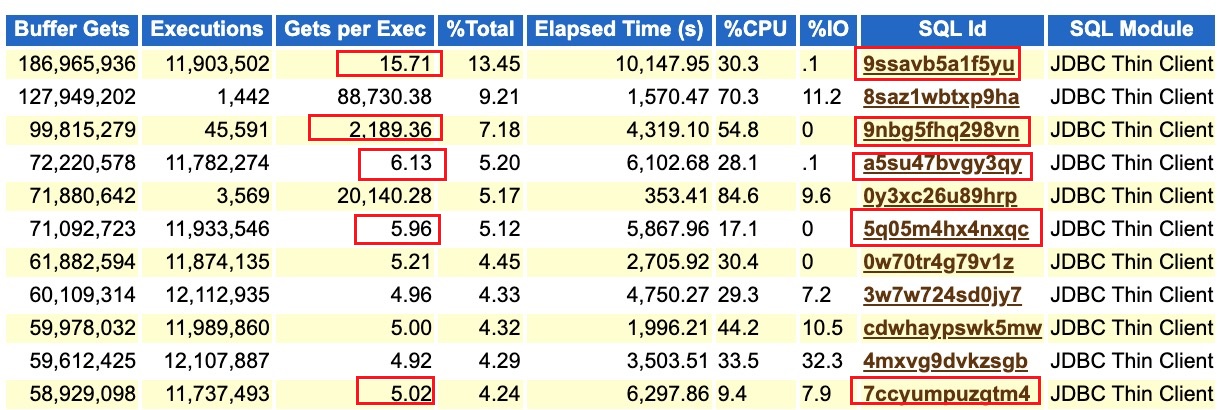
我们可以清楚的发现,其中有个关键的SQL 9nbg5fhq298vn 的平均单次执行逻辑读消耗,异常期间比正常时间段,似乎高了3倍。
那么这个sql的执行时间自然也会慢很多了。
难道就是sql问题?从ash来看该sql似乎在等gc cr block 2-way,而反馈正常情况的awr中,是无这个等待的。
gc cr block 2-way 是什么呢?简单的讲就是,实例1以共享模式请求CR块和锁,主控实例拥有当前块,制作CR副本并通过缓存融合发送,该事件表明存在写/读争用。
实际上就rac的使用实践来讲,对于跑批业务,建议固定在单个节点跑。而群友这里很显然是2个阶段随机负载均衡的处理。
为什么传统架构跑Oracle rac 不建议使用随机负载均衡的模式?主要愿意还是在于集群心跳通信会是一个较大的问题,就算使用万兆交换机,那么其实通讯延迟仍然是较高的。
在群聊的过程中,我给大家推了zData 高性能一体机,现在zData一体机客户基本上使用交换机都是100GB、200GB了。
我们曾经某超大型客户的4+5 zData一体机节点,Oracle RAC心跳每秒流量最高达到3GB/s,业务仍然跑的起飞。
如果有兴趣的朋友可以了解一下:
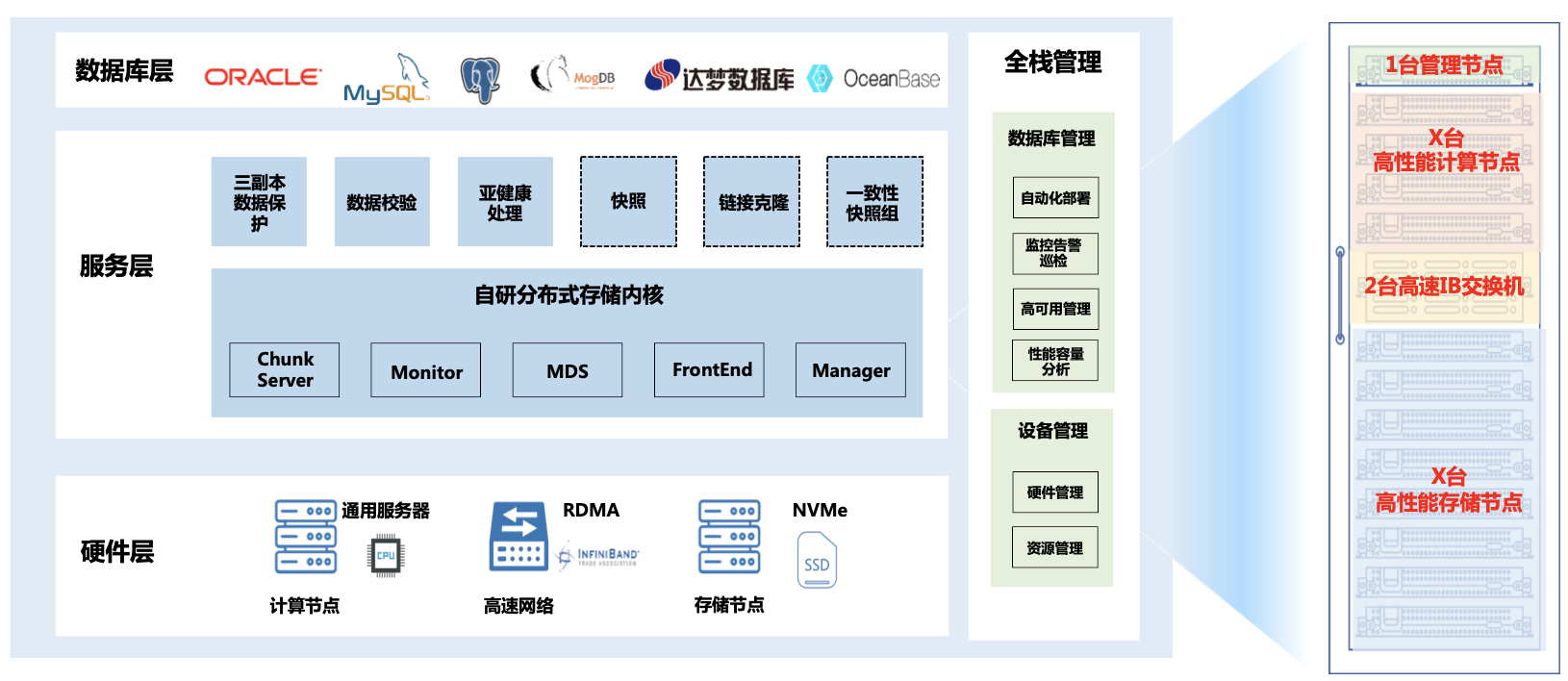
不仅支持Oracle等商业数据库还支持主流的过程数据库,简直不要太香,至于性能,目前单个存储节点达到了100万IOPS。
再回到这个案例中来,其实看正常时间段的awr中的ash数据,我们可以看到仍然有一定的优化空间:
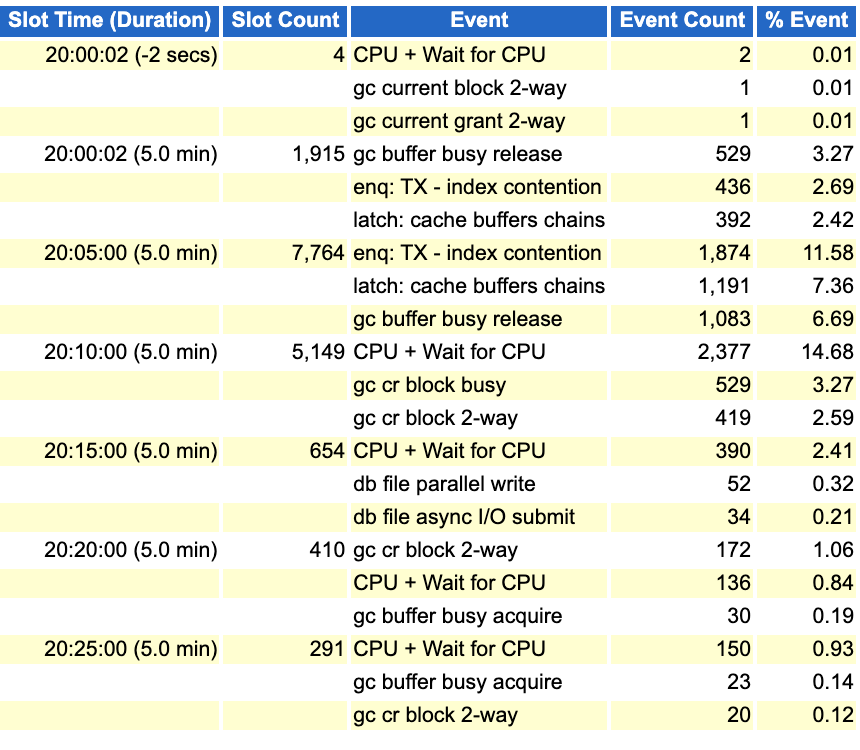
可以清楚都看到,索引分离影响的时间接近10分钟。但从这个数据来看,如果能优化索引分离和cbc,跑批应该还能再缩短5分钟以上。
另外如果细心的网友也会发现,这个系统单节点Redo超过25MB/s,2个节点之和超过50MB/s. 这对于容灾环境来讲也是很有压力的。
据网友反馈,业务高峰期这个数据可能会更高。那么对于这种超高日志量的系统来讲,主备的压力也是非常大的。
就拿目前主流国产数据库某梦来讲,其rac肯定是抗不住这样的业务量的,如果是主备架构,老实说,每秒可能接近100MB/s的日志产生,standby同步能否跟得上也是一个很大的问题。
就我了解的openGauss数据库来讲,目前主备同步极限应该是在70MB/s左右。
从这些大型系统的负载来看,国产数据库还有相当长的一段时间要走,可能通过zData一体机+国产数据库的形式,是一个相对较好的支撑方案,通过硬件来弥补软件层的不足。
本文由 mdnice 多平台发布















 6905
6905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









