







作者:dlutxubo,电子工程师
声明:本文只做分享,版权归原作者,侵权私信删除!
原文:https://zhuanlan.zhihu.com/p/702811733
前言
自从ChatGPT问世以来,人工智能领域经历了一场令人眼花缭乱的变革,特别是在视觉-语言模型(Vision-Language Models, VLMs)的研究和应用上更是如此。VLMs通过结合视觉感知能力和自然语言理解能力,已经在诸如图像描述、视觉问答以及图像和视频的自动标注等多个方面展示出其惊人的潜力和应用价值。随着技术的不断进步,VLMs在处理复杂视觉和语言任务时的性能得到了显著提升,同时也为解决现实世界问题提供了新的视角和工具。
在过去的一年中,VLM技术取得了飞速发展。本文旨在对这些技术进步进行梳理与思考,但将避免深入具体的论文细节,而是用简明扼要的方式介绍每篇研究的核心思想。若想了解更多细节,可参考相关论文的链接。
1. 整体进展
引言:ChatGPT等语言模型没有视觉处理能力,大家认为实现强大的视觉模型可能还需要一段时间。然而,2023年3月份发布的GPT-4彻底改变了这一预期。GPT-4不仅刷新了多个榜单记录,还展现出很强的图片理解能力。此外,相比ChatGPT,关于GPT-4的资料相对更少,使其更显神秘。
2022年11月,OpenAI发布了ChatGPT 3.5,一经推出便引起了轰动。紧接着在2023年3月,OpenAI发布了支持多模态输入的GPT-4,并展示了其强大的图像理解能力。这一突破立即在学术界引发了热烈反响,Vision-Language Models (VLMs) 的相关研究工作迅速增长。正如下图所示,无论是开源还是闭源的模型,都层出不穷,更新速度令人目不暇接。
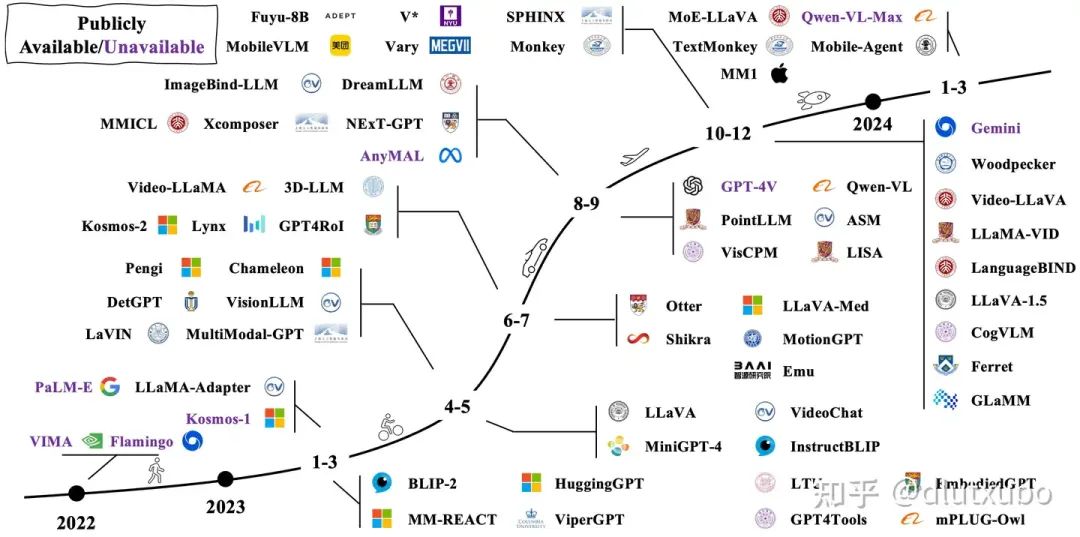
from BradyFU (update on April 2, 2024)
从opencompass[1]榜单上可以看到,尽管GPT-4在模型效果上表现卓越,但追赶它的速度也很快。许多新发布的模型正迅速缩小与GPT-4之间的差距,不断刷新我们的预期。
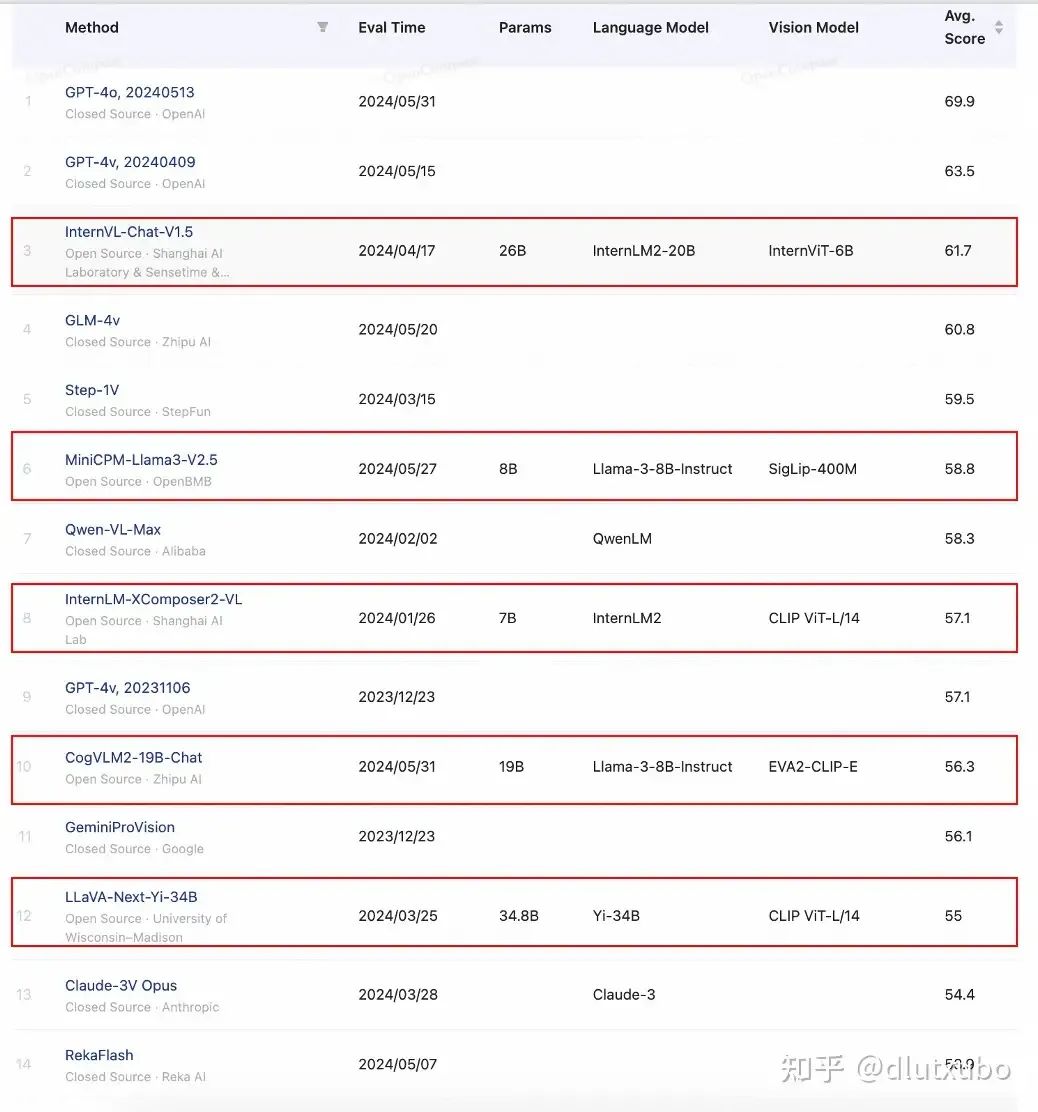
红框内为开源模型 from opencompass
从榜单中可以清晰地看到以下几点:
-
• GPT-4毫无争议地排名第一,尤其是最近发布的GPT-4o版本表现尤为突出
-
• 其他相关模型也在快速追赶,并在榜单上超过了GPT-4v 20231106版本
-
• 虽然国内模型相对OpenAI的产品还有一定差距,但与其他国外厂商如谷歌的GeminiVision相比,仍处于同一梯队
-
• 令人欣喜的是,许多开源模型在榜单上也名列前茅,甚至超过了一些闭源模型
以开源模型internvl-chat-1.5为例,其在文档问答、图片描述、图片问答的能力令人印象深刻。相关效果示例如下图:

但需要注意的是:
-
• 大模型的评估本身也是一件复杂的任务,评估方法和指标还在不断完善中。因此,上述OpenCompass榜单上的指标只能作为参考,实际应用中哪个大模型表现更好还需要在具体业务场景中进行实测
-
• 模型输出中仍然存在幻觉、输出不稳定和泛化性问题,特别是对于一些较小的模型,这些问题更加明显
-
• 当前的视觉大模型在处理速度上依然存在较大限制,因此在现阶段的许多业务应用中,使用小模型仍然是更可行的选择
这些挑战提醒我们,在享受VLMs快速发展的同时,也需要理性对待其当前的局限和不足。
小结:开源vlms从最初的Demo级别,迅速发展到现在许多业务中都已具备实际使用的能力,近一年进展可谓飞速。接下来,我们将探讨一下VLMs在过去一年中取得的进步,以及哪些方面仍需持续改进。
2. 代表性工作-LLaVA
引言:回顾一下代表性工作LLaVA,可以帮助我们更好地理解VLMs的基本范式,并分析其存在的问题以及近一年来的相关改进。
LLaVA(2304)[2]作为VLMs的代表性工作,只需要几个小时的训练,即可让一个LLM转变为VLM。低成本训练,代码数据全部开源,极大的助力了社区对于VLMs的探索。
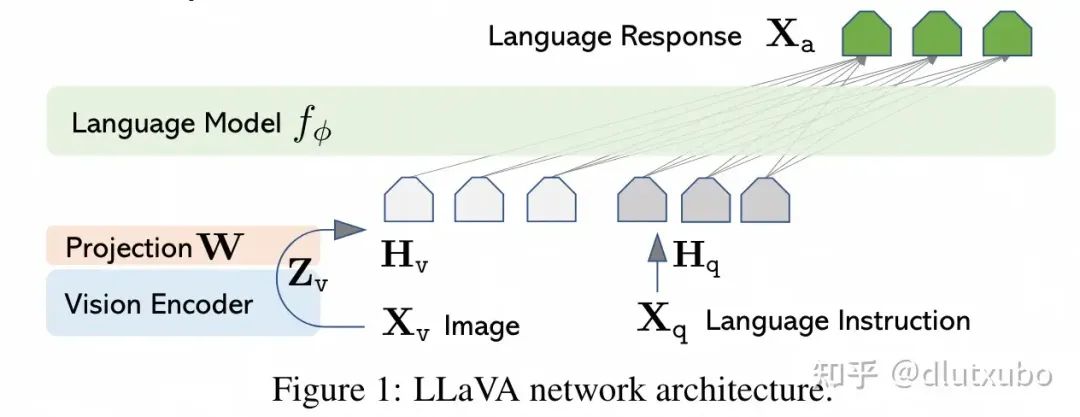
LLaVA在模型结构上十分简洁,将视觉图像视作一种“外语”,利用vision-encoder和projection将“图像翻译成文本信号”,并微调LLM适应图像任务。
-
• Vision-Encoder: ViT-L/14
-
• Projection:单个线性层,后续改为两层MLP
-
• LLM:Vicuna-7B
训练数据包括:
-
• 预训练数据:过滤CC3M后得到的595K image-text caption pairs数据
-
• SFT数据:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4666
4666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











