







相关用法:
find_all:find_all
find_next:find_next
strip() 方法用于移除字符串头尾指定的字符(默认为空格)。
目的:获取书名和价格
爬取网站地址:https://www.packtpub.com/all
一、书名

书名在<div class="book-block-title" itemprop="name">的标签中,使用find_all找到所有匹配结果出现的地方,通过<tag>.string 找到标签内的字符串。
二、价格
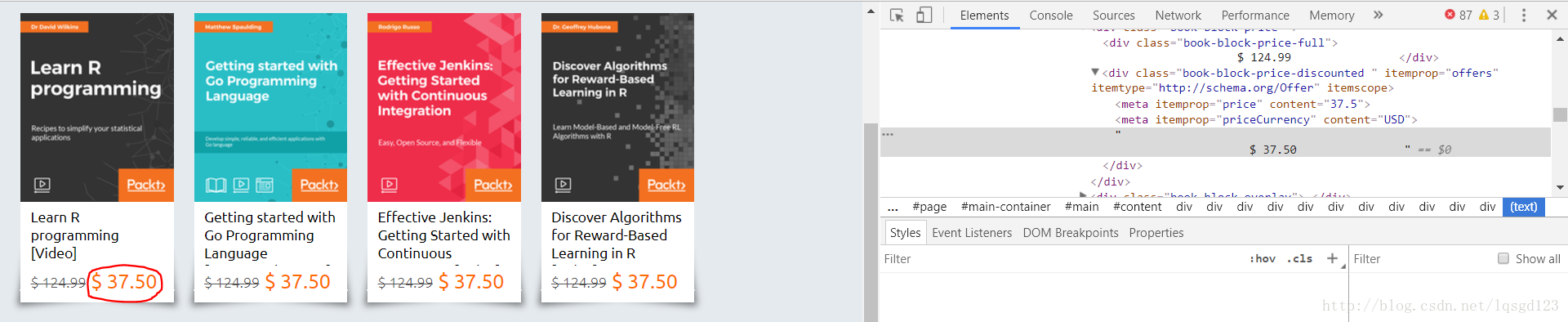
书的价格独立于如何标签之外,无法直接通过<tag>.string 找到标签内的字符串,需要用到正则表达式。
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 26 17:28:21 2017
@author: 81294
"""
import urllib
import datetime
from bs4 import BeautifulSoup
import re
starttime = datetime.datetime.now()
url = "https://www.packtpub.com/all"
page = urllib.request.urlopen(url)
soup_packtpage = BeautifulSoup(page,'html.parser')
page.close()
endtime = datetime.datetime.now()
print(endtime - starttime)
starttime = datetime.datetime.now()
all_book_title = soup_packtpage.find_all("div", class_="book-block-title")
all_book_price = soup_packtpage.find_all("div", class_="book-block-price-discounted ")
a = []
b = []
all_book_prices = re.compile(u"\s+.\s+\d+.\d+")
for book_title in all_book_title:
c = book_title.string.strip()
a.append(c)
for book_price in all_book_price:
book_prices = book_price.find_next(text=all_book_prices)
d= book_prices.strip().replace(' ' ,'')
b.append(d)
for book in range(len(a)):
print("The price of " '《' '{0}' '》' " is " '{1}' .format(a[book],b[book]))
endtime = datetime.datetime.now()
print(endtime - starttime)结果:
















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









