







编写网络爬虫需要:
掌握requests
掌握BeautifulSoup
正文内容的抓取
获取网页url的id(函数或者正则表达式)
爬取前的准备
打开cmd窗口,进入python安装目录 下载python,配置环境(可使用anocanda,里面提供了很多python模块)
BeautifulSoup的导入:pip install BeautifulSoup4
requests的导入:pip install requests
pandas的导入:pip install pandas
在导入过程中出现Traceback (most recent call last):
File “地址”, line 367, in _error_catcher这类in _error_catcher的错误然后百度之后知道需要使用镜像的pip源,下面是一些比较常用的国内镜像包括:
(1)阿里云 http://mirrors.aliyun.com/pypi/simple/
(2)豆瓣http://pypi.douban.com/simple/
(3)清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
(4)中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
(5)华中科技大学http://pypi.hustunique.com/
使用之后豆瓣实在是太慢了 清华大学的非常快
导入方法pip install BeautifulSoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
然后开始爬虫的简单示例

首先导入两个包,然后获取地址,使用utf-8避免中文乱码
下面是在python中使用requests包中get方法的小例子
#requests.get示例
import requests
res=requests.get(‘http://www.baidu.com/’) res.encoding=‘utf-8’ #这一句是为了避免中文乱码
print(res) #输出结果是<Response [200]>,可知resquests.get返回回复的数量,而不是回复的内容
print(res.text) #因此加上“.text”才是得到网页内容

看着实在是太乱了于是需要把HTML的标签去掉这时候就使用到了 BeautifulSoup 首先需要导入包 from bs4 import BeautifulSoup 然后把需要处理的内容放到一个字符串里
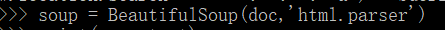 ,然后用BeautifulSoup方法处理,doc就是字符串的命名,指定解析器html.parser 。输出的时候也是需要.text才可以显示内容
,然后用BeautifulSoup方法处理,doc就是字符串的命名,指定解析器html.parser 。输出的时候也是需要.text才可以显示内容
BeautifulSoup的其他使用示例如查找指定标签中的内容例如查找div里面的内容

把内容定义为header使用select方法,print(header)是直接回传Python的一个list
 这样才是打开回传的list里面的第一个元组的内容
这样才是打开回传的list里面的第一个元组的内容















07-08
 7626
7626
7626
05-27
2572
2572
08-08
734
734
09-17
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









