






主成分分析
主成分分析,是一种降维的分析方法,其考察多个变量间相关性的一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关。
为什么要降维
1)多重共线性--预测变量之间存在一定程度的相关性。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
2)高维空间本身具有稀疏性。
3)过多的变量会妨碍查找规律的建立。
4)仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量的绑定才可以反映数据某一方面特征。
主成分满足的条件:
1)每个主成分P都是原变量的线性组合,有多少个原变量就有多少个主成分,任意主成分可以表示成:

2)公式中的未知系数aij满足平方和为1;
3)P1是线性组合中方差最大,依次是P2,P3,...Pm,并且各主成分之间互不相关。
主成分分析过程
1)数据预处理,可以直接使用原始数据也可以使用相关系数矩阵;
2)选择主成分的个数(可有三种方法参考,1:保留特征值大于1的主成分;2:碎石图,在图形变化最大处之上的主成分均可保留;3:平行分析,将真实数据的特征值与模拟数据的特征值进行比较,保留真实数据的特征值大于模拟数据的特征值的主成分)
3)提取主成分
4)主成分旋转,当提取多个主成分时,对它们进行旋转可使结果更具解释性
5)解释结果
6)计算主成分得分
应用
主成分分析使用psych包中的principal()函数,以下是该函数中参数的解释:
principal(r, nfactors = 1, residuals = FALSE,
rotate="varimax",n.obs=NA, covar=FALSE,
scores=TRUE,missing=FALSE,
impute="median",oblique.scores=TRUE,
method="regression",...)
r指定输入的数据,如果输入的是原始数据,R将自动计算其相关系数矩阵;
nfactors指定主成分个数;
residuals是否显示主成分模型的残差,默认不显示;
rotate指定模型旋转的方法,默认为最大方差法;
n.obs如果输入的数据是相关系数矩阵,则必须指定观测样本量
covar为逻辑参数,如果输入数据为原始数据或方阵(如协方差阵),R将其转为相关系数矩阵;
scores是否计算主成分得分;
missing缺失值处理方式,如果scores为TRUE,且missing也为TRUE,缺失值将被中位数或均值替代;
impute指定缺失值的替代方式,默认为中位数替代;
method指定主成分得分的计算方法,默认使用回归方法计算。
#搜集数据,数据来源于吴喜之老师的PPT
x1 <- c(5700,1000,3400,3800,4000,8200,1200,9100,9900,9600,9600,9400)
x2 <- c(12.8,10.9,8.8,13.6,12.8,8.3,11.4,11.5,12.5,13.7,9.6,11.4)
x3 <- c(2500,600,1000,1700,1600,2600,400,3300,3400,3600,3300,4000)
x4 <- c(270,10,10,140,140,60,10,60,180,390,80,100)
x5 <- c(25000,10000,9000,25000,25000,12000,16000,14000,18000,25000,12000,13000)
my.data <- data.frame(x1 = x1, x2 = x2, x3 = x3, x4 = x4, x5 = x5)
其中,x1为总人口数;x2为雇员总数;x3为中等校平均校龄;x4为专业服务项目数;x5为中等房价。
#加载psych包
library(psych)
#选择主成分数目
fa.parallel(x = my.data, fa="pc")
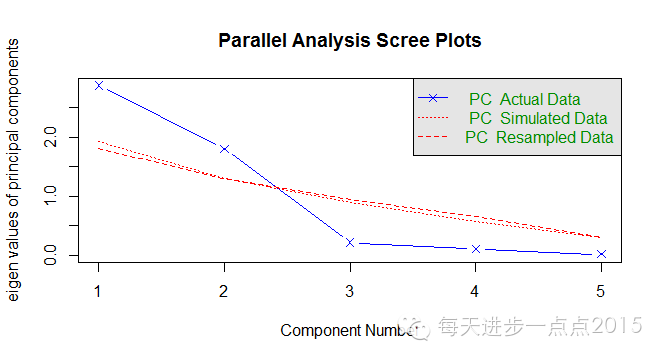
由上图的结果可知,这里选择2个主成分。
#提取主成分
pc <- principal(r = my.data, nfactors = 2, rotate = 'none')
pc
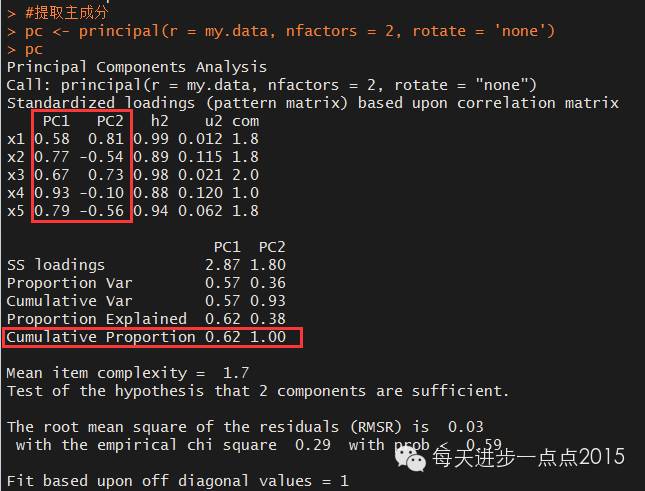
principal函数默认对原始数据进行相关系数矩阵的转换,并且这里指的不进行主成分的旋转。PC1和PC2为成分载荷,为变量与主成分的相关系数,可以将系数写成上文中提到的主成分公式。h2为主成分对每个变量的方差解释度,u2为主成分无法解释的比例。从上图可知,第一主成分解释了5个变量的62%的方差,第一和第二主成分则完全解释了5个变量的方差。
#旋转主成分,这里使用最常用的方差极大正交旋转法
rc <- principal(r = my.data, nfactors = 2, rotate = 'varimax')
rc

通过最大方差法的旋转,发现与之前的PC1,PC2值变化很大,而且更容易的找出主成分主要由哪些变量解释,这里PC1可由x2、x4和x5变量来解释,而PC2可由x1和x3变量来解释。
#计算各主成分的得分
spc <- principal(r = my.data, nfactors = 2, rotate = 'varimax', scores = TRUE)
scores <- spc$scores
scores
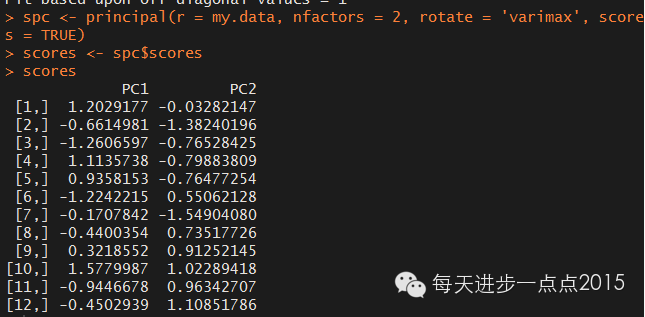
一般可以通过各主成分的评分为观测打上综合得分,权重的设置可用特征根的值确定。
因子分析
因子分析也是一种降维技术,通过降维来挖掘隐藏在数据中无法观测的变量,这些变量可以解释可观察变量的相关性。因子分析与主成分分析最大的不同在于每个自变量是因子的线性组合,具体数学表达式可表示为:
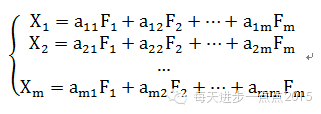
有关因子分析的过程与主成分基本一致,这里不再重复。
应用
因子分析使用psych包中的fa()函数,以下是该函数中参数的解释:
fa(r,nfactors=1,n.obs = NA,n.iter=1, rotate="oblimin",
scores="regression", residuals=FALSE, SMC=TRUE,
covar=FALSE,missing=FALSE,impute="median",
min.err = 0.001, max.iter = 50,symmetric=TRUE,
warnings=TRUE, fm="minres",alpha=.1,p=.05,
oblique.scores=FALSE,np.obs,use="pairwise",cor="cor",...)
r为输入数据,可以是原始数据或协方差矩阵或相关系数矩阵,如果是原始数据,R将计算其相关系数矩阵,如果是协方差矩阵,也会将其转为相关系数矩阵,除非covar为TRUE;
nfactors指定因子个数,默认为1个因子;
n.iter使用自助法进行因子分析,可以指定迭代次数,默认为1次;
rotate指定因子旋转的方法,默认为最小倾斜法进行旋转;
scores使用回归方法计算因子得分;
residuals计算因子模型的残差,默认不计算;
SMC使用多重相关系数平方或1作为共同度初始值;
n.obs,covar,missing,impute同主成分分析的参数;
min.err指定最低误差值,使变量共同度在迭代过程中小于该值;
max.iter指定收敛时的最大迭代次数;
fm指定提取公因子的方法,默认使用最小二乘法;
这里需要指出的是:如果得到的数据不是原始数据,而是协方差矩阵,可使用cov2cor()函数将协方差矩阵转换为相关系数矩阵。
#选择因子数目
library(psych)
fa.parallel(x = my.data, fa="fa")

在选择因子数目时,值得引起注意的一点是,将特征值大于0的因子保留下来,而非大于1。上图结果显示,这里选择2个因子。
#提取因子(最大似然法(ml)更具良好的统计性质,但有时不会收敛,此时可以使用主轴迭代法(pa))
f <- fa(r = my.data, nfactors = 2, n.obs = 112, fm = 'ml', rotate = 'none')
f
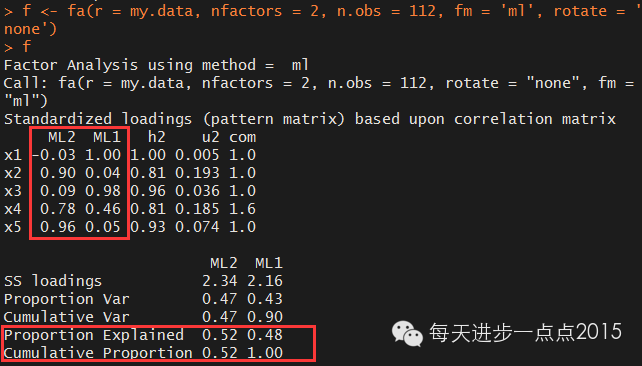
结果框架类似于主成分的返回结果,这里不再详述。
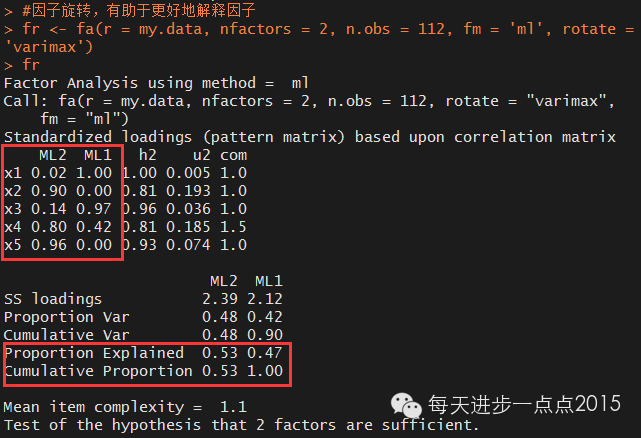
#因子旋转,有助于更好地解释因子
fr <- fa(r = my.data, nfactors = 2, n.obs = 112, fm = 'ml', rotate = 'varimax')
fr
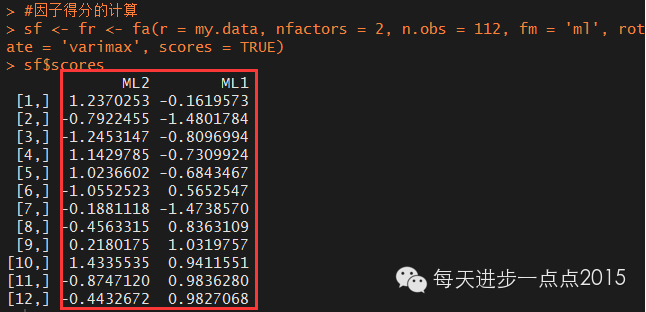
#因子得分的计算
sf <- fr <- fa(r = my.data, nfactors = 2, n.obs = 112, fm = 'ml', rotate = 'varimax', scores = TRUE)
sf$scores
其他关于主成分或因子分析的R包
FactoMineR包不仅提供了PCA和EFA方法,还包含潜变量模型,它有许多principal()函数和fa()函数没考虑的参数选项,如数值型变量和分类变量的使用方法。FAiR包使用遗传算法来估计因子分析模型,它增强了模型参数估计能力,能够处理不等式的约束条件。GPArotation包提供了许多因子旋转方法。nFactors包提供了用来判断因子数目的许多方法。
个人认为主成分和因子分析的结果解释是最为困难的,需要非常了解所分析的数据,包括数据各个维度之间的关联、所属行业的特征等。本文主要是为了使用R语言实现主成分和因子分析,具体相关理论知识可进一步查看下文中的参考资料。
参考资料
[1]统计建模与R语言
[2]R语言实战
[3]http://baike.baidu.com/link?url=bMQWYV3a1MRJou_bXrTYu7W5TnE_2L3-eXPsZOb4Gfr0aEfZjKx-Efcw_CwqLaWYaMeP4_Z0E18twYFSVjaQo_
[4]http://www.cnblogs.com/zhangchaoyang/articles/2222048.html
[5]http://wenku.baidu.com/link?url=_1SjSZMhEfiEy6tfQYy4apZEJBPNUTiJPnJklWRTCVcDF0rZMnsCS08oiSbFwJNmobZtO6GsujBNCwQi56KDfI6QZ4yAbXr-iyHtnJ50OQu
[6]http://blog.sina.com.cn/s/blog_66035a700100hupi.html















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









