



文章目录
- Golang面试题总结
- 一、基础知识
- 1、defer相关
- 2、rune 类型
- 3、context包
- 4、Go 竞态、内存逃逸分析
- 5、Goroutine 和线程的区别
- 6、Go 里面并发安全的数据类型
- 7、Go 中常用的并发模型
- 8、Go 中安全读写共享变量方式
- 9、Go 面向对象是如何实现的
- 10、make 和 new 的区别
- 11、Go 关闭(退出) goroutine 的方式
- 12、Gorm更新空值问题
- 13、Go语言优势和缺点
- 14、Go 为什么要使用协程?
- 15、内存对齐
- 16、反射
- 17、go中一个地址占多少位?
- 18、go 包循环引用?怎么避免?
- 19、go 闭包调用?怎么避免?
- 20、结构体比较
- 21、go 语言中的可比较类型和不可比较类型
- 22、interface 接口
- 23、空结构体 struct 应用场景
- 24、go 内存泄漏
- 25、协程泄露
- 26、值传递和地址传递(引用传递)
- 27、go 语言中栈的空间有多大?
- 28、并发情况下的数据处理,避免并发情况下数据竞争问题?
- 29、init() 函数是什么时候执行的?
- 二、channel 通道
- 三、map 哈希表
- 四、slice 切片
Golang面试题总结
一、基础知识
1、defer相关
defer是Go语言中的一个关键字,延迟调用。
-
作用
释放资源、释放锁、关闭文件、关闭链接、捕获panic等收尾工作。 -
执行顺序
多个 defer 调用顺序是 LIFO(后入先出),defer后的操作可以理解为压入栈中,函数参数会被拷⻉下来。
defer声明时,对应的参数会实时解析。
defer、return、返回值三者的执行逻辑:return最先执行,return负责将结果写入返回值中;接着defer开始执行一些收尾工作;最后函数携带当前返回值(可能和最初的返回值不相同)退出。
defer与panic的执行逻辑:在panic语句后面的defer语句不被执行,在panic语句前的defer语句会被执行(早于panic),panic触发defer出栈。可以在defer中使用recover捕获异常,panic 后依然有效。panic仅有最后一个可以被revover捕获。 -
defer与recover
recover(异常捕获)可以让程序在引发panic的时候不会崩溃退出。在引发panic的时候,panic会停掉当前正在执⾏的程序,但是,在这之前,它会有序的执⾏完当前goroutine的defer列表中的语句。
我们通常在defer⾥⾯挂⼀个recover,防⽌程序直接挂掉,类似于try…catch,但绝对不能像try…catch这样使⽤,因为panic的作⽤不是为了捕获异常。recover函数只在defer的上下⽂中才有效,如果直接调⽤recover,会返回nil。
recover不能跨协程捕获panic信息。recover只能恢复同一个协程中的panic,所以必须与可能发生panic的协程在同一个协程中才生效。panic在子协程中,而recover在主协程中,最终会导致所有的协程全部挂掉,程序会整体退出。 -
defer可以修改函数最终返回值
修改时机:有名返回值或者函数返回指针。
无名返回(返回值没有指定命名),执行Return语句后,Go会创建一个临时变量保存返回值,defer修改的是临时变量,没有修改返回值。
有名返回(指定返回值命名func test() (t int)),执行 return 语句时,并不会再创建临时变量保存,defer修改的是返回值。
函数返回值为指针,指向变量所在的地址,defer修改变量,指针指向的地址不变,地址对应的内容发生了改变,返回值改变。
特殊例子:defer没有修改有名返回值,因为 r 作为参数,传入defer 内部时会发生值拷贝,地址会变,defer修改的是新地址的变量,不是原来的返回值。
func f() (r int) {
defer func(r int) {
r = r + 5
}(r)
return r
}
//0
为什么defer要按照定义的顺序逆序执行?
后⾯定义的函数可能会依赖前⾯的资源,所以要先执⾏。如果前⾯先执⾏,释放掉这个依赖,那后⾯的函数就找不到它的依赖了。
3、defer函数定义时,对外部变量的引⽤⽅式有两种
分别是函数参数以及作为闭包引⽤。
在作为函数参数的时候,在defer定义时就把值传递给defer,并被缓存起来。
如果是作为闭包引⽤,则会在defer真正调⽤的时候,根据整个上下⽂去确定当前的值。
4、defer后⾯的语句在执⾏的时候,函数调⽤的参数会被保存起来,也就是复制。在真正执⾏的时候,实际上⽤到的是复制的变量,也就是说,如果这个变量是⼀个"值类型",那他就和定义的时候是⼀致的,如果是⼀个"引⽤",那么就可能和定义的时候的值不⼀致。
2、rune 类型
Go语言的字符有以下两种:
- byte 等同于uint8,常用来处理 ASCII 码;
- rune 等同于int32,常用来处理 unicode 或 utf-8 字符。当需要处理中文、日文或者其他复合字符时,使用 rune 类型。
在 Go 语言中,字符串默认使用 UTF-8 编码,UTF8 的好处在于,如果基本是英文,每个字符占 1 byte,和 ASCII 编码是一样的,非常节省空间,如果是中文,一般占3字节。中文字符在unicode下占2个字节,在utf-8编码下占3个字节。
在Go中,字符串是以UTF-8编码格式进行存储的。在UTF-8编码中,一个汉字通常占用24位(3字节)。英文字符(包括英文标点)通常占用8位(1字节)1个字节。
字符串的底层表示是 byte (8 bit) 序列,而非 rune (32 bit) 序列。包含中文的字符串,正确的处理方式是将 string 转为 rune 数组,转换成 []rune 类型后,字符串中的每个字符,无论占多少个字节都用 int32 来表示,因而可以正确处理中文。
func main() {
str := "我爱GO"
fmt.Println(reflect.TypeOf(str[0]).Kind()) //uint8
fmt.Println(len(str)) //8
runeStr := []rune(str)
runeStr[0] = '你'
fmt.Println(reflect.TypeOf(runeStr[0]).Kind()) //int32
fmt.Println(string(runeStr)) //你爱GO
fmt.Println(len(runeStr)) //4
}
// reflect.TypeOf().Kind() 可以知道某个变量的类型
3、context包
context是Golang常用的并发控制技术,context的作用就是在不同的goroutine之间同步请求特定的数据、取消信号以及处理请求的截止日期(设置超时时间)。目前我们常用的一些库都是支持context的,例如gin、database/sql等库都是支持context的,这样更方便我们做并发控制了,只要在服务器入口创建一个context上下文,不断透传下去即可。
context可以用来在goroutine之间传递上下文信息,相同的context可以传递给运行在不同goroutine中的函数,上下文对于多个goroutine同时使用是安全的,它与WaitGroup最大的不同点是context对于派生goroutine有更强的控制力,它可以控制多级的goroutine。
context包定义了上下文类型,可以使用context.Background()、context.TODO()创建一个上下文,也可以使用WithDeadline()、WithTimeout()、WithCancel() 或 WithValue() 创建。
Go 的 Context 的数据结构包含 Deadline(),Done(),Err(),Value()方法:
- Deadline() 方法返回一个time.Time和一个bool值。time.Time表示此上下文被取消的时间,也就是完成工作的截至日期。布尔值表示是否设置截止日期,当没有设置截止日期时,bool值返回ok==false,此时截止日期为一个初始值的time.Time值。对Deadline的连续调用返回相同的结果。
- Done() 方法返回一个channel。 这个 Channel 会在当前工作完成或者context 被取消之后关闭,告诉给 context 相关的函数要停止当前工作然后返回了。对Done的连续调用返回相同的值。需要在select-case语句中使用,如”case <-context.Done():”。当context关闭后,Done()返回一个被关闭的管道,关闭的管道仍然是可读的,据此goroutine可以收到关闭请求;当context还未关闭时,Done()返回nil。
- Err() 方法返回一个error。表示 context 被关闭的原因,关闭原因由context实现控制,不需要用户设置。当context关闭后,Err()返回context的关闭原因;当context还未关闭时,Err()返回nil。Context 被取消,返回 “context canceled” 错误;超时,返回“context deadline exceeded”错误。
- Value() 方法,参数为key,返回 Context 中 key 对应的值,如果没有值与键相关联,返回nil。对于同一个 Context 来说,多次调用Value() 并传入相同的Key,会返回相同的结果,这个功能可以用来传递特定的数据。
4、Go 竞态、内存逃逸分析
竞态:资源竞争,就是在程序中,同一块内存同时被多个 goroutine 访问。我们使用 go build、go run、go test 命令时,可以添加 -race 标识检查代码中是否存在资源竞争。
解决方案:给资源进行加锁,让其在同一时刻只能被一个协程来操作。
sync.Mutex
sync.RWMutex
内存逃逸分析:是go的编译器在编译期间,对代码进行分析,根据变量的类型和作用域,确定变量是分配在堆上还是栈上,如果变量需要分配在堆上,则称作内存逃逸了。简单来说,本该分配到栈上的变量,跑到了堆上,这就导致了内存逃逸。go的编译器提供了逃逸分析的工具,只需要在编译的时候加上 -gcflags=-m 就可以看到逃逸分析的结果了。
为什么需要逃逸分析?
因为go语言是自动内存管理的,也就是有GC的。开发者在写代码的时候不需要关心考虑内存释放的问题,这样编译器和go运行时(runtime)就需要准确分配和管理内存,所以编译器在编译期间要确定变量是放在堆空间和栈空间。
栈是高地址到低地址,栈上的变量,函数结束后变量会跟着回收掉,不会有额外性能的开销。变量从栈逃逸到堆上,如果要回收掉,需要进行 gc,那么 gc 一定会带来额外的性能开销。编程语言不断优化 gc 算法,主要目的都是为了减少 gc 带来的额外性能开销,变量一旦逃逸会导致性能开销变大。
出现内存逃逸的场景:
- 指针逃逸
返回局部变量的指针、向 channel 发送指针或带有指针的数据、在 slice 或 map 中存储指针或带有指针的值。 - 动态类型逃逸
当函数传递的变量类型是 interface{} 类型的时候,因为编译器无法推断运行时变量的实际类型,所以也会发生逃逸。 - 栈空间不足逃逸
切片(扩容后)长度太大,因为栈的空间是有限的,所以在分配大块内存时,会考虑栈空间内否存下,如果栈空间存不下,会分配到堆上。 - 闭包引用对象逃逸
在闭包中引用包外的值。
5、Goroutine 和线程的区别
-
进程:进程是系统进行资源分配和调度的一个独立单位,分配完整独立的地址空间,拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程的切换只发生在内核态,由操作系统调度,进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。不同进程通过进程间通信来通信。
-
线程:是CPU调度和分派的基本单位,和其它本进程的线程共享地址空间,拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程的切换一般也由操作系统调度(标准线程是的)。 线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
-
协程:协程是一种用户态的轻量级线程,协程的调度完全由用户控制。共享堆,不共享栈。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
进程和线程的切换主要依赖于时间片的控制,而协程的切换则主要依赖于自身。
goroutine是非常轻量级的,它就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈(在64位机器上,初始化大小为2KB,最大为1GB,会随着程序的执行自动增长删除),所以它非常廉价,我们可以很轻松的创建上万个goroutine。
在 go 语言中,每个 goroutine 默认使用比较小的栈空间(通常只有几 kb),用于保存其执行状态、临时变量等数据。如果需要更大的栈空间,则会动态地进行扩容,最终实现在堆上分配内存,并将原来的栈数据复制到新的堆内存位置中。
因此,可以说 goroutine 在创建时先分配在栈上,当弹出栈无法满足内存需求时,将重新分配在堆上。但从整体上看,go 运行时负责管理所有 goroutine 的内存分配,具体实现方式对于开发者来说可能并不透明或关键。
6、Go 里面并发安全的数据类型
(1)由一条机器指令完成赋值的类型并发赋值是安全的,这些类型有:字节型,布尔型、整型、浮点型、字符型、指针、函数。
(2)数组由一个或多个元素组成,大部分情况并发不安全。注意:当位宽不大于 64 位且是 2 的整数次幂(8,16,32,64),那么其并发赋值是安全的。
(3)struct 或底层是 struct 的类型并发赋值大部分情况并发不安全,这些类型有:复数、字符串、 数组、切片 slice、字典 map、接口 interface。
注意:当 struct 赋值时退化为单个字段由一个机器指令完成赋值时,并发赋值又是安全的。这种情况有:
(a)实部或虚部相同的复数的并发赋值;
(b)等长字符串的并发赋值;
(c)同长度同容量切片的并发赋值;
(d)同一种具体类型不同值并发赋给接口。
7、Go 中常用的并发模型
-
通过channel通知实现并发控制
-
通过sync包中的WaitGroup实现并发控制
Goroutine是异步执行的,有的时候为了防止在结束mian函数的时候结束掉Goroutine,所以需要同步等待,这个时候就需要用 WaitGroup了,在 sync 包中,提供了 WaitGroup ,它会等待它收集的所有 goroutine 任务全部完成。在WaitGroup里主要有三个方法:Add()可以添加或减少 goroutine的数量,Done()相当于Add(-1),Wait()执行后会堵塞主线程,直到WaitGroup 里的值减至0。
在主 goroutine 中 Add(delta int) 索要等待goroutine 的数量,在每一个 goroutine 完成后 Done() 表示这一个goroutine 已经完成,当所有的 goroutine 都完成后,在主 goroutine 中 WaitGroup 返回返回。 -
在Go 1.7 以后引进的强大的Context上下文,实现并发控制
8、Go 中安全读写共享变量方式
go中除了加Mutex锁以外还有哪些方式安全读写共享变量?
go 中 Goroutine 可以通过 Channel 进行安全读写共享变量,而且官网建议使用这种方式,此方式的并发是由官方进行保证的。
map
在并发情况下,只读是线程安全的,同时读写是线程不安全的。
1、在写操作的时候增加锁
2、sync.Map包
数组
指定索引进行读写时,数组是支持并发读写索引区的数据的,但是索引区的数据在并发时会被覆盖的;
1、加锁
2、控制并发顺序
切片
指定索引进行读写:是支持并发读写索引区的数据的,但是索引区的数据在并发时可能会被覆盖的;
发生切片动态扩容:并发场景下扩容可能会被覆盖。
1、加互斥锁
2、使用channel串行化操作
3、使用sync.map代替切片
9、Go 面向对象是如何实现的
Go实现面向对象的两个关键是struct和interface。
封装:对于同一个包,对象对包内的文件可见;对不同的包,需要将对象以大写字母开头才是可见的。
继承:继承是编译时特征,go语言通过结构体组合来实现继承,在struct内加入所需要继承的类即可。Go支持多重继承,就是在类型中嵌入所有必要的父类型。
type A struct{}
type B struct{
A
}
多态:多态是运行时特征,Go多态通过interface来实现。类型和接口是松耦合的,某个类型的实例可以赋给它所实现的任意接口类型的变量。
10、make 和 new 的区别
-
相同点:
(1)都是给变量分配内存;
(2)都是在堆上分配内存。 -
不同点:
(1)作用变量类型不同,new给string,int和数组分配内存,make给切片,map,channel分配内存;
(2)返回类型不一样,new返回指向变量的指针,make返回变量本身;
(3)new 分配的空间被清零,make 分配空间后,会进行初始化;
11、Go 关闭(退出) goroutine 的方式
- 向退出通道发送退出信号(退出一个 goroutine)
- 关闭退出通道(退出多个 goroutine)
- 使用 context.WithCancel() 方法,手动调用 cancel() 方法退出 goroutine
- 使用 context.WithTimeout() 方法,手动调用 cancel() 方法,在超时之前退出 goroutine
- 使用 context.WithDeadLine() 方法,在指定的时间退出 goroutine
12、Gorm更新空值问题
问题:在使用gorm将一个字段更新为空的时候,发现并不生效?
原因:通过 struct 结构体变量更新字段值,gorm 会忽略零值字段,如果更新后的值为0, nil, “”, false,就不会更新该字段,而是只更新非空的其他字段。
解决方案:
(1)使用 map 类型替代 struct 结构体,更新传值的时候通过 map 来指定,key为字符串,value为 interface{} 类型,方便保存任意值。
(2)采用save的方式,先take获取源数据,然后在save进行保存。
(3)修改gorm的源码包,让它支持自定义是否可以设置为空值。
13、Go语言优势和缺点
优势:
1、并发编程:Go语言天生支持并发,内置了轻量级的协程(goroutine)和通信机制(channel),使得并发编程变得非常简单。这种并发模型是Go语言最大的特点之一,也是其在网络编程、高并发处理等领域得以广泛应用的原因。
2、高效性能:Go语言使用静态编译,可以生成本地代码,且具有快速的垃圾回收机制,使得其在性能上有很好的表现。
3、简单易学:Go语言的语法简洁清晰,易于学习和理解,并且没有像C++或Java那样复杂的继承、多态等概念。
4、跨平台支持:Go语言提供了跨平台的编译工具,可以在不同操作系统和硬件上编译出可执行文件。
5、开源社区支持:Go语言拥有一个庞大的开源社区,提供了大量的第三方库和工具,可以方便地实现各种功能。
性能高、编译快、开发效率和运行效率高:Go性能与 Java 或 C++相似,比C++开发效率高,比php和python快,与Java比,更简明的类型系统,go在语法简明和类型系统设计上优于python。
丰富的标准库:Go目前已经内置了大量的库,特别是网络库非常强大。
内置强大的工具:内置了很多工具链,Go拥有强大的编译检查、严格的编码规范和完整的软件生命周期工具,具有很强的稳定性,Go提供了软件生命周期(开发、测试、部署、维护等等)的各个环节的工具,如go tool、gofmt、go test。
缺点:
1、生态系统相对不够完善:虽然Go语言拥有庞大的开源社区,但相对其他成熟的编程语言如Python和Java,其生态系统还不够完善,一些开发工具和库的支持还不够全面。
2、语言特性相对较少:为了保持简洁,Go语言在一些高级特性上牺牲了部分灵活性。例如,Go语言没有泛型、继承、异常等概念,这些限制可能会影响一些特定领域的开发。
3、不适合大型项目:虽然Go语言在小型或中型项目中表现优异,但由于其缺乏一些高级特性和完善的生态系统支持,不适合用于大型复杂项目的开发。
14、Go 为什么要使用协程?
协程是一种用户态的轻量级线程,协程的调度完全由用户控制,由于协程运行在用户态,能够大大减少上下文切换带来的开销,并且协程调度器把可运行的协程逐个调度到线程中执行,同时及时把阻塞的协程调度出线程,从而有效的避免了线程的频繁切换,达到了使用少量的线程实现高并发的效果,但是对于一个线程来说每一时刻只能运行一个协程。
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
15、内存对齐
1、什么是内存对齐?
编译器会按照特定的规则,把数据安排到合适的存储地址上,并占用合适的地址长度。每种类型的对齐值就是它的对齐边界,内存对齐要求数据存储地址以及占用的字节数都要是它的对齐边界的倍数。所以下述的int32要错开两个字节,从4开始存,却不能紧接着从2开始。
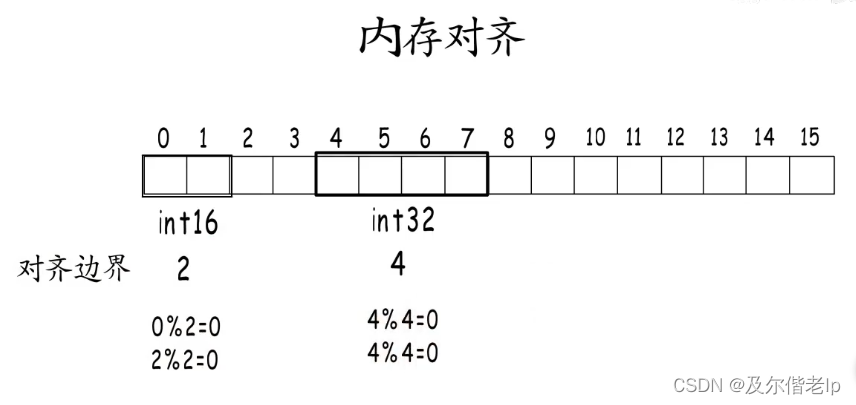
2、为什么要内存对齐?
内存对齐是为了减少CPU访问内存的次数,加大 CPU 访问内存的吞吐量,提高CPU读取内存数据的效率,可以让CPU快速从内存中读取到数据,保证程序高效的运行,避免资源浪费。如果内存不对齐,访问相同的数据需要多次的访问内存。
CPU 不会以一个字节一个字节的去读取和写入内存,CPU 读取内存是一块一块读取的,一块内存可以是2、4、8、16个字节,块大小称为内存访问粒度,内存访问粒度跟机器字长有关,32位CPU访问粒度是4个字节,64位CPU访问粒度是8个字节。
平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
3、内存对齐规则
起始的存储地址 必须是 内存对齐边界 的倍数。
整体占用字节数 必须是 内存对齐边界 的倍数。
16、反射
Go语言的反射是指在运行时动态地获取类型信息和操作对象的能力。这意味着程序可以检查变量的类型、值,以及调用它们的方法。Go语言中的反射由reflect包提供支持,包括了一些常用的函数和数据类型,如TypeOf()、ValueOf()等。使用反射可以实现一些灵活的功能,如实现通用的序列化和反序列化,或者通过动态调用方法来实现类似于插件的机制。但是需要注意的是,过度使用反射可能会影响代码的可读性和性能,因此应该谨慎使用。
17、go中一个地址占多少位?
在管理内存地址的硬件/操作系统上,Go语言中的指针通常使用64位(8字节)来表示。
18、go 包循环引用?怎么避免?
1、为什么会出现循环引用问题?怎么发现?如何避免?
程序结构没设计好,包没有规划好。
有一个项目引用可视化的工具 godepgraph,可以查看包引用的关系,生成引用图。
项目框架构建的时候,将各个模块设计好,规划好包。尝试分层的设计,高层依赖于低层,低层不依赖于高层,严格规范单向调用链,如控制层->业务层->数据层。
2、go 为什么不允许循环引用?
- 加快编译速度;
- 规范框架设计,使项目结构更加清晰明了。
3、怎么解决?
- 对于软相互依赖,利用分包的方法就能解决,有些函数导致的相互依赖只能通过分包解决;分包能细化包的功能;
软相互依赖可以通过将方法拆分到另一个包的方式来解决;在拆分包的过程中,可能会将结构体的方法转化为普通的函数;
- 对于硬相互依赖只能通过定义接口的方法解决;定义接口能提高包的独立性,同时也提高了追踪代码调用关系的难度。
在 package b 中 定义 a interface ; 将 b 所有使用到结构体 a 的变量和方法的地方全部转化成 使用接口 a 的方法;在 a interface 中补充缺少的方法;
19、go 闭包调用?怎么避免?
1、什么是闭包调用?
闭包调用是指一个函数有权访问另一个函数作用域中的变量,常见的闭包调用就是在一个函数内部创建另一个函数, 内函数可以访问外函数的变量。
注意:闭包里作用域返回的局部变量不会被立刻销毁回收,可能会占用更多内存,过度使用闭包会导致性能下降。
2、带来的问题?
由于闭包会在其生命周期内保留对环境变量的引用,因此可能会导致一些问题,例如:
- 内存泄漏:如果闭包持有对某些资源的引用,但又没有及时释放这些资源,就会导致内存泄漏。
- 竞态条件:如果多个闭包同时访问和修改同一个共享变量,就可能出现竞态条件(race condition)的问题。
- 函数返回值不确定:如果闭包引用了函数内部的变量,那么当函数返回后,在闭包被调用之前这些变量的值可能已经被修改,从而导致闭包产生意外的行为。
3、怎么避免?
- 声明新变量,闭包函数使用新变量
- 将变量通过函数参数形式传递进闭包函数
20、结构体比较
- 2 个 interface 可以比较吗 ?
Go 语言中,接口(interface)是对非接口值(例如指针,struct 等)的封装,内部实现包含了 2 个字段,类型 T 和 值 V。接口类型的比较就演变成了结构体比较。
两个接口类型比较时,会先比较 T,再比较 V。接口类型与非接口类型比较时,会先将非接口类型尝试转换为接口类型,再按接口比较的规则进行比较。如果两个接口变量底层类型和值完全相同(或同为 nil)则两个变量相等,否则不等。
接口类型比较时,如果底层类型不可比较,则会发生 panic。
package main
import "fmt"
type Animal interface {
Speak() string
}
type Duck struct {
Name string
}
func (a Duck) Speak() string {
return "I'm " + a.Name
}
type Cat struct {
Name string
}
func (a Cat) Speak() string {
return "I'm " + a.Name
}
type Bird struct {
Name string
SpeakFunc func() string
}
func (a Bird) Speak() string {
return "I'm " + a.SpeakFunc()
}
// Animal 为接口类型,Duck 和 Cat 分别实现了该接口。
func main() {
var d1, d2, c1 Animal
d1 = Duck{Name: "Donald Duck"}
d2 = Duck{Name: "Donald Duck"}
c1 = Cat{Name: "Donald Duck"}
fmt.Println(d1 == d2) // 输出 true
fmt.Println(d1 == c1) // 输出 false
// 接口变量 d1、d2 底层类型同为 Duck 并且底层值相同,所以 d1 和 d2 相等。
// 接口变量 c1 底层类型为 Cat,尽管底层值相同,但类型不同,c1 与 d1 也不相等。
var animal Animal
animal = Duck{Name: "Donald Duck"}
var duck Duck
duck = Duck{Name: "Donald Duck"}
fmt.Println(animal == duck) // 输出 true
// 当 struct 和接口进行比较时,可以简单地把 struct 转换成接口然后再按接口比较的规则进行判定。
// animal 为接口变量,而 duck 为 struct 变量,底层类型同为 Duck 并且底层值相同,二者判定为相等。
var b1 Animal = Bird{
Name: "bird",
SpeakFunc: func() string {
return "I'm Poly"
}}
var b2 Animal = Bird{
Name: "bird",
SpeakFunc: func() string {
return "I'm eagle"
}}
fmt.Println(b1 == b2)
// panic: runtime error: comparing uncomparable type main.Bird
// 结构体 Bird 也实现了 Animal 接口,但结构体中增加了一个不可比较的函数类型成员 SpeakFunc,
// 因此 Bird 变成了不可比较类型,接口类型变量 b1 和 b2 底层类型为 Bird,在比较时会触发 panic。
}
- 2 个 nil 可能不相等吗?
2 个 nil 类型可能不相等,两个nil 只有在类型相同时才相等。例如,interface 在运行时绑定值,只有值为 nil 接口值才为 nil,但是与指针的 nil 不相等。
func main() {
var p *int = nil
var i interface{}
fmt.Println(p == nil) // 输出 true
fmt.Println(i == nil) // 输出 true
fmt.Println(i == p) // 输出 false
}
- 结构体比较
结构体是可以比较的,但前提是结构体成员字段全部可以比较,并且结构体成员字段类型、个数、顺序也需要相同,当结构体成员全部相等时,两个结构体相等。
特别注意的点,如果结构体成员字段的顺序不相同,那么结构体也是不可以比较的。如果结构体成员字段中有不可以比较的类型,如map、slice、function 等,那么结构体也是不可以比较的。
func main() {
sn1 := struct {
age int
name string
}{age: 11, name: "Zhang San"}
sn2 := struct {
age int
name string
}{age: 11, name: "Zhang San"}
fmt.Println(sn1 == sn2) // 输出 true
sn3 := struct {
name string
age int
}{age: 11, name: "Zhang San"}
fmt.Println(sn1 == sn3)
// 错误提示:Invalid operation: sn1 == sn3 (mismatched types struct {...} and struct {...})
sn4 := struct {
name string
age int
grade map[string]int
}{age: 11, name: "Zhang San"}
sn5 := struct {
name string
age int
grade map[string]int
}{age: 11, name: "Zhang San"}
fmt.Println(sn4 == sn5)
// 错误提示:Invalid operation: sn4 == sn5 (the operator == is not defined on struct {...})
}
21、go 语言中的可比较类型和不可比较类型
比较操作符分为等值操作符(== 和 !=)和排序操作符(<、<=、> 、 >=),等值操作符作用的操作数必须是可比较的,排序操作符作用的操作数必须是可排序的。
| 操作符 | 变量类型 |
|---|---|
| 等值操作符 (==、!=) | 整型、浮点型、字符串、布尔型、复数、指针、管道、接口、结构体、数组 |
| 排序操作符 (<、<=、> 、 >=) | 整型、浮点型、字符串 |
| 不可比较类型 | map、slice、function |
管道是可以比较的,管道本质上是个指针,make 语句生成的是一个管道的指针,所以管道的比较规则与指针相同,两个管道变量如果是同一个 make 语句声明(或同为 nil)则两个管道相等,否则不等。
cha := make(chan int, 10)
chb := make(chan int, 10)
chc := cha
fmt.Println(cha == chb) // 输出 false
fmt.Println(cha == chc) // 输出 true
// 管道 cha 和 chb 虽然类型和空间完全相同,但由于出自不同的 make 语句,所以两个管道不相等
// 但管道 chc 由于获得了管道 cha 的地址,所以管道 cha 和 chc 相等
fmt.Println(cha < chc)
// 错误提示:Invalid operation: cha < chc (the operator < is not defined on chan int)
- map、slice、function 为什么不能直接用 == 比较?使用什么可以比较?
至于这三种类型为什么不可比较,Golang 社区没有给出官方解释,经过分析,可能是因为 比较的维度不好衡量,难以定义一种没有争议的比较规则。所以 go 官方并没有定义比较运算符(==和!=),而是只能与nil进行比较。
比如两个 slice 类型相同、长度相同并且元素值也相同算不算相等?如果说相等,那么如果两个 slice 地址不同,还算不算相等呢?答案就可能无法统一了。至于 map 也是同样的道理。另外再看 function,两个函数实现功能一样,但实现逻辑不一样算不算相等呢?可见,这三种类型的比较容易引入歧义。
使用 reflect.TypeOf(value).Comparable() 判断可否进行比较, 使用 reflect.DeepEqual(value 1, value 2) 进行比较,当然也有特殊情况,例如 []byte,通过 bytes. Equal 函数进行比较。但是反射非常影响性能。
func main() {
s := "Hello World"
aMap := make(map[string]int)
bMap := make(map[string]int)
fmt.Println(reflect.TypeOf(s).Comparable()) // 输出 true
fmt.Println(reflect.TypeOf(aMap).Comparable()) // 输出 false
fmt.Println(reflect.TypeOf(bMap).Comparable()) // 输出 false
fmt.Println(reflect.DeepEqual(aMap, bMap)) // 输出 true
aMap["s"] = 1
fmt.Println(reflect.DeepEqual(aMap, bMap)) // 输出 false
}
22、interface 接口
-
在Go语言中,接口(interface)是方法的集合,它允许我们定义一组方法但不实现它们,任何类型只要实现了这些方法,就被认为是实现了该接口。接口更重要的作用在于多态实现,它允许程序以多态的方式处理不同类型的值。接口体现了程序设计的多态和高内聚、低耦合的思想。
-
使用的注意事项
(1)interface 类型默认是一个指针,引用类型。
(2)interface 接口不能包含任何变量。
(3)一个自定义类型可以实现多个接口。
(4)一个接口可以嵌套(继承)多个别的接口。
(5)接口的实现是隐式的,不需要显式声明。
(6)空接口没有任何方法,能被任意数据类型实现。
(7)结构体类型(structs)、类型别名(type aliases)、其他接口、自定义类型、变量等都可以实现接口。 -
接口分为侵入式和非侵入式
GO语言的接口是非侵入式接口。
侵入式接口的实现是显式声明的,必须显式的表明我要继承那个接口,必须通过特定的关键字(如Java中的implements)来声明实现关系。
非侵入式接口的实现是隐式声明的,不需要通过任何关键字声明类型与接口之间的实现关系。只要一个类型实现了接口的所有方法,那么这个类型就实现了这个接口。 -
应用场景
Go接口的应用场景包括多态性、解耦、扩展性、代码复用、API设计、单元测试、插件系统、依赖注入。
类型转换、类型判断、实现多态功能、作为函数参数或返回值。 -
空接口的应用场景
(1)用空接口可以让函数和方法接受任意类型、任意数量的函数参数,空接口切片还可以用于函数的可选参数。
(2)空接口还可以作为函数的返回值,但是极不推荐这样干,因为代码的维护、拓展与重构将会变得极为痛苦。
(3)空接口可以实现保存任意类型值的字典 (map)。
23、空结构体 struct 应用场景
空结构体在Go语言中通常用于需要一个空的值的场景。
- 作为channel的通知信号。通知型 channel,使用空结构体当做通知信号,不会带来额外的内存开销。
- 作为map的值。map + 空 struct 实现集合 set,节省内存。
- 作为方法接收器。在业务场景下,我们需要将方法组合起来,代表其是一个 ”分组“ 的,便于后续拓展和维护。在该场景下,使用空结构体是最合适的,易拓展,省空间,最结构化。
- 作为一个标记或占位符。表示某个动作已经发生,某个元素已被处理。
- 作为接口的实现。空结构体可以实现一个或多个接口,而不需要存储任何字段。这允许你创建符合特定接口的对象,而不需要为这些对象分配额外的内存空间。这在某些设计模式(如工厂模式、单例模式等)中特别有用。
空结构体主要有以下几个特点:
(1)零内存占用 :空结构体不占用任何内存空间,这使得空结构体在内存优化方面非常有用。
(2)地址相同:无论创建多少个空结构体,它们所指向的地址都是相同的,这意味着所有空结构体实例共享同一个内存位置。
(3)无状态:由于空结构体没有数据成员,因此它不包含任何状态信息。
24、go 内存泄漏
内存泄漏是指在程序执行过程中,已不再使用的内存空间没有被及时释放或者释放时出现了错误,导致这些内存无法被使用,直到程序结束这些内存才被释放。
如果出现内存泄漏问题,程序将会因为占据大量内存而变得异常缓慢,严重时可能会导致程序崩溃。在go语言中,可以通过runtime包里的freeosmemory()函数来进行内存回收和清理。此外,也可以使用一些工具来检测内存泄漏问题,例如go pprof等。需要注意的是,内存泄漏不是语言本身的问题,而通常是程序编写者忘记释放内存或者处理内存时出现错误导致的。
在Go中内存泄露分为暂时性内存泄露和永久性内存泄露。
- 暂时性内存泄露
临时性泄露,指的是该释放的内存资源没有及时释放,对应的内存资源仍然有机会在更晚些时候被释放,即便如此在内存资源紧张情况下,也会是个问题。这类主要是 string、slice 底层 buffer 的错误共享,导致无用数据对象无法及时释放,或者 defer 函数导致的资源没有及时释放。
1、获取长字符串中的一段导致长字符串未释放
2、获取长slice中的一段导致长slice未释放
3、获取指针切片slice中的一段
4、defer 导致的内存泄露
- 永久性内存泄露
永久性泄露,指的是在进程后续生命周期内,泄露的内存都没有机会回收,如 goroutine 内部预期之外的for-loop或者chan select-case导致的无法退出的情况,导致协程栈及引用内存永久泄露问题。
1、goroutine 协程阻塞,无法退出,导致内存泄漏;
Go运行时不会杀死挂起的goroutines,因此分配给挂起goroutines的资源(以及所引用的内存块)永远不会被垃圾回收。
- channel 阻塞导致 goroutine 阻塞
- select 导致 goroutine 阻塞
- 互斥锁没有释放,互斥锁死锁
- 申请过多的goroutine来不及释放导致内存泄漏
2、定时器使用不当,time.Ticker未关闭导致内存泄漏;
time.After在定时器到达时,会自动内回收。然后time.Ticker 钟摆不使用时,一定要Stop,不然会造成真内存泄露。
3、不正确地使用终结器(Finalizers)导致内存泄漏
25、协程泄露
协程泄露是指协程创建后,长时间得不到释放,并且还在不断地创建新的协程,最终导致内存耗尽,程序崩溃。
常见的导致协程泄露的场景有以下几种:
1、缺少接收方,导致发送方阻塞。启动1000个协程向信道发送数字,但只接收了一次,导致 999 个协程阻塞,不能退出。
2、缺少发送方,导致接收方阻塞。启动 1000 个协程接收信道的信息,但信道并不会发送那么多次的信息,也会导致接收协程被阻塞,不能退出。
3、死锁。多个协程由于竞争资源或者彼此通信而造成阻塞,不能退出。
4、select操作。select里也是channel操作,如果所有case上的操作阻塞,且没有default分支进行处理,goroutine也无法继续执行。
26、值传递和地址传递(引用传递)
Go语言函数传参时,默认使用值传递。
值传递是指当我们调用一个方法并将参数传递给它时,实际上是把变量的一个副本传递给了函数,而非原始变量自己,两个变量的地址不同,不可相互修改。 在函数内部,对于这个参数所做的任何更改,只会影响副本的值,不会影响原始变量。
地址传递(引用传递)是指传递给函数的是变量的指针或者地址(变量本身),函数可以通过修改这个地址上的值来更改变量的值,对该变量的修改在所有使用它的地方都是可见的。
| 区别 | 值传递 | 引用传递 |
|---|---|---|
| 传参 | 变量的副本 | 变量本身(指针或者地址) |
| 影响范围 | 只影响副本,不影响原始变量 | 影响原始变量 |
| 使用场景 | 处理较小的变量时速度更快 | 避免复制大块的内存内容 |
27、go 语言中栈的空间有多大?
多数架构上默认栈大小都在 2 ~ 4 MB 左右。在Go语言中,栈空间大小并不是固定的,而是根据程序的运行需求动态调整的,Goroutine 的初始栈大小降低到了 2KB。在64位操作系统上,Go中的栈空间最大可以扩展到1GB。
早期版本的Go可能将最小栈内存设置为4KB或8KB,而后来为了优化性能,又可能将其调整回2KB。
28、并发情况下的数据处理,避免并发情况下数据竞争问题?
1、使用互斥锁(mutex):在操作共享资源之前,加锁;完成操作后,解锁。
2、使用读写互斥锁(RWMutex):读不阻塞,写阻塞。允许多个goroutine同时访问共享变量,写入时就必须等到其他goroutine不再读写了才能进行。这种方法适合在读多写少的场景。
3、使用通道(channel)串行化操作:使用通道来实现数据同步和互斥访问,将需要访问的数据发送到一个通道中,可以保证同一时间只有一个goroutine能够访问该数据。类似于生产者消费者模式。
4、使用原子操作(atomic):如果只是对一个共享变量进行简单的增加或减少,就可以使用原子操作。原子操作是一个CPU指令,它保证在一个时刻内执行所有的增量或减量,避免了并发情况下的数据竞争问题。
29、init() 函数是什么时候执行的?
简答: 在main函数之前执行。
详细:init()函数是go初始化的一部分,由runtime初始化每个导入的包,初始化不是按照从上到下的导入顺序,而是按照解析的依赖关系,从被导入的最深层包开始进行初始化,没有依赖的包最先初始化。Go的依赖分析器会尽可能并行地初始化包。init() 函数是在main() 函数之前执行的。全局常量、变量是在 init 函数之前初始化的。
1、init() 函数特点
- init() 函数是可选的,源文件可以没有 init() 函数。
- init() 函数没有入参和返回值,自动执行,不能被其他函数调用。(与 main 函数一样)
- 同一个包,甚至是同一个源文件可以有多个 init() 函数。
- 不管包被导入多少次,包内的 init 函数只会执行一次。
2、需要注意的点
- 程序初始化的顺序是,从被导入的最深层包开始进行初始化,层层递出最后到 main 包;
- Go的依赖分析器会尽可能并行地初始化包;
- 程序的初始化和执行都起始于 main 包。如果 main 包还导入了其它的包,那么就会在编译时将它们依次导入;
- 有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到 fmt 包,但它只会被导入一次,因为没有必要导入多次);
- 不同包的init函数按照包导入的依赖关系决定执行顺序。
- 在编码时避免依赖 init() 函数的执行顺序。虽然 init() 顺序是明确的,但代码可以更改,init() 函数之间的关系可能会使代码变得脆弱和容易出错,因此在编码时避免依赖 init() 函数的执行顺序。
3、Go语言代码执行顺序
Go语言代码执行顺序为:import –> const –> var –>init()–>main()。
- 初始化所有被导入的包;
- 初始化被导入的包所有全局常量、变量;
- 执行被导入的包 init() 函数;
- 层层递出最后执行 main() 函数。

4、多个init() 函数执行顺序
- 一个源文件中多个 init() 函数的执行顺序是根据定义顺序确定,从上到下。
- 一个包中多个 init() 函数的执行顺序是根据文件名的字典序确定,从小到大。
- 多个包中多个 init() 函数,包不相互依赖,多个 init() 函数的执行顺序是根据 main 包中导入顺序确定,从上到下,最后再执行 main 包的 init 函数。
- 多个包中多个 init() 函数,包存在依赖,多个 init() 函数的执行顺序是根据包导入的依赖关系确定,从里到外,执行顺序为最后被依赖的包(最深层的包:c 包)最先被初始化,如依赖关系 main > a > b > c,则 init 函数执行顺序为 c > b > a > main。
- 一个包会被多个包同时导入,它只会被导入一次,init() 函数只执行一次。
二、channel 通道
在Go语言中,channel是一种用于在goroutine之间传递数据的安全通信机制。它可以被看做是一种特殊类型的队列,其中的数据只能被一个goroutine读取而另一个goroutine写入。要创建一个channel,可以使用内置的make函数。
1、底层数据结构
type hchan struct {
// chan 里元素数量
qcount uint
// chan 底层循环数组的长度
dataqsiz uint
// 指向底层循环数组的指针
// 只针对有缓冲的 channel
buf unsafe.Pointer
// chan 中元素大小
elemsize uint16
// chan 是否被关闭的标志
closed uint32
// chan 中元素类型
elemtype *_type // element type
// 已发送元素在循环数组中的索引
sendx uint // send index
// 已接收元素在循环数组中的索引
recvx uint // receive index
// 等待接收的 goroutine 队列
recvq waitq // list of recv waiters
// 等待发送的 goroutine 队列
sendq waitq // list of send waiters
// 保护 hchan 中所有字段
lock mutex
}
从channel中读数据:
1、若等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G ,把 G 中数据读出,最后把 G 唤醒,结束读取过程。
2、如果等待发送队列 sendq 不为空,说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程。
3、如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程。将当前 goroutine 加入 recvq ,进入睡眠,等待被写 goroutine 唤醒。
往channel中写数据
1、若等待接收队列 recvq 不为空,则缓冲区中无数据或无缓冲区,将直接从 recvq 取出 G ,并把数据写入,最后把该 G 唤醒,结束发送过程。
2、若缓冲区中有空余位置,则将数据写入缓冲区,结束发送过程。
3、若缓冲区中没有空余位置,则将发送数据写入 G,将当前 G 加入 sendq ,进入睡眠,等待被读 goroutine 唤醒。
关闭 channel
关闭 channel 时会将 recvq 中的 G 全部唤醒,本该写入 G 的数据位置为 nil 。将 sendq 中的 G 全部唤醒,但是这些 G 会 panic。
2、channel为什么能做到线程安全?
channel可以理解是一个先进先出的循环队列,通过管道进行通信,发送一个数据到Channel和从Channel接收一个数据都是原子性的。不要通过共享内存来通信,而是通过通信来共享内存,前者就是传统的加锁,后者就是Channel。设计Channel的主要目的就是在多任务间传递数据的,本身就是安全的。
3、无缓冲的 channel 和 有缓冲的 channel 的区别?
阻塞与否是分别针对发送方、接收方而言的,可以类比生产者与消费者问题。
对于无缓冲的 channel,发送方将阻塞该信道,直到接收方从该信道接收到数据为止,而接收方也将阻塞该信道,直到发送方将数据发送到该信道中为止。
对于有缓存的 channel,发送方在缓冲区满的时候阻塞,接收方不阻塞;接收方在缓冲区为空的时候阻塞,发送方不阻塞。
4、channel 死锁的场景
1、当一个channel中没有数据,而直接读取时,会发生死锁;
2、当channel数据满了,再尝试写数据会造成死锁;
3、向一个关闭的channel写数据。
解决方案是采用select语句,再default放默认处理方式。
1、Go的select语句是一种仅能用于channl发送和接收消息的专用语句,此语句运行期间是阻塞的;当select中没有case语句的时候,会阻塞当前groutine。
2、select是Golang在语言层面提供的I/O多路复用的机制,其专门用来检测多个channel是否准备完毕:可读或可写。
3、select语句中除default外,每个case操作一个channel,要么读要么写。
4、select语句中除default外,各case执行顺序是随机的。
5、select语句中如果没有default语句,则会阻塞等待任一case。
6、select语句中读操作要判断是否成功读取,关闭的channel也可以读取。
5、操作 channel 的情况总结
| 操作 | nil channel(未初始化) | closed channel | not nil, not closed channel |
|---|---|---|---|
| close | panic | panic | 正常关闭 |
| 读 <- ch | 阻塞 | 读到对应类型的零值 | 阻塞或正常读取数据。非缓冲型 channel 没有等待发送者或缓冲型 channel buf为空时会阻塞 |
| 写 ch <- | 阻塞 | panic | 阻塞或正常写入数据。非缓冲型 channel 没有等待接收者或缓冲型 channel buf 满时会被阻塞 |
总结一下,发生 panic 的情况有三种:向一个关闭的 channel 进行写操作;关闭一个未初始化的 channel;重复关闭一个 channel。
读、写一个未初始化的channel 都会被阻塞。
三、map 哈希表
1、map 的底层数据结构是什么?
源码位于 src\runtime\map.go 中。
golang 中 map 底层使用的是哈希查找表,用链表来解决哈希冲突。每个 map 的底层结构是 hmap,是有若干个结构为 bmap 的 bucket 组成的数组,每个 bucket 底层都采用链表结构。
hmap的结构:
type hmap struct {
count int // map中元素的数量,调用len()直接返回此值
flags uint8 // 状态标识符,key和value是否包指针、是否正在扩容、是否已经被迭代
B uint8 // map中桶数组的数量,桶数组的长度的对数,len(buckets) == 2^B,可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子
noverflow uint16 // 溢出桶的大概数量,当B小于16时是准确值,大于等于16时是大概的值
hash0 uint32 // 哈希种子,用于计算哈希值,为哈希函数的结果引入一定的随机性,降低哈希冲突的概率
buckets unsafe.Pointer // 指向桶数组的指针,长度为 2^B ,如果元素个数为0,就为 nil
oldbuckets unsafe.Pointer // 指向一个旧桶数组,用于扩容,它的长度是当前桶数组的一半
nevacuate uintptr // 搬迁进度,小于此地址的桶数组迁移完成
extra *mapextra // 可选字段,用于gc,指向所有的溢出桶,避免gc时扫描整个map,仅扫描所有溢出桶就足够了
}
bmap的结构:
type bmap struct {
tophash [bucketCnt]uint8 // bucketCnt=8,存放key哈希值的高8位,用于决定kv键值对放在桶内的哪个位置
}
buckets是一个bmap数组,数组的长度就是 2^B。每个bucket固定包含8个key和value,实现上面是一个固定的大小连续内存块,分成四部分:tophash 值,8个key值,8个value值,指向下个bucket的指针。
tophash 值用于快速查找key是否在该bucket中,当插入和查询运行时都会使用哈希哈数对key做哈希运算,获取一个hashcode,取高8位存放在bmap tophash字段中。
桶结构中,所有的key放一起,所有的value放一起,而不是key/value一对一存放,目的是省去 pad 字段,节省内存空间。由于内存对齐的原因,key/value一对一的形式可能需要更多的补齐空间。
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个溢出桶,通过指针连接起来。
key 定位过程
key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机),
低 B 位:后 B 位,决定在哪个桶。用于寻找当前key属于哪个bucket,桶的编号;
高 8 位:前 8 位,决定在桶的的哪个位置。找到此 key 在 bucket 中的位置,第几个槽位,key 和 value 也对应第几个。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
2、map的扩容
1、装载因子(平均每个桶存储的元素个数)
Go的装载因子阈值常量:6.5,map 最多可容纳 6.5*2^B 个元素。
装载因子等于 map中元素的个数 / map的容量,即len(map) / 2^B。装载因子用来表示空闲位置的情况,装载因子越大,表明空闲位置越少,冲突也越多,散列表的性能会下降。
为什么装载因子是6.5?不是8?不是1?
装载因子是哈希表中的一个重要指标,主要目的是为了平衡 buckets 的存储空间大小和查找元素时的性能高低。
Go 官方发现:装载因子越大,填入的元素越多,空间利用率就越高,但发生冲突的几率就变大;反之,装数因子越小,填入的元素越少,冲突发生的几率减小,但空间利用率低,而且还会提高扩容操作的次数。根据测试结果和讨论,Go 官方取了一个相对适中的值6.5。
2、触发 map 扩容的时机(插入、删除key):
触发扩容的时机是新增操作,搬迁的时机是赋值和删除操作,每次最多搬迁两个bucket。
扩容分为等量扩容和2倍增量扩容。
条件1:
当元素个数超过负载,元素个数 > 6.5 * 桶个数,扩容一倍,属于增量扩容;
条件2:
当使用的溢出桶过多时,重新分配一样大的内存空间,属于等量扩容;(实际上没有扩容,主要是为了回收空闲的溢出桶,提高 map 的查找和插入效率)
如何定义溢出桶是否太多需要等量扩容呢?两种情况:
- 当B小于15时,溢出桶的数量超过2^B桶总数,属于溢出桶数量太多,需要等量扩容;
- 当B大于等于15时,溢出桶数量超过2^15,属于溢出桶数量太多,需要等量扩容。
条件2是对条件1的补充,例如不停地插入、删除元素,导致创建很多的溢出桶,但装载因子不高,达不到条件1的临界值,不能触发扩容来缓解这种情况。溢出桶数量太多,桶使用率低,导致 key 会很分散,查找插入效率低,空间利用率低。
3、扩容策略(怎么扩容?)
Go 会创建一个新的 buckets 数组,新的 buckets 数组的容量是旧buckets数组的两倍(或者和旧桶容量相同),将原始桶数组中的所有元素重新散列到新的桶数组中。这样做的目的是为了使每个桶中的元素数量尽可能平均分布,以提高查询效率。旧的buckets数组不会被直接删除,而是会把原来对旧数组的引用去掉,让GC来清除内存。
扩容过程是渐进式的,主要是防止一次扩容要搬迁的元素太多引发性能问题。
在map进行扩容迁移的期间,不会触发第二次扩容。只有在前一个扩容迁移工作完成后,map才能进行下一次扩容操作。
4、搬迁策略
由于map扩容需要将原有的kv键值对搬迁到新的内存地址,如果一下子全部搬完,会非常的影响性能。go 中 map 的扩容采用渐进式的搬迁策略,原有的 key 并不会一次性搬迁完毕,一次性搬迁会造成比较大的延时,每次最多只会搬迁 2 个 bucket,将搬迁的O(N)开销均摊到O(1)的赋值和删除操作上。
插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。
3、从未初始化的 map 读数据会发生什么?
从未初始化的 map 读取数据,则会返回该值类型的零值。当给未初始化的 map 赋值时,会出现运行时错误 “panic: assignment to entry in nil map” ,这是因为未经初始化的 map 是一个 nil 值,并且不能对 nil map 进行赋值操作。因此,在使用一个 map 之前,必须确保它已经正确地初始化。
| 操作 | nil map (未初始化) | 空 map (长度为 0) |
|---|---|---|
| 赋值 | panic | 不会报错 |
| 打印 | 不会报错,打印 map[] | 不会报错 |
| 读取 | 不会报错,读到对应类型的零值 | 不会报错 |
| 删除 | 不会报错 | 不会报错 |
func main() {
var a map[int]int // 未初始化 map
b := map[int]int{} // 空 map
a[1] = 1 // panic: assignment to entry in nil map
b[1] = 1
fmt.Println(a) // map[]
fmt.Println(b) // map[1:1]
fmt.Println(a[1]) // 0
fmt.Println(b[1]) // 1
delete(a, 1)
delete(b, 1)
}
4、map 中的 key 为什么是无序的?怎么实现有序?
无序的原因
(1)map底层的扩容与搬迁:map在扩容后,会发生key的搬迁,原来在同一个桶的key,搬迁后,有可能就不处于同一个桶了,而遍历map的过程,就是遍历这些桶,桶里的元素发生了变化,map遍历当然就是无序的。
(2)随机 bucket 随机序号:Go 中遍历 map 时,并不是固定地从 0 号 bucket 开始遍历,每次都是从一个随机值序号的 bucket 开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历。这样,即使你是一个写死的 map,仅仅只是遍历它,也不太可能会返回一个固定序列的 key/value 对了。
实现有序
(1)使用第三方库,如 github.com/iancoleman/orderedmap 或者 github.com/wkhere/ordered_map,这些库提供了类似于标准库中的 map 操作,同时也保持了元素的顺序。
(2)使用 sort 包。使key有序,对key排序,再遍历key输出value;使value有序,用struct存放key和value,实现sort接口,调用sort.Sort进行排序。
5、map并发访问安全吗?怎么解决?可以边遍历边删除吗?
map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。在并发访问下,多个goroutine同时读写同一个map会导致数据竞争(data race)问题,这可能导致不可预期的结果和程序崩溃。并发读写的时候运行时会有检查,在查找、赋值、遍历、删除的过程中都会进行写保护检测,检测写标志,一旦发现写标志置位(等于1),则直接 panic。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作。
go 官方认为,map 更应适配典型使用场景(不需要从多个 goroutine 中进行安全访问),而不是为了小部分情况(并发访问),导致大部分程序付出加锁的代价,影响性能,所以决定了不支持。
解决方法:
(1)使用读写锁 sync.RWMutex,读之前调用 RLock() 函数,读完之后调用 RUnlock() 函数解锁;写之前调用 Lock() 函数,写完之后,调用 Unlock() 解锁。
(2)使用 sync.Map ,并发安全的 map。使用 Store() 函数赋值,使用 Load() 函数获取值。
Go map和sync.Map谁的性能好,为什么?
sync.Map 性能好,空间换时间机制,冗余的数据结构就是dirty和read,发生锁竞争的频率小,减少了加锁对性能的影响。适合读多写少的场景,写多的场景,需要加锁,性能会下降。
遍历操作:只需遍历read即可,而read是并发读安全的,没有锁,相比于加锁方案,性能大为提升
查找操作:先在read中查找,read中找不到再去dirty中找
边遍历边删除——同时读写?
(1)多个协程同时读写同一个 map 会直接 panic。
(2)如果在同一个协程内边遍历边删除,并不会 panic,但是,遍历的结果就可能不会是相同的了,有可能结果集中包含了删除的 key,也有可能不包含,这取决于删除 key 的时间:是在遍历到 key 所在的 bucket 时刻前或者后。
6、map元素可以取地址吗?
无法对 map 的 key 或 value 进行取址,因为扩容后map元素的地址会发生变化,归根结底还是map底层的扩容与搬迁。
7、map 中删除一个 key,它的内存会释放么?
不会释放,因为删除只是将桶对应位置的tophash置空而已,如果kv存储的是指针,那么会清理指针指向的内存,否则不会真正回收内存,内存占用并不会减少。
在大多数情况下,删除 Map 中的 key 不会立即释放内存。这是因为在大多数语言中,Map 内部实现使用哈希表或红黑树等数据结构来存储键值对,而删除一个键值对只是将该键值对的引用从内部数据结构中删除,并不会立即释放与其相关的内存。
8、什么样的类型可以做 map 的键 key?
Go 语言中只要是可比较的类型都可以作为 key。除开 slice,map,functions 这几种类型,其他类型都是 OK 的。具体包括:布尔值、数字、字符串、指针、通道、接口类型、结构体、只包含上述类型的数组。这些类型的共同特征是支持 == 和 != 操作符,k1 == k2 时,可认为 k1 和 k2 是同一个 key。如果是结构体,只有 hash 后的值相等以及字面值相等,才被认为是相同的 key。很多字面值相等的,hash出来的值不一定相等,比如引用。
任何类型都可以作为 value,包括 map 类型。
float 型可以作为 key,但是由于精度的问题,会导致一些诡异的问题,慎用之。
2.4 == 2.4000000000000000000000001
当用 float64 作为 key 的时候,先要将其转成 unit64 类型,再插入 key 中。2.4 和 2.4000000000000000000000001 经过 math.Float64bits() 函数转换后的结果是一样的,所以认为同一个 key 。
NAN != NAN
hash(NAN) != hash(NAN)
NAN 是从一个常量解析得来的,为什么插入 map 时,会被认为是不同的 key?
哈希函数针对 NAN,会再加一个随机数,所以认为是不同的key。
9、如何比较两个 map 相等?
map 深度相等的条件:
1、都为 nil
2、非空、长度相等,指向同一个 map 实体对象
3、相应的 key 指向的 value “深度”相等
直接将使用 map1 == map2 是错误的,编译不通过。== 只能比较 map 是否为 nil。因此只能是遍历map 的每个元素,比较元素是否都是深度相等。使用 reflect.DeepEqual 进行比较。
10、map怎么解决哈希冲突?
在Go语言中,map是通过哈希表来实现的,当多个键映射到哈希表的同一个桶时,就会发生哈希冲突。Go语言使用 链地址法(拉链法)解决哈希冲突。
解决哈希冲突的方法:
- 开放寻址法
如果发生哈希冲突,从发生冲突的那个单元起,按一定的次序,不断重复,从哈希表中寻找一个空闲的单元,将该键值对存储在该单元中。具体的实现方式包括线性探测法、平方探测法、随机探测法和双重哈希法等。开放寻址法需要的表长度要大于等于所需要存放的元素数量。- 链地址法(拉链法)
基于数组 + 链表 实现哈希表,数组中每个元素都是一个链表,将每个桶都指向一个链表,当哈希冲突发生时,新的键值对会按顺序添加到该桶对应的链表的尾部。在查找特定键值对时,可以遍历该链表以查找与之匹配的键值对。
两种方案的比较:
(1)对于链地址法,基于 数组 + 链表 进行存储,链表节点可以在需要时再创建,开放寻址法需要事先申请好足够内存,因此链地址法对内存的利用率高。
(2)链地址法对装载因子的容忍度会更高,适合存储大对象、大数据量的哈希表,而且相较于开放寻址法,它更加灵活,支持更多的优化策略,比如可采用红黑树代替链表。但是链地址法需要额外的空间来存储指针。
(3)对于开放寻址法,它只有数组一种数据结构就可完成存储,继承了数组的优点,对CPU缓存友好,易于序列化操作,但是它对内存的利用率不高,且发生冲突时代价更高。当数据量明确、装载因子小,适合采用开放寻址法。
11、map 使用中注意的点?
(1)一定要先初始化,再使用,否则panic;
(2)map 不是线程安全的;
(3)map 的 key 必须是可比较的;
(4)map是无序的。
12、map 创建、赋值、删除、查询的过程?
写保护检测,查找、赋值、遍历、删除的过程中都会检测写标志位 flags,一旦发现 flags 的写标志位被置为1,则直接 panic,因为这表明有其他协程同时在进行写操作。查找,赋值,删除这些操作一个很核心的内容都是如何定位key的位置。
创建 map
创建 map 底层调用的是 makemap() 函数,主要做的工作就是初始化 hmap 结构体的各种字段,例如计算 B 的大小、设置哈希种子 hash0 、分配桶空间等。
默认会创建2^B个bucket,如果b大于等于4,会预先创建一些溢出桶,b小于4的情况可能用不到溢出桶,没必要预先创建
其中的关键点在于哈希函数的选择,在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go 下。
hash 函数,有加密型和非加密型。
加密型的一般用于加密数据、数字摘要等,典型代表就是 md5、sha1、sha256、aes256 这种;
非加密型的一般就是查找。在 map 的应用场景中,用的是查找。
选择 hash 函数主要考察的是两点:性能、碰撞概率。
map 的赋值(修改)过程
向 map 中插入或者修改 key,底层调用的是 mapassign() 函数,根据 key 类型的不同,编译器会将其优化为相应的“快速函数”。流程:对 key 计算 hash 值,根据 hash 值按照之前的流程,找到要赋值的位置(可能是插入新 key,也可能是更新老 key),对相应位置进行赋值。
核心还是一个双层循环,外层遍历 bucket 和它的 overflow bucket,内层遍历整个 bucket 的各个 cell。
map 的删除过程
底层调用的是 mapdelete() 函数,根据 key 类型的不同,删除操作会被优化成更具体的函数。它首先会检查 h.flags 标志,如果发现写标位是 1,直接 panic,因为这表明有其他协程同时在进行写操作。计算 key 的哈希值,找到落入的 bucket。检查此 map 如果正在扩容的过程中,直接触发一次搬迁操作。
删除操作同样是两层循环,核心还是找到 key 的具体位置。寻找过程都是类似的,在 bucket 中挨个 cell 寻找。找到对应位置后,对 key 或者 value 进行“清零”操作。最后,将 count 值减 1,将对应位置的 tophash 值置成 Empty。
删除key仅仅只是将其对应的tohash值置空,如果kv存储的是指针,那么会清理指针指向的内存,否则不会真正回收内存,内存占用并不会减少。
如果正在扩容,并且操作的bucket没有搬迁完,那么会搬迁bucket。
map 的查询过程
底层调用的是 mapaccess1()、mapaccess2() 函数,mapaccess2() 函数返回值多了一个 bool 型变量,两者的代码也是完全一样的,只是在返回值后面多加了一个 false 或者 true。根据 key 的不同类型,编译器用更具体的函数替换,以优化效率。流程:计算hash值并根据hash值找到桶,遍历桶和桶串联的溢出桶,寻找 key。
需要注意的地方:如果根据hash值定位到桶正在进行搬迁,并且这个bucket还没有搬迁到新桶中,那么就从老的桶中找。在bucket中进行顺序查找,使用高八位进行快速过滤,高八位相等,再比较key是否相等,找到就返回value。如果当前bucket找不到,就往下找溢出桶,都没有就返回零值。
四、slice 切片
1、数组和切片的区别
- 相同点:
(1)都是只能存储一组相同类型的数据结构;
(2)下标都是从0开始的,可以通过下标来访问单个元素;
(3)有容量、长度,长度通过 len 获取,容量通过 cap 获取。
- 不同点:
(1)数组是定长的,长度定义好之后,不能再更改,长度是类型的一部分,访问和复制不能超过数组定义的长度,否则就会下标越界。切片长度和容量可以自动扩容,切片的类型和长度无关。
在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
(2)数组是值类型。切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是底层数组存储数据,修改切片的时候修改的是底层数组中的数据,切片一旦扩容,会指向一个新的底层数组,内存地址也就随之改变。
2、slice 底层数据结构
源码位于 src\runtime\slice.go 中。
golang 中 slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 长度
cap int // 容量
}
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
创建 slice 底层调用的是 makeslice() 函数,主要工作是向 Go 内存管理器申请内存(在堆上分配),返回指向底层数组的指针。
32KB = 32768 字节。小对象是从per-P缓存的空闲列表中分配的。大型对象(>32kB)是直接从堆中分配的。
扩容,底层调用的是 growslice() 函数,里面包括扩容规则、内存对齐、申请新内存、拷贝旧数据。
拷贝,底层调用的是 slicecopy() 函数,切片中全部元素通过memmove或者数组指针的方式将整块内存中的内容拷贝到目标的内存区域,所以大切片拷贝需要注意性能影响,不过比一个个的复制要有更好的性能。
3、slice 的扩容
1、触发扩容的时机
向 slice 追加元素,如果底层数组的容量不够(即便底层数组并未填满),就会触发扩容。追加元素调用的是 append 函数。
2、扩容规则
Go <= 1.17
1、首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
2、否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的 2 倍。
3、否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)就是旧容量(old.cap)按照 1.25 倍循环递增,也就是每次加上 cap / 4。
4、如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
Go1.18之后
引入了新的扩容规则,首先 1024 的边界不复存在,取而代之的常量是 256 。超出256的情况,也不是直接扩容25%,而是设计了一个平滑过渡的计算方法,随着容量增大,扩容比例逐渐从100%平滑降低到25%,从 2 倍平滑过渡到 1.25 倍。
为什么要这样设计?
避免追加过程中频繁扩容,减少内存分配和数据复制开销,有助于性能提升。
3、内存对齐
计算出了新容量之后,还没有完,出于内存的高效利用考虑,还要进行内存对齐。进行内存对齐之后,新 slice 的容量是要 大于等于 老 slice 容量的 2倍或者1.25倍。
4、完整过程
向 slice 追加元素的时候,若容量不够,会触发扩容,会调用 growslice 函数。首先,根据扩容规则,计算出新的容量,然后进行内存对齐,之后,向 Go 内存管理器申请内存,将老 slice 中的数据整个复制过去,并且将追加的元素添加到新的底层数组中。
4、slice 的拷贝
1、浅拷贝
浅拷贝,拷贝的是地址,浅拷贝只复制了指向底层数据结构的指针,而不是复制整个底层数据结构,修改新对象的值会影响原对象值。对于引用类型,如切片和字典等都是浅拷贝。
slice2 := slice1
slice1和slice2指向的都是同一个底层数组,任何一个数组元素被改变,都可能会影响两个slice。在slice触发扩容操作前,slice1和slice2指向的都是相同数组,但在触发扩容操作后,二者指向的就不一定是相同的底层数组了。
2、深拷贝
深拷贝,拷贝的是数据本身,完全复制了底层数据结构,而不是复制指向底层数据结构的指针,会创建一个新对象,新对象和原对象不共享内存,它们是完全独立的,修改新对象的值不会影响原对象值,内存地址不同,释放内存地址时,可以分别释放。
copy(slice2, slice1)
把 slice1 的数据复制到 slice2 中,修改 slice2 的数据,不会影响到 slice1 。如果 slice2 的长度和容量小于 slice1 的,那么只会复制 slice2 长度的数据。
5、append 函数
使用 append 可以向 slice 追加元素,实际上是往底层数组添加元素,如果底层数组的容量不够,会触发扩容。append 函数的参数长度可变,因此可以追加多个值到 slice 中,还可以用 … 传入 slice,直接追加一个切片。
append函数返回值是一个新的slice,Go编译器不允许调用了 append 函数后不使用返回值。
注意:append不会修改传参进来的slice(len和cap),只会在不够用的时候新分配一个array,并把之前的slice依赖的array数据拷贝过来;所以对同一个slice 重复 append,只要不超过cap,都是修改的同一个array,后面的会覆盖前面。
func main() {
a := []int{1, 2, 3, 4, 5}
b := append(a, 100)
fmt.Println(b) // [1 2 3 4 5 100]
c := append(a, 200)
fmt.Println(c) // [1 2 3 4 5 200]
}
6、切片作为函数参数?
当 slice 作为函数参数时,是值传递,函数内部对 slice 的作用并不会改变外层的 slice ,要想真的改变外层 slice,只有将返回的新的 slice 赋值到原始 slice,或者向函数传递一个指向 slice 的指针。slice 结构体自身不会被改变,指针指向的底层数组的地址也不会被改变,改变的是数组中的数据。
传slice和传slice的引用,其实开销区别不大。Go 语言的函数参数传递,只有值传递,没有引用传递。
7、切片 slice 使用时注意的点?
(1)创建slice时应根据实际需要预分配容量,避免追加过程中频繁扩容,有助于性能提升;在大批量添加数据时,建议⼀次性分配足够大的空间,以减少内存分配和数据复制开销;
(2)slice是非并发安全的,如要实现并发安全,请采用锁或channle;
(3)大数组作为函数参数时,会复制整个数组,消耗过多内存,建议采用slice或指针;
(4)如果只用到大的slice或数组的一部分,建议将需要部分复制到新的slice中取,以便释放大的slice底层数组内存,减少内存占用;
(5)多个slice指向相同的底层数组时,修改其中一个slice,可能会影响其他slice的值;
(6)slice作为参数传递时,比数组更为高效,因为slice本身的结构就比较小,所以你参数传递时,传slice和传slice的引用,其实开销区别不大;
(7)slice在扩容时,可能会发生底层数组的变更和数据拷贝;
(8)及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
8、slice 内存泄露情况
当 slice2 的底层数组很大,但 slice1 使用 slice2 中很小的一段,slice1 和 slice2 共用一个底层数组,底层数组占据的大部分空间都是被浪费的,没法被回收,造成了内存泄露。
解决方法:
不再引用 slice2 数组,将需要的数据复制到一个新的slice中,这样新slice的底层数组,就和 slice2 数组无任何关系了。
func main() {
slice2 := make([]int, 1000)
// 错误用法
slice1 := slice2[:1] // slice1 和 slice2 共用一个底层数组
// 正确用法
copy(slice1, slice2[:1])
return
}
9、slice 并发不安全
在Go语言中,slice是并发不安全的,主要有以下两个原因:数据竞争、内存重分配。slice底层的结构体包含一个指向底层数组的指针和该数组的长度,当多个协程并发访问同一个slice时,有可能会出现数据竞争的问题。例如,一个协程在修改slice的长度,而另一个协程同时在读取或修改slice的内容。在向slice中追加元素时,可能会触发slice的扩容操作,在这个过程中,如果有其他协程访问了slice,就会导致指向底层数组的指针出现异常。
要并发安全,有两种方法:加互斥锁、使用channel串行化操作。加互斥锁适合于对性能要求不高的场景,毕竟锁的粒度太大,这种方式属于通过共享内存来实现通信。channle 适合于对性能要求大的场景,channle就是专用于goroutine间通信的,这种方式属于通过通信来实现共享内存。
10、从未初始化的 slice读数据会发生什么?
从未初始化的 slice 上读取数据,给未初始化的 slice 赋值,会发生运行时错误(panic),未初始化的 slice 没有分配底层数组,指向底层数组的指针为 nil,因此不能存储元素,读取和赋值会 panic: runtime error: index out of range [0] with length 0。因此,在使用一个slice之前,必须确保它已经正确地初始化。

















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









