







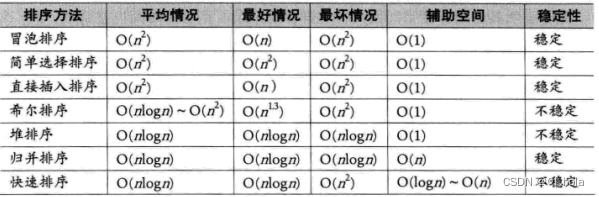
算法的评价从时间复杂度、空间复杂度、稳定性来分析
稳定性:如果排序之前A在A’的前面,排序后A还在A’的前面,则说明算法稳定,可以通过判断算法中有无跳跃交换,没有则稳定
| 4个稳定 | 直接插入 | 冒泡 | 归并 | 基数 | |
| 4个不稳定 | 希尔 | 选择 | 快排 | 堆排序 |
- 以下排序默认排序好都是从大到小滴
1. 冒泡排序(沉石排序)Bubble Sort
- 算法思想
从第一个开始,两两比较,大的向后挪动,第一轮后,最后的元素就是最大的,继续进行下一轮,总共进行len-1轮,每次找待排序中的最大值(每次比较时都不与已排序好的数据进行比较)放到最后
| 时间复杂度 | 空间复杂度 | 稳定 |
|---|---|---|
| O(n^2) | O(1) | 稳定 |
void BubbleSort(int *arr,int len)
{
assert(arr != NULL);
for(int i = 0;i < len-1;++i) //循环次数
{
for(int j = 0;j+1 < len-i;++j) //比较次数
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}
- 优化:如果在其中某一轮时已经完全有序,如何停止,不用继续循环
~ 定义标记位,赋值为真,有交换时将其赋值为假,在每次一趟比较完毕时判断标记是true或false,true说明本趟比较中没有交换,后面的数据都大于之前的数据,说明该排序已经完全有序,则跳出整个循环
void BubbleSort(int* arr, int len) //冒泡排序
{
bool tag = true; //优化标记 如果存在一次交换则tag为假 如果为真则没有交换数据 已经有序
assert(arr != nullptr);
for (int i = 0; i < len - 1; i++)
{
//比较趟数
for (int j = 0; j + 1 < len - i; j++)
{
//每一次的比较 少一个
tag = true;
if (arr[j] > arr[j + 1])
{
//两两比较 前一个大于后一个 交换数据
tag = false; //有交换数据 还不是完全有序 将标记赋为假
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if (tag)
{
//tag为真 说明不存在后面的数据比前面的大,数据已经有序,则跳出循环
break;
}
}
}
2. 直接插入排序(InsertSort)
- 算法思想
从待排序队列中依次取出,放到已排序好的队列中,再次保持有序,重复直到完全有序
默认第一个数据是有序的,每次从下标为1的数据进行插入,取出待插入的数据 tmp,将tmp与它之前的数据从右向左依次比较,当前面的数据大于tmp,则将前面的数据向后移动,直到找到前面的数据小于tmp,就将tmp插入到被比较的元素之后 - 待排序队列越有序,直接插入排序越优解
| 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|
| O(n^2) | O(1) | 稳定 |
void InsertSort(int *arr,int len)
{
assert(arr != NULL); //判空
if(arr == NULL)
{
return ;
}
int tmp = 0;
int j = 0;//j要定义在循环外面 方便tmp插入时找到插入位置
for(int i = 1;i < len;++i)
{
//从待排序队列中取值 i从1开始 0号默认有序
tmp = arr[i];
for(j = i-1;j >= 0;--j)
{
//j从右向左
if(tmp < arr[j])
{
//大于tmp 向后移动一格
arr[j+1] = arr[j];
}
else
{
break;//跳出本层循环
}
}
arr[j+1] = tmp;//放到arr[j]的右边
}
}
3. 希尔排序(shell sort)
由于直接插入排序的时间复杂度高,为了缩小时间复杂度,===>希尔排序
希尔排序 【特殊的直接插入排序】(ShellSort)
算法思想:
缩小增量排序 增量:互素,最后一个增量必须为1
对原始数据进行分组,按增量进行分组,对分出来的组调用直接插入排序,
时间复杂度:O(n1.3)~O(n1.5) 空间复杂度:O(1) 稳定性:不稳定 【数据之间跳跃排序】
通过多次调用直接插入排序
gap[] ={5,3,1};
增量为5 gap = 5 调用直接插入排序
增量为3 gap= 3
增量为1 gap = 1 最后一个增量必须为1
static void Shell(int* arr, int len, int gap)
{
assert(arr != nullptr);
if (arr == NULL)
{
return;
}
int tmp ;
int j ;
for (int i = gap;</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









