






1.redis内存满了后,内存淘汰策略
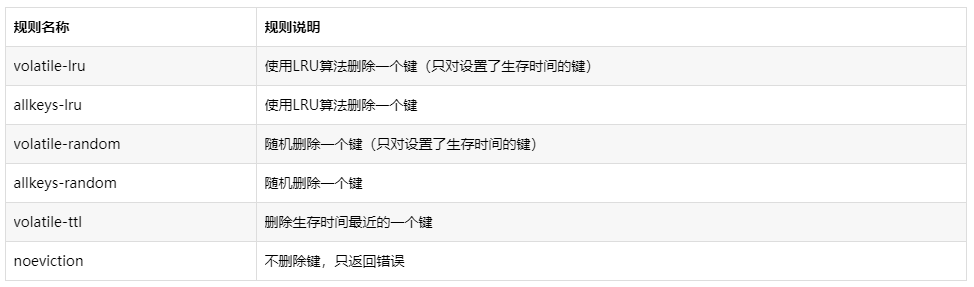
默认是noeviction,
LRU算法,least RecentlyUsed,最近最少使用算法。也就是说默认删除最近最少使用的键。
2.redis的持久化机制,以及应用场景
Redis提供 RDB 和 AOF 两种持久化机制 , 有了持久化机制我们基本上就可以避免进程异常退出时所造成的数据丢失的问题了,Redis能在下一次重启的时候利用之间产生的持久化文件实现数据恢复。
持久化机制之RDB
我们所谓的RDB持久化就是指的讲当前进程的数据生成快照存入到磁盘中,触发RDB机制又分为手动触发与自动触发
"save"命令,但是"save"命令将会阻塞我们的Redis服务器直到RDB完成,所以真实的环境中一般不会使用该命令。
"bgsave"命令,使用该命令Redis会fork一个子进程来负责RDB持久化,完成持久化后自动结束子进程,所以阻塞只发生在fork的阶段。
自动触发RDB只要在redis的conf 配置文件中配置 save相关的配置即可,如 "save m n",这就代表在m秒内我们的数据发生了n次修改就会使用“bgsave”命令自动触发RDB,如不需要即用#将下图的 save 900 1; save 300 10; save 60 10000 注释即可
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1 #900秒内发生了1此修改
save 300 10 #300秒内发生了10此修改
save 60 10000 #60秒内发生了10000此修改
RDB注意事项
1、若手动触发RDB一般使用"bgsave"命令,自动触发默认使用的就是"bgsave"命令
2、执行"bgsave"命令,Redis会判断是否存在正在执行 RDB的子进程,如果存在了则直接返回
3、父进程fork完之后,"bgsave"命令将会返回"Backgroud saving started" 之后就不再阻塞父进程了。
4、Redis将RDB文件保存在dir配置的指定的目录下,并且文件名为配置的dbfilename,也可以通过执行config set dir {dirpath}与config set dbfilename {新的文件名字}
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# The filename where to dump the DB
dbfilename dump.rdb
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /redis/log
持久化机制之AOF
AOF持久化是以独立的日志记录每次写命令,重启Redis的时候再重新执行AOF文件中命令以达到恢复数据,所以AOF主要就是解决持久化的实时性。
1)、所有的写入的命令都会被追加到aof_buf这么一个缓冲区中
2)、接着AOF缓冲区根据对应的同步策略向磁盘做同步的操作,这里说一下同步策略,同步策略可以通过修改redis配置文件中的参数"appendfsync"进行配置。
3)、随着AOF文件变大,定期对文件进行重写操作来压缩文件
4)、Redis服务器重启的时候就会加载AOF文件用来恢复数据
也就是说如果开启了AOF持久化,我们使用redis输入 "set testkey testValue",在AOF的缓冲区就会追加这么一条文本
*3\r\n$3\r\nset\r\n$7\r\ntestkey\r\n$9\r\ntestValue\r\n
这里解释一下Redis使用的协议要求每行使用\r\n分隔,第一行代表参数数量 $3代表有三个参数 set testkey testValue,参数的字节数分别为 3 7 9
2)、接着AOF对缓冲区进行同步操作会按照我们配置的如下策略向磁盘进行同步
redis配置文件参数appendfsync说明
| 可配置的值 | 配置说明 |
|---|---|
| always | 命令写入缓冲区就调用fsync操作同步到AOF文件中 |
| everysec | 命令写入缓冲区后调用系统write操作,fsync同步文件操作由专门的线程每秒调用一次 |
| no | 命令写入缓冲区后调用系统write操作,不对AOF文件做fsync同步,同步操作由系统负责,最迟30秒同步 |
# appendfsync always
appendfsync everysec
# appendfsync no
若我们配置的为always,则每次写入缓冲区都会同步AOF文件,这样会严重影响redis性能,因为普通磁盘Redis支持击败TPS写入
若配置为No,那每次同步AOF文件的周期不可控,,这样如果还没有进行同步,服务就挂了那数据的安全性没法保证了
配置为everysec是最佳的同步策略也是redis默认的同步策略,每秒同步一次,也就是说就算系统宕机了最多丢失1秒的数据并且性能方面也没有太大影响
3)、接着redisr对AOF文件进行定期的重写操作来压缩文件,重写操作也就是只保留写入命令忽略del key hdel key srem key 等,并且将多个命令如 lpush list a lpush list b 合并到一起
4)、在重启redis再加载持久化文件达到恢复数据的目的,这里有个问题就是AOF和RDB都可以用来持久化,那Redis加载持久化文件的顺序是怎样的,Redis默认是加载AOF文件,如果没有AOF才去加载RDB。
RDB与AOF优劣势分析
优势:
RDB只代表某个时间点上的数据快照,所以适用于备份与全量复制,如一天进行备份一次。
Redis再加载RDB文件恢复数据远快于AOF文件,性能上考虑RDB优于AOF,因为我们保存RDB文件只需fork一次子进程进行保存操作,父进程没有对磁盘I/O
劣势:
RDB没办法做到实时的持久化数据,因为fork是重量级别的操作,频繁执行成本过高
RDB需要经常fork子进程来保存数据集到磁盘,当数据集比较大额时候,fork的过程是比较耗时的,可能会导致redis在一些毫秒级不能响应客服端请求
老版本的Redis无法兼容新版本的RDB文件
优势:
通过配置同步策略基本能够达到实时持久化数据,如配置为everysec,则每秒同步一次AOF文件,也就是说最多丢失一秒钟的数据,兼顾了性能与数据的安全性, AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
劣势:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
与AOF相比,在恢复大的数据时候,RDB方式更快一些
3.HashMap key如何寻址 如何实现的线程安全
HashMap的key值hash化
// >>> 无符号右移,忽略符号位,空位都以0补齐
// ^ 两个操作数的位中,相同则结果为0,不同则结果为1
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
获取key对应的value的方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
4.sychronized 和 reentrantlock 有什么区别
1.API层面
synchronized使用
synchronized既可以修饰方法,也可以修饰代码块。
synchroized修饰代码块时,包含两部分:锁对象的引用和这个锁保护的代码块。如下所示:
public synchronized void test() {
//方法体``
}
synchronized(Object) {
}
ReentrantLock使用
public class test(){
private Lock lock = new ReentrantLock();
public void testMethod()
{
try
{
lock.lock();
……
}
finally
{
lock.unlock();
}
}
}
2.等待可中断
等待可中断是指当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。可等待特性对处理执行时间非常长的同步快很有帮助。
具体来说,假如业务代码中有两个线程,Thread1 Thread2。假设 Thread1 获取了对象object的锁,Thread2将等待Thread1释放object的锁。
使用synchronized。如果Thread1不释放,Thread2将一直等待,不能被中断。synchronized也可以说是Java提供的原子性内置锁机制。内部锁扮演了互斥锁(mutual exclusion lock ,mutex)的角色,一个线程引用锁的时候,别的线程阻塞等待。
使用ReentrantLock。如果Thread1不释放,Thread2等待了很长时间以后,可以中断等待,转而去做别的事情。
3.公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请的时间顺序来依次获得锁;而非公平锁则不能保证这一点。非公平锁在锁被释放时,任何一个等待锁的线程都有机会获得锁。
synchronized的锁是非公平锁,ReentrantLock默认情况下也是非公平锁,但可以通过带布尔值的构造函数要求使用公平锁。
4.锁绑定多个条件
ReentrantLock可以同时绑定多个Condition对象,只需多次调用newCondition方法即可。
synchronized中,锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含的条件。但如果要和多于一个的条件关联的时候,就不得不额外添加一个锁。
5.性能
JDK 1.6 中加入了很多针对锁的优化措施,synchronized与ReentrantLock性能方面基本持平。虚拟机在未来的改进中更偏向于原生的synchronized。
关于synchronized关键字
1.Java中每个对象都有一个锁(lock)或者叫做监视器(monitor)。
ReentrantLock和synchronized持有的对象监视器不同。
2.如果某个synchronized方法是static的,那么当线程方法改方法时,它锁的并不是synchronized方法所在的对象,而是synchronized方法所在对象所对应的Class对象,因为Java中不管一个类有多少对象,这些对象会对应唯一一个Class对象。因此当线程分别访问同一个类的两个对象的两个static,synchronized方法时,是顺序执行的,亦即一个线程先执行,完毕之后,另一个才开始执行。
3.synchronized 方法是一种粗粒度的并发控制,某一时刻,只能有一个线程执行synchronized方法;synchronized块则是一种细粒度的并发控制。只会将块中代码同步,位于方法内,synchronized块之外的代码是可以被多个线程同时访问的。
4.synchronized关键字经过编译之后,会在同步块的前后分别形成monitorenter和monitorexit两个字节码指令,操作对象均为锁的计数器。
5.相同点:都是可重入的。可重入值的是同一个线程多次试图获取它所占的锁,请求会成功。当释放的时候,直到冲入次数清零,锁才释放。
5.volatile关键字的作用
可见性:
可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉。通常,我们无法确保执行读操作的线程能适时地看到其他线程写入的值,有时甚至是根本不可能的事情。为了确保多个线程之间对内存写入操作的可见性,必须使用同步机制。
可见性,是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果。另一个线程马上就能看到。比如:用volatile修饰的变量,就会具有可见性。volatile修饰的变量不允许线程内部缓存和重排序,即直接修改内存。所以对其他线程是可见的。但是这里需要注意一个问题,volatile只能让被他修饰内容具有可见性,但不能保证它具有原子性。比如 volatile int a = 0;之后有一个操作 a++;这个变量a具有可见性,但是a++ 依然是一个非原子操作,也就是这个操作同样存在线程安全问题。
在 Java 中 volatile、synchronized 和 final 实现可见性。
原子性:
原子是世界上的最小单位,具有不可分割性。比如 a=0;(a非long和double类型) 这个操作是不可分割的,那么我们说这个操作时原子操作。再比如:a++; 这个操作实际是a = a + 1;是可分割的,所以他不是一个原子操作。非原子操作都会存在线程安全问题,需要我们使用同步技术(sychronized)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。java的concurrent包下提供了一些原子类,我们可以通过阅读API来了解这些原子类的用法。比如:AtomicInteger、AtomicLong、AtomicReference等。
在 Java 中 synchronized 和在 lock、unlock 中操作保证原子性。
有序性:
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 是因为其本身包含的语义,synchronized 是由
这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行执行。
在没有同步的情况下,编译器、处理器以及运行时等都可能对操作的执行顺序进行一些意想不到的调整。在缺乏足够同步的多线程程序中,要想对内存操作的执行春旭进行判断,无法得到正确的结论。
这个看上去像是一个失败的设计,但却能使JVM充分地利用现代多核处理器的强大性能。例如,在缺少同步的情况下,Java内存模型允许编译器对操作顺序进行重排序,并将数值缓存在寄存器中。此外,它还允许CPU对操作顺序进行重排序,并将数值缓存在处理器特定的缓存中。
Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程。当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的,因此不会将该变量上的操作与其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的变量时总会返回最新写入的值。
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。
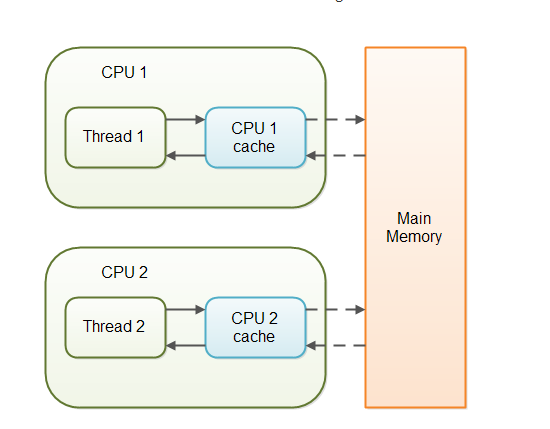
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到CPU缓存中。如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。
。
当一个变量定义为 volatile 之后,将具备两种特性:
1.保证此变量对所有的线程的可见性,这里的“可见性”,如本文开头所述,当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存来完成。
2.禁止指令重排序优化。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置),只有一个CPU访问内存时,并不需要内存屏障;(什么是指令重排序:是指CPU采用了允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理)。
volatile 性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。














 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









