







线性回归
一、单变量线性回归
1. 假设函数(Hypothesis Function)
因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题: h θ ( x ) = θ 0 + θ 1 x h_\theta(x) = \theta_0 + \theta_1x hθ(x)=θ0+θ1x
假设有以下的训练集, 我们假设 θ 0 = 2 θ_0=2 θ0=2 和 θ 1 = 2 θ_1=2 θ1=2, 则假设函数为 y = 2 + 2 x y=2+2x y=2+2x. 当x=1时, y=4.
2.代价函数(Cost Function)
为模型选择合适的参数 θ 0 θ_0 θ0 和 θ 1 θ_1 θ1。我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数,
使得代价函数最小: J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( \theta_0, \theta_1 \right) = \frac{1}{2m}\sum\limits_{i=1}^m \left( h_{\theta}(x^{(i)})-y^{(i)} \right)^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。求出 θ 0 θ_0 θ0 和 θ 1 θ_1 θ1使得假设函数尽可能多的通过训练集,需要指出的是当 J ( θ 0 , θ 1 ) = 0 J(θ_0,θ_1)=0 J(θ0,θ1)=0时, 我们的假设函数应该通过所有的训练集。
E.G. 我们通过下训练集, 来学习如何计算J(θ):
- x = 1, y = 1
- x = 2, y = 2
- x = 3, y = 3
当 θ 0 θ_0 θ0=0时: J ( θ 0 ) = 1 2 ∗ 3 ∗ ( 1 2 + 2 2 + 3 3 ) = 14 6 J{(\theta_0)} = \frac{1}{2*3}*(1^2+2^2+3^3)=\frac{14}{6} J(θ0)=2∗31∗(12+22+33)=614
3. 梯度下降(Gradient Descent)
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 J ( θ 0 , θ 1 ) J(θ_0,θ_1) J(θ0,θ1) 的最小值。
梯度下降背后的思想是:开始时我们随机选择一个参数的组合 θ 0 , θ 1 . . . θ n θ_0,θ_1 ... θ_n θ0,θ1...θn ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到找到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。

批量梯度下降公式(batch gradient descent): θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) θ_j := θ_j−α\frac{∂}{∂θ_j}J(θ_0,θ_1) θj:=θj−α∂θj∂J(θ0,θ1)
其中α是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。由切线可见, 随着斜率的变化,越接近最低点,切线值变化越小。当到达最低点时,切线值接近于0, 得到局部最优解。
同步更新
在梯度下降算法中,需要注意同步更新,即梯度下降中,更新J(θ0)和J(θ1) 时,需要同时更新θ0和θ1
4. 线性回归运用梯度下降
对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即: ∂ ∂ θ j J ( θ 0 , θ 1 ) = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \frac{\partial }{\partial {{\theta }_{j}}}J({{\theta }_{0}},{{\theta }_{1}})=\frac{\partial }{\partial {{\theta }_{j}}}\frac{1}{2m}{{\sum\limits_{i=1}^{m}{\left( {{h}_{\theta }}({{x}^{(i)}})-{{y}^{(i)}} \right)}}^{2}} ∂θj∂J(θ0,θ1)=∂θj∂2m1i=1∑m(hθ(x(i))−y(i))2
代入计算可得: θ 0 : = θ 0 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) {\theta_{0}}:={\theta_{0}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{\left({{h}_{\theta }}({{x}^{(i)}})-{{y}^{(i)}}\right)} θ0:=θ0−am1i=1∑m(hθ(x(i))−y(i)) 以及: θ 1 : = θ 1 − a 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) ) {\theta_{1}}:={\theta_{1}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{\left(\left({{h}_{\theta }}({{x}^{(i)}})-{{y}^{(i)}} \right)\cdot {{x}^{(i)}} \right)} θ1:=θ1−am1i=1∑m((hθ(x(i))−y(i))⋅x(i))
二、多变量线性回归
目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为 x 1 , x 2 . . . x n x_1,x_2 ... x_n x1,x2...xn
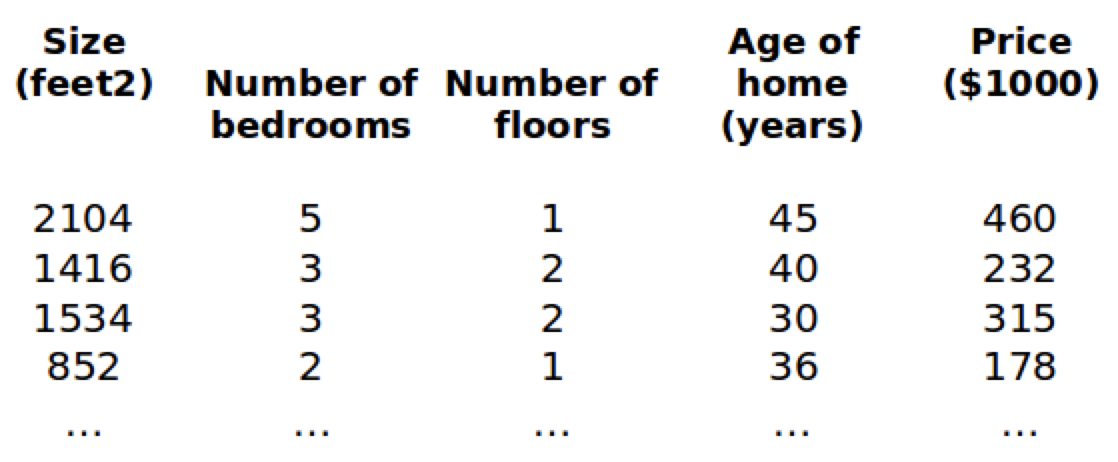
增添更多特征后,我们引入一系列新的注释:
- n 代表特征的数量
- x i x^i xi代表第 i 个训练实例,是特征矩阵中的第i行,是一个向量(vector)
- x j i x_j^i xji代表特征矩阵中第 i 行的第 j 个特征,也就是第 i 个训练实例的第 j 个特征。如上图的 x 2 2 = 3 x_2^2=3 x22=3 , x 3 2 = 2 x_3^2=2 x32=2
一、假设函数
支持多变量的假设 h , 为了使得公式能够简化一些,引入 x 0 x_0 x0 =1,此时模型中的参数是一个n+1维的向量,任何一个训练实例也都是n+1维的向量,特征矩阵X的维度是 m(n+1): h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ _ n x n = θ T X h_{\theta} \left( x \right)={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta\_{n}}{x_{n}}={\theta^{T}}X hθ(x)=θ0x0+θ1x1+θ2x2+...+θ_nxn=θTX
二、多变量梯度下降
与单变量线性回归类似,在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:
J ( θ 0 , θ 1 . . . θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J\left( {\theta_{0}},{\theta_{1}}...{\theta_{n}} \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} J(θ0,θ1...θn)=2m1i=1∑m(hθ(x(i))−y(i))2
我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。 多变量线性回归的批量梯度下降算法为:
θ j : = θ j − α 1 2 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) ) \theta_j := \theta_j−α\frac{1}{2m}\sum\limits_{i=1}^{m}{(({{h}{\theta }}({{x}^{(i)}})-{{y}^{(i)}})}x_{j}^{(i)}) θj:=θj−α2m1i=1∑m((hθ(x(i))−y(i))xj(i))
三、正规方程
正规方程是通过求导,使得导数为0来找出得代价函数最小的参数。假设我们的训练集特征矩阵为 X(包含了 x 0 x_0 x0 =1)并且我们的训练集结果为向量 y,则利用正规方程解出向量 : θ = ( X T X ) − 1 X T y \theta ={{\left( {X^T}X \right)}^{-1}}{X^{T}}y θ=(XTX)−1XTy
可以得到矩阵为:
X = [ ( x ( 1 ) ) T ( x ( 2 ) ) T . . . ( x ( m ) ) T ] = [ 1 2104 5 1 45 1 1416 3 2 40 1 1534 3 2 30 1 852 2 1 36 ] X = \begin{bmatrix} (x^{(1)})^T \\ (x^{(2)})^T \\ ... \\ (x^{(m)})^T \end{bmatrix} = \begin{bmatrix} 1 & 2104 & 5 & 1 & 45 \\1 & 1416 & 3 & 2 & 40 \\ 1 & 1534 & 3 & 2 & 30 \\ 1 & 852 & 2 & 1 & 36 \\ \end{bmatrix} X=⎣⎢⎢⎡(x(1))T(x(2))T...(x(m))T⎦⎥⎥⎤=⎣⎢⎢⎡11112104141615348525332122145403036⎦⎥⎥⎤















 7741
7741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









