






Postgresql数据库使用
CREATE TABLE employee (
id varchar(32) PRIMARY KEY,
name VARCHAR(50),
dept varchar(300),
salary numeric(10,2)
);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三一',3000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三二',3000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三三',9000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三四',8000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三五',7000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三六',6000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三七',5000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三八',4000);
1、ROW_NUMBER
Postgresql数据库使用
CREATE TABLE employee (
id varchar(32) PRIMARY KEY,
name VARCHAR(50),
dept varchar(300),
salary numeric(10,2)
);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三一',3000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三二',3000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三三',9000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三四',8000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三五',7000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三六',6000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三七',5000);
insert into employee values("replace"(uuid_generate_v4()||'', '-', ''),'张三八',4000);
1、ROW_NUMBER(窗口函数)
row_number是一个排名函数,over 后面的参数解释。
partition by dept 根据部门字段分组
order by salary desc 根据salary字段倒序排序,然后对结果进行排名。
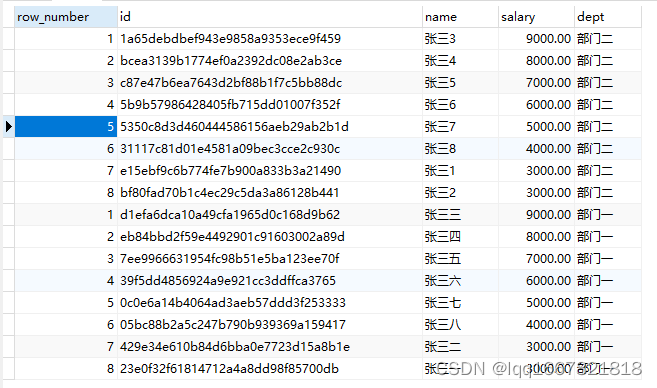
----对每个部门的工资进行排序,工资一样的随机排序,不影响排名的连续性
select row_number() over(partition by dept order by salary desc),* from employee ;
查询结果如下:
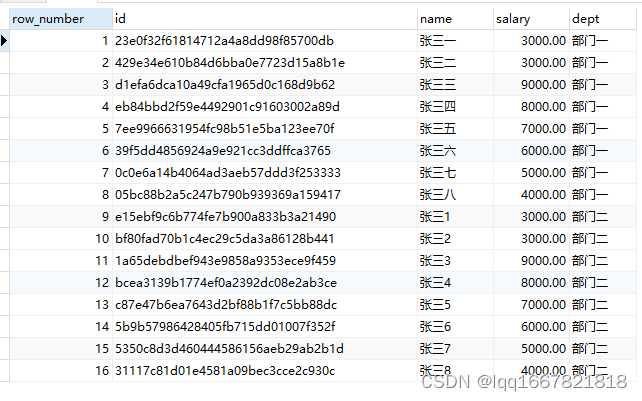
----对所有的字段进行随机排名
select row_number() over(),* from employee;
查询结果如下:
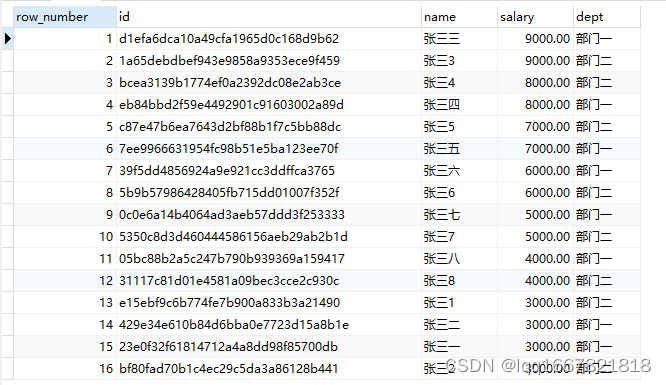
----对工资进行倒序排名,工资相同的随机排序,不影响排名的连续性
select row_number() over(order by salary desc),* from employee ;
查询结果如下:
2、RANK(窗口函数)
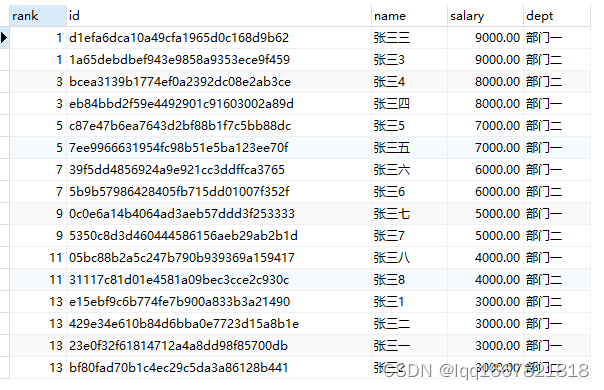
rank的用法同row_number一致,只不过排名上有些区别。他对相同的排名会进行并列处理,下一个排名会有一个跳跃式的排序,以下例进行解释:
----如下图结果,rank的排名是并列的处理方式,张三三和张三3工资并列第一,但是下一个排名从3开始了,因为张三三和张三3占用了两个名额
select rank() over(order by salary desc),* from employee ;
查询结果:
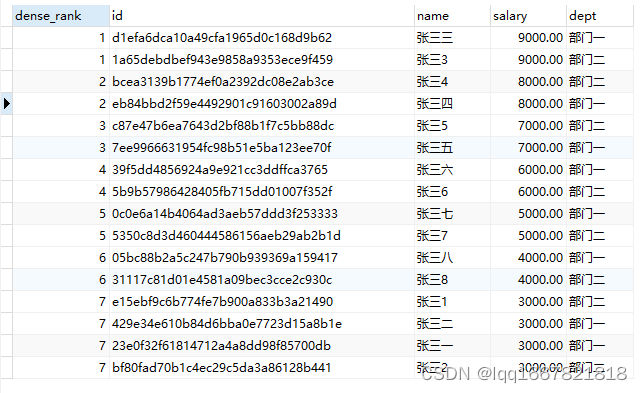
3、DENSE_RANK(窗口函数)
dense_rank的用法和rank,row_number一致,只不过排名方式上有些区别,dense_rank没有跳跃式的排序,他是连续性的,以下例进行解释:
----张三三和张三3并列第一,张三4和张三四并列第二,他的排名是有连续性的
select dense_rank() over(order by salary desc),* from employee ;
查询结果:
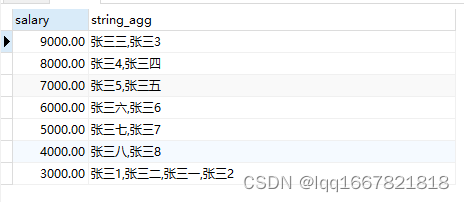
4、STRING_AGG(聚合函数)
----将相同工资的人的名字连在一起,名字之间用英文逗号连接,(得到的是字符串),并且根据工资进行排序
select salary,string_agg(name,',') from employee group by salary order by salary desc ;
结果如下:
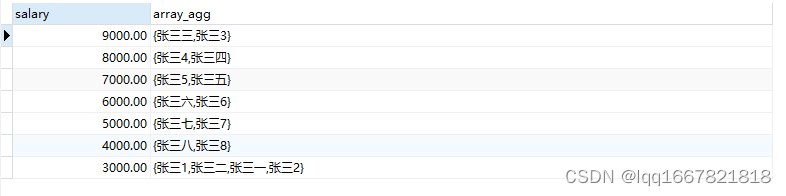
5、ARRAY_AGG(聚合函数)
----将相同工资的人的名字放在同一个数组里面(得到的是数组类型),并且根据工资进行排序
select salary,array_agg(name) from employee group by salary order by salary desc ;
结果如下:
6、STRING_TO_ARRAY,将字符串转数组
----- ns字段有上述可知是一个字符串,由,链接。
with temp as (
select salary,string_agg(name,',') as ns from employee group by salary order by salary desc
)
----可以将ns字符串转数组,分隔符是,
select salary,string_to_array(ns, ',') as name from temp;
结果如下:

7、UNNEST,可以做到行转列
将例子6的结果,可以进行行转列。效果如下:
with temp as (
select salary,array_agg(name) as ns from employee group by salary order by salary desc
)
select salary,unnest(ns) as name from temp;
结果如下:
















 2733
2733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









