






还没关注?

快动动手指!
前言
经过前面几期内容的介绍,相信大家已经把Hadoop的环境搭建好了吧。正如前几期所说,Hadoop的搭建实际上最核心的就是HDFS(文件存储系统)、Map-Reduce(运算系统)和Yarn(资源调配系统)三个组间。
接下来我们将在Hadoop集群的基础上,搭建其他的应用App(如本期所介绍的Hive工具,它的功能是帮助我们使用SQL语句快速完成数据的查询)。Hive框架如下图所示:
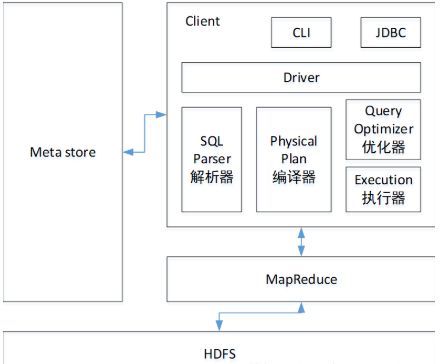
读者可以将Hive理解为中转站,一头连接关系型数据库(如自带的Derby数据库或常用的MySQL数据库),如图中的Metastore,它是用来存储数据的元信息(如表名称、字段名称、字段类型、索引信息等);另一头连接数据的实际存储源,如图中的HDFS。当用户从客户端(如图中的CLI或JDBC)发送一条SQL语句时,会经过包含4个组间的驱动器,分别用于SQL解析(如检查语法是否正确,查询的字段是否包含在元信息中等)、SQL编译(将SQL语法编译成MapReduce认识的语言,即Java语言)、SQL优化和最终的执行(即把优化好的语法通过执行器扔给MapReduce进行数据的运算和抓取)。
在了解了Hive框架后,我们开始在Linux系统中安装Hive工具吧,操作步骤见下文。
解压Hive
首先从Apache网站(http://archive.apache.org/dist/)下载一个稳定版的Hive(如本文使用的是稳定版Hive2.3.4),然后将该软件通过Xftp上传至master机器中,最后要做的就是解压tar.gz软件。
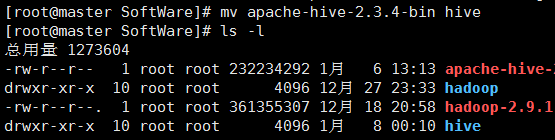
查看上传后的文件

解压tar.gz文件,并重命名为hive
配置Hive
解压完Hive工具后,还需要做几件事情,一个是配置环境变量,这样可以确保在任何一个目录下都可以启动Hive;另一个是修改Hive的配置文件hive-site.xml,这样可以确保Hive的正常工作。
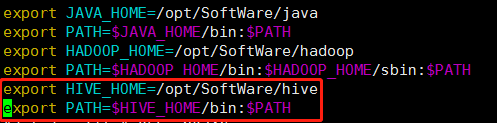
配置Hive的环境变量
vim /etc/profile
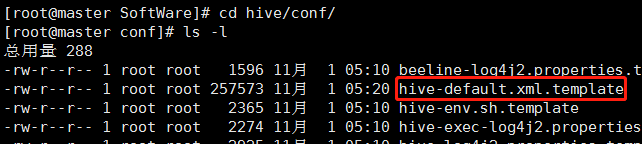
配置hive-site.xml文件
进入到hive的配置目录,发现并没有hive-site.xml文件,但有一个template文件,我们只需要将其复制一份,副本的名称改为hive-site.xml即可。
配置Hive是一件非常头疼的事,在hive-site.xml文件中必须有三处内容需要修改,否则会各种报错。具体操作如下:
修改hive.metastore.schema.verification,将对应的值设置为false,即阻止hive校验HDFS、Map-Reduce和Yarn的版本;
创建一个tmp目录(如/opt/SoftWare/hive/tmp),替换配置文件中的${system:java.io.tmpdir}内容;
替换${system:user.name}为root(根据实际的登录用户,假设root用户登录就换为root);
【个人建议】你可以将Linux系统中的hive-site.xml文件下载到本地主机,然后在本地修改会比较方便哦。修改好后再重新上传至hive的配置目录中。
启动Hive
启动Hive之前需要启动dfs和yarn,因为Hive就是在Hadoop集群之上运行的(具体可以查看Hive框架图),启动命令如下:
start-dfs.sh
start-yarn.sh
由于Hive自带了Derby数据库用于存储数据的元信息,故需要在Hive的目录内初始化Durby数据库,用于启动Hive之后原数据的存储。初始化代码如下:
schematool -initSchema -dbType derby
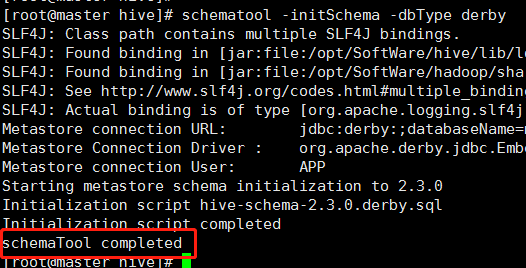
此时,你会发现在Hive目录内会多一个metastore_db目录,紧接着我们就可以启动Hive了,启动过程很简单,直接在Hive目录下输入hive命令即可(千万不能切换目录哦,因为初始化的metastore_db目录在Hive目录内)。

成功启动后会出现"hive>"提示符,这里输入了show databases;语句,用于查询derby包含的数据库名称(仅显示default一个数据库)。接下来我们创建一张表,并把root家目录下的200M+的文件导入到Hive中(数据来源于Kaggle网站,是关于美国911电话呼叫的记录,总计约280万数据)。
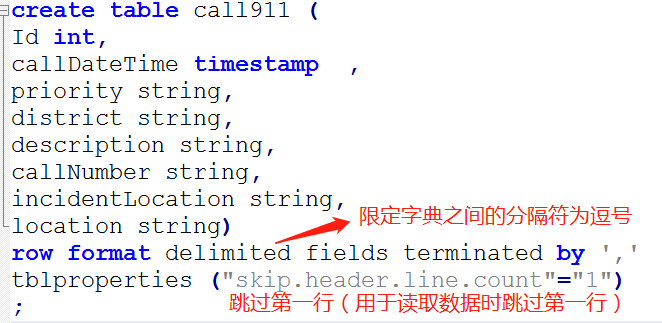
建表语法
导入数据并查询数据

运行过程如下:

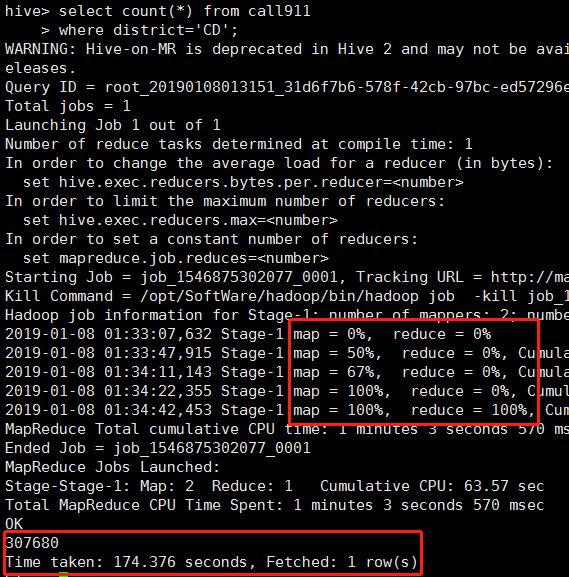
如上图所示,在数据查询过程中能够清晰地看见map和reduce的过程,在经过174秒后,查询出满足条件的307,680条数据(如果你的电脑配置比较高,查询速度会更快哦)。
结语
本期的内容就介绍到这里,下一期我们将介绍Hive的独立式安装,即使用MySQL数据库作为数据元信息的存储(这种场景在实际的应用中最常见)。如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。
每天进步一点点:数据分析1480

长按扫码关注我
















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











