







一. pypy
pypy 基于jit静态编译,相比cpython 动态解释执行,因此执行速度上会更高效,同时减少了内存使用。
对三方包的支持一直是pypy的软肋,特别是一些科学计算包,不过在最新的 pypy5.9 中终于对Pandas和NumPy提供了支持。
一个简单的例子:
test1:
import time
t = time.time()
i = 0
for i in xrange(10**8):
continue
print time.time() - t
test2:
import time
t = time.time()
i = 0
for i in xrange(10**8):
i = i + 1
print time.time() - t
| case | pypy | Cpython |
|---|---|---|
| test1 | 0.25s | 4.3s |
| test2 | 0.25s | 10s |
tips:
不难发现,在 pure python 的测试中,一些场景会有几十倍的性能提升。
不过在Pandas和NumPy的性能测试中,发现pypy会比Cpython慢4x-5x。
可以使用Numpypy替代NumPy,性能又能得到提升:
原因参考:https://morepypy.blogspot.com/2017/10/how-to-make-your-code-80-times-faster.html
二. PySpark
在python driver端,SparkContext利用Py4J启动一个JVM并产生一个JavaSparkContext
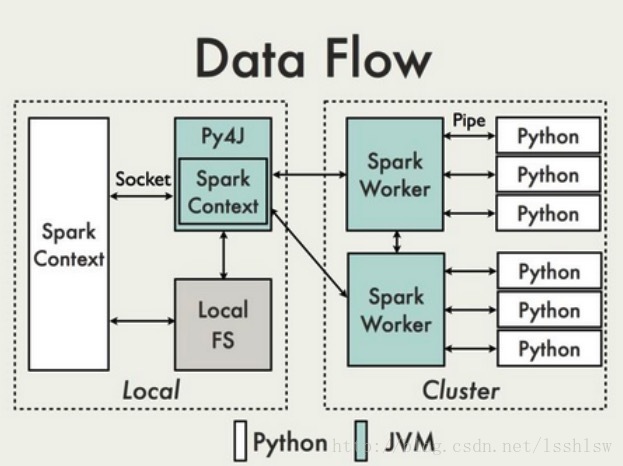
RDD在python下的转换会被映射成java环境下PythonRDD。在远端worker机器上,PythonRDD对象启动一些子进程并通过pipes与这些子进程通信。
使用 pypy 则是将与SparkWorker通信的Cpython进程替换成pypy进程。
三. pypy on PySpark
可以在 Spark-env.sh 中设置 export PYSPARK_PYTHON =/path/to/pypy 或者提交程序时指定--conf spark.pyspark.python=/path/to/pypy等方式进行提交。
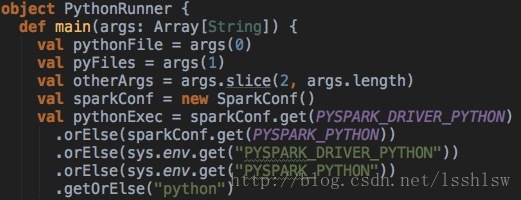
加载python执行环境的代码:
性能测试:
//filter
rdd.filter(lambda x:x['addr'] != 'beijing')
//map
import re
def simpleMobileVerify(phone):
p2 = re.compile('^0\d{2,3}\d{7,8}$|^1[358]\d{9}$|^147\d{8}')
phonematch = p2.match(phone)
if(phone):
return phone
else:
return None
rdd.map(lambda x:simpleMobileVerify(x['accountMobile'])).filter(lambda x : x != None)
| case | pypy | Cpython |
|---|---|---|
| filter | 60s | 67s |
| map | 11s | 22s |
在filter这种IO密集型的任务中提升不大,在计算密集型的任务中提升较为明显,提升比例与计算复杂度成正相关。
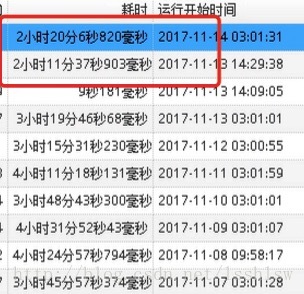
下图为一个计算指标任务的执行时间,其中红框部分使用pypy调度:
四. 结语
在真实的pySpark任务中,根据不同类型的任务提升幅度不同,可以根据不同的业务场景以及使用的三方包,使用Cpython和pypy。
其他的性能对比可以参考:
http://emptypipes.org/2015/01/17/python-vs-scala-vs-spark/















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









