







博主一直想研究爬虫,可惜并没有很好的机会,乘着双休日没事,学着写了一个非常简单的小爬虫。
本爬虫使用Jsoup,Jsoup主要是简化连接和选择取内容的代码,抓取的是知乎日报首页上的文章。
其实大家都知道,互联网上显示的内容都最终都是由HTML构成的,说以写爬虫最主要的工作就是分析网页代码的结构,知乎日报首页的结构如下:
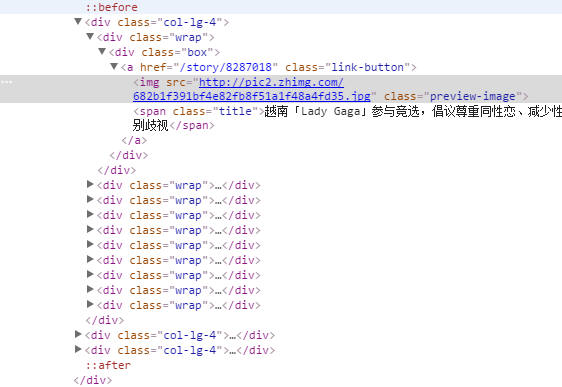
经分析得知,每一个col-lg-4类对应着每一列,共有三列,每个wrap或box或link-button类都可以代表一篇文章。我们要做的工作就是将文章里的标题取出来,然后在取出文章对应链接里面的内容。我们现在已经可以用wrap,box,link-button等获得文章的标题(越南「Lady Gaga」参与竞选,倡议尊重同性恋、减少性别歧视)和文章的链接(/story/8287018),下一步就是获取链接里的内容,打开链接,我们得到如下结构:
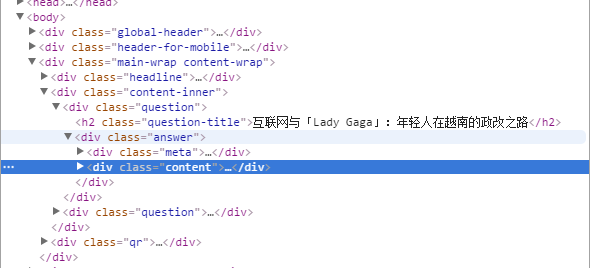
这里就要看大家想怎么抓取了,content类只包含内容,没有作者,标题。如果想把这些也抓取进来,可以选着question类。我选着的是content类。
代码如下
import org.jsoup.Connection;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3556
3556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









