









爬取一个网站的基本过程
- 确定目标 –> 分析目标 –> 编写程序 -> 执行爬虫
分析目标:
url 格式 数据格式 网页编码分析目标数据在源代码里的结构,以便在获取整个页面源代码后,可以利用正则进行匹配。
注意:目标网站的格式会随时升级,定向爬虫也需要定期升级。
实例:爬取某代理Ip网站上的所有ip
确定目标:
- 爬取西刺代理上存活一年以上的高匿代理IP

分析目标

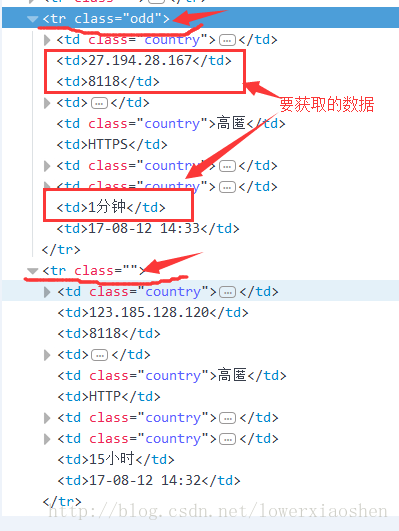
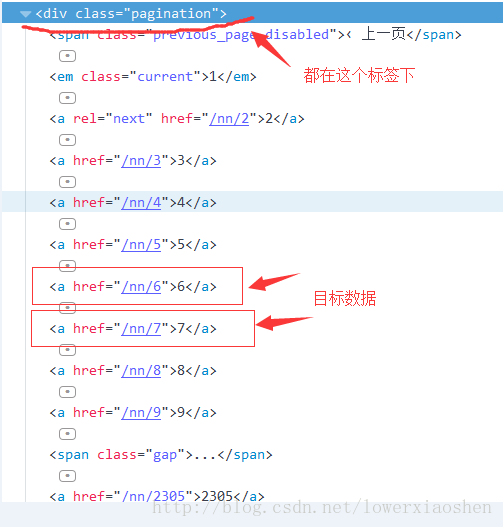

根据上面分析可以确定两个正则表达式
- 获取目标数据:
re.compile(r'(\d+\.\d+\.\d+\.\d+).*?<td>(\d{2,4})</td>.*?<td>(\d+.*?)</td>',re.M|re.S) - 获取新的url:
re.compile(r'<a.*?href="(/nn/\d+)">\d{1,4}</a>',re.M|re.S)
编写程序
- 如果你得编程能力很强,那么倒是可以直接入手编写程序。但是作为我还差的远,所以在编写程序之前就把代码架构在脑海中过一遍,画一个流程图。以便编写程序时有一个清楚的思路。同时这也是一个很好的习惯。
- 代码结构:
HttpMain.py ---主文件
class Htma()
def beganCrawl() 主程序
if __name__ == '__main__': 程序执行入口
HttpSourceCode.py ---获取源代码文件
class Souco()
def sent() 请求连接函数
HttpAnalyze.py ---分析源代码文件
class Anurl()
def getInfor() 分析获取url和目标数据
HttpHandleUrl.py ---处理新的url文件
class Hanur()
def takeOutUrl() 获取url方法
def gainUrls() 保存url方法
HttpSaveFile.py ---保存数据文件
class Safi()
def dataNotNone() 保存一个网页上的目标数据
def outputer() 把全部目标数据写入文件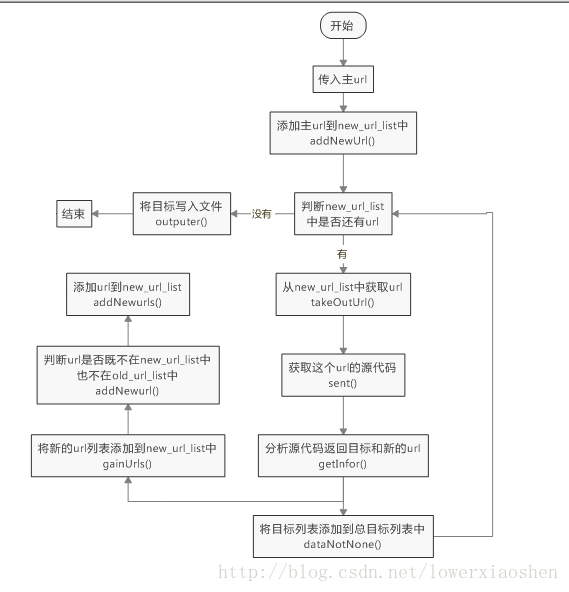
- 程序
HttpMain.py —主文件—主文件
#!/usr/bin/env python
# encoding: utf-8
'''
writer:lxshen
date:2017-8-13
E-mail:guanghui2017@outlook.com
'''
from reprile_IP import HttpSourceCode,HttpHandleUrl,HttpAnalyze,HttpSaveFile
class Htma(object):
def __init__(self):
self.sourceCode = HttpSourceCode.Souco() #下载源代码
self.analyze = HttpAnalyze.Anurl() # 分析源代码
self.handleUrl = HttpHandleUrl.Hanur() #处理新的url
self.saveFile = HttpSaveFile.Safi() #保存信息到文件
def beganCrawl(self,new_url):
count = 1
#把主url添加到new_url中去
self.handleUrl.addNewUrl(new_url)
#判断 new_url_lsit 列表中是否存还存在url
while self.handleUrl.new_url_list:
#从new_url_lsit列表中获取一个url
new_url = self.handleUrl.takeOutUrl()
print u'开始爬取第%d个:%s' %(count,new_url)
#把这个url传入到获取请求函数中,并把源代码返回
html_code = self.sourceCode.sent(new_url)
#把源代码传入分析源代码函数中,并把返回新获取的url和主要信息
new_urls,new_data = self.analyze.getInfor(html_code)
# print new_data
# print new_urls
#把new_urls列表添加到 new_url_lsit 中去
#把new_date列表传入到写入文件函数中
self.handleUrl.gainUrls(new_urls)
self.saveFile.dateNotNone(new_data)
if count == 20:break
count += 1
self.saveFile.outputer()
if __name__ == '__main__':
rootUrl = 'http://www.xicidaili.com/nn/1'
hm = Htma()
hm.beganCrawl(rootUrl)HttpSourceCode.py —获取源代码文件
#!/usr/bin/env python
# encoding: utf-8
'''
writer:lxshen
date:2017-8-13
E-mail:guanghui2017@outlook.com
'''
import urllib2
class Souco(object):
def sent(self, new_url):
if new_url is None:
return None
#获取一个User-Agent
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) '
'Gecko/20100101 Firefox/54.0',
}
#获取request请求对象
request = urllib2.Request(new_url,headers = headers)
try:
# 创建对象
response = urllib2.urlopen(request)
if response.getcode() !=200:
return None
return response.read()
except:
print u'获取网站源代码失败'HttpAnalyze.py —分析源代码文件
#!/usr/bin/env python
# encoding: utf-8
'''
writer:lxshen
date:2017-8-13
E-mail:guanghui2017@outlook.com
'''
import re,urllib2
from reprile_IP import HttpSourceCode
class Anurl(object):
def getInfor(self, html_code):
try:
findInforList = self.getInforCompile().findall(html_code)
inforList = self.filtrationInfor(findInforList)
findUrlList = self.getUrlCompile().findall(html_code)
urlList = self.filtrationUrl(findUrlList)
return urlList, inforList
except:
print u'从源代码中匹配信息失败'
def getInforCompile(self):
inforCom = re.compile(r'(\d+\.\d+\.\d+\.\d+).*?<td>(\d{2,4})</td>.*?<td>(\d+.*?)</td>',re.M|re.S)
return inforCom
def getUrlCompile(self):
urlCom = re.compile(r'<a.*?href="(/nn/\d+)">\d{1,4}</a>',re.M|re.S)
return urlCom
def filtrationInfor(self, findInforList):
ipList = []
for i in findInforList:
if '天' in i[2]:
if int(re.search('\d+',i[2]).group()) > 365:
ipList.append(i)
return ipList
def filtrationUrl(self, findUrlList):
urlList = []
string = 'http://www.xicidaili.com'
for url in findUrlList:
urlList.append(string+url)
return urlListHttpHandleUrl.py —处理新的url文件
#!/usr/bin/env python
# encoding: utf-8
'''
writer:lxshen
date:2017-8-13
E-mail:guanghui2017@outlook.com
'''
import random
class Hanur(object):
def __init__(self):
self.new_url_list = list()
self.old_url_list = list()
def addNewUrl(self,new_url):
if new_url is None:return
if new_url in self.new_url_list or new_url in self.old_url_list:return
self.addNewurls(new_url)
def addNewurls(self, new_url):
#把这个新的url添加到url列表中
self.new_url_list.append(new_url)
def takeOutUrl(self):
#获取一个url
if self.new_url_list is not None:
try:
new_url = random.choice(self.new_url_list)
self.new_url_list.remove(new_url)
self.old_url_list.append(new_url)
except:
print u'获取新的url失败'
else:
return new_url
def gainUrls(self, new_urls):
try:
for url in new_urls:
self.addNewUrl(url)
except:
print u'添加新的url失败'HttpSaveFile.py —保存数据文件
#!/usr/bin/env python
# encoding: utf-8
'''
writer:lxshen
date:2017-8-13
E-mail:guanghui2017@outlook.com
'''
class Safi(object):
def __init__(self):
self.datas = list()
def dateNotNone(self, new_data):
try:
for data in new_data:
if data is None:return
self.datas.append(data)
except:
print u'添加有用信息到列表失败'
def outputer(self):
with open('ip.txt','w+') as f:
for data in self.datas:
f.write('%3s:%s' % (data[0],data[1]))
f.write('%20s' % data[2])
f.write('\n')执行程序

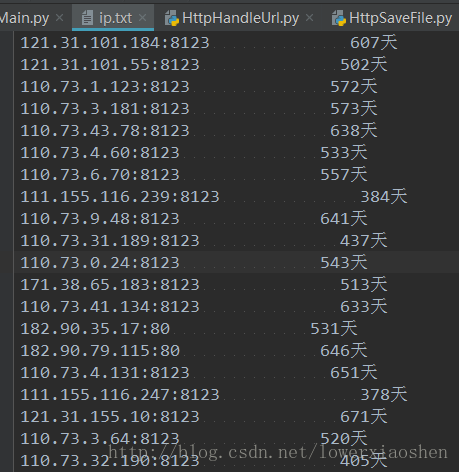
执行非常完美。
总结
在编写这个程序时,遇到最大的问题就是用正则表达式匹配网站上的信息。不得已又把正则过了一遍。又了解到了flag参数(I,M…),总之满满的收获。















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









