






大部分朋友应该听过“啤酒”和“尿布”的故事——超市分析顾客的商品购买记录,发现“啤酒”和“尿布”经常被一起购买,背后的原因是美国家庭婴儿一般由母亲在家照顾,年轻的父亲到超市购买尿布时会顺便买上自己喜欢的啤酒(暂且不论故事的真实性)。
关联分析可以看做是对多个类别变量做相关性分析,也就是现象(事物)A和现象(事物)B同时出现的频繁程度。比如定义两个事件——A:出现乌云,B:下雨——不考虑事件的先后顺序,从我们的日常生活经验很容易发现,出现乌云的时候,大多数时候都会下雨,也就是说这两个事件是高度关联的。
针对零售购物的关联分析也被称之为购物篮分析(Market Basket Analysis),如上面的“啤酒”和“尿布”的案例。购物篮分析在于发现经常被一起购买的商品组合,对应的业务场景可以是:
优化商品布局,e.g. 超市可以把关联度高的商品摆放在一起,便于顾客一起挑选;
设计促销方案,e.g. 两种关联度高的商品一起搭配购买可以享受价格优惠;
快速商品推荐,通常在电商业务中使用。e.g. 顾客浏览某一商品,页面上会推荐“经常一起购买的产品”或者“90%的顾客也看了如下商品”等规则进行推荐。

注:当当网的图书推荐
关联分析中的关键指标
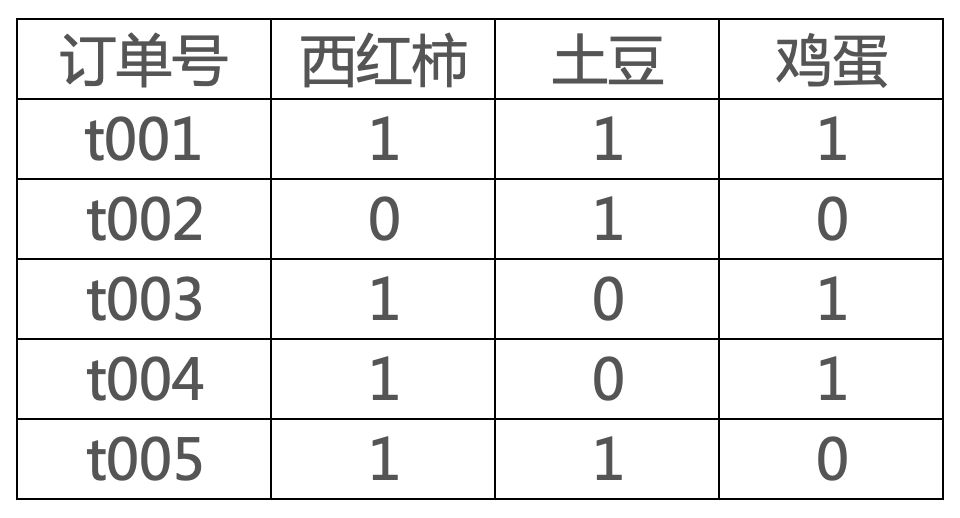
例如,现在有如下交易数据。
定义X,Y是两个不相交的项目(事物或者现象),那么:
支持度(support)表示X,Y同时出现的概率,公式表示如下
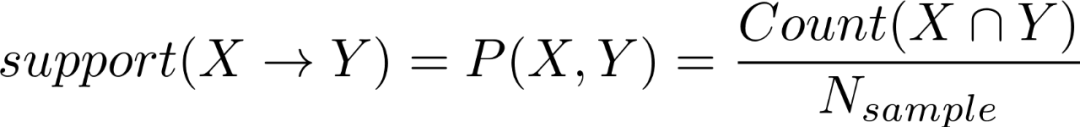
上述表格中西红柿和鸡蛋同时出现的订单数为3,总订单数为5,那么西红柿->鸡蛋的支持度为3/5.
置信度(confidence)表示发生X的集合中,出现Y的概率,即
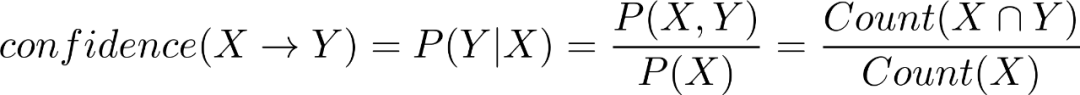
上述表格中西红柿和鸡蛋同时出现的订单数为3,出现西红柿的订单数为4,那么西红柿->鸡蛋的置信度为3/4.
提升度(lift),衡量X,Y之间的相关性,如果lift>1表示两者之间存在关联性(会一起出现);lift=1表示两者之间没有关系(两个事件相互独立);lift<1则表示两者之间可能存在替代性(一方出现,另一方就不出现了)。
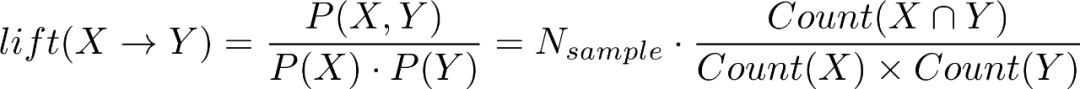
上述表格中总订单数为5,西红柿和鸡蛋同时出现的订单数为3,出现西红柿的订单数为4,出现鸡蛋的订单数为3,那么西红柿->鸡蛋的提升度为
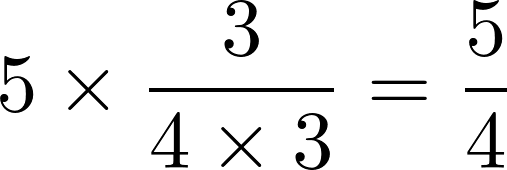 .
.
现在,我们想用关联分析方法来分析近10年来(2010年至今)的国产电影中哪些演员会经常搭档,或者说经常同台演出的演员组合。
第一步,准备数据
我们去豆瓣上抓点数据,目标网址是https://movie.douban.com/tag/#/,可以筛选对应的标签,网页请求返回的数据都是json格式,很容易抓取。
爬虫主体代码如下(headers部分需要配置),单个查询条件下的最大抓取数据量为1W条。
第二步,数据清洗。
注:这里只是进行粗略的清洗,豆瓣对电影的标签可能存在错误。
解析得到的演员信息cast_info是一个列表,查看前5个值,可以看到如下格式的数据:

第三步,关联分析。
先转化成分析要用的数据格式,即一行表示一部电影,列表示演员是否出现(0表示没有出现,1代表出现)。
得到的dataframe如下:

可以看到,列名就是展开的演员名单,其中还有外国演员,需要筛选中文名称的演员,操作如下。
筛选后的数据有9000行左右(电影数),1.3W多列(演员数,也可能有重名的)。
接下来就是见证奇迹的时刻——调用函数来实现关联分析。
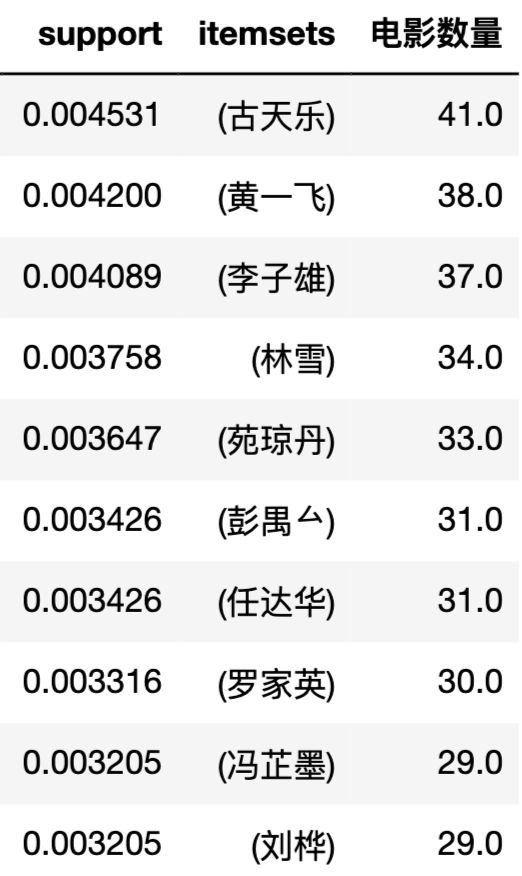
这10年来,拍片最多的演员是?
数据如下,古天乐拍戏真勤劳啊,年均产出4部电影。
最高频出现的演员组合都有谁?
结果如下:
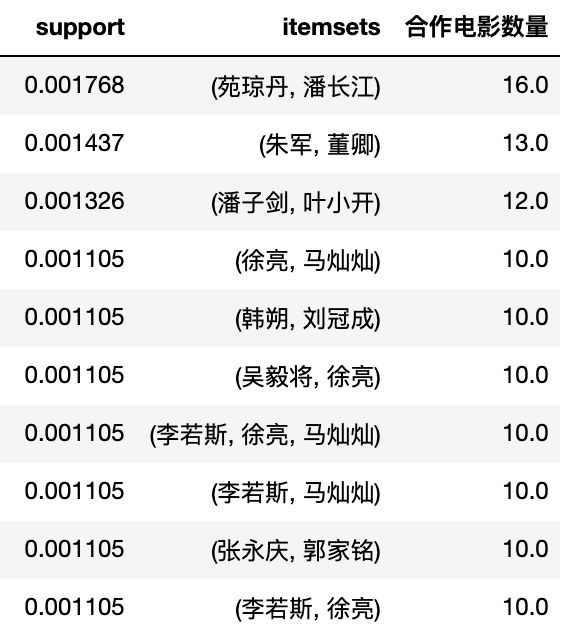
想不到啊想不到,居首位的居然是潘长江老师,看看潘老师近10年的作品:
可以发现有个“连续剧电影”《毛驴县令》出了16部,每部都有潘长江和宛琼丹两位演员,这也是上榜的主要原因。
注:《毛驴县令》系列 https://movie.douban.com/subject_search?search_text=%E6%AF%9B%E9%A9%B4%E5%8E%BF%E4%BB%A4&cat=1002&start=0
董卿和朱军组合的出境倒是有点神奇,说好的电影呢?看了数据才知道,豆瓣是把《春节联欢晚会》也打上了“电影”的标签,而主演就是各位主持人(这波操作……),不过我们也顺带发现了这两位主持人可谓是春晚的“黄金搭档”。
查看关联分析的详细指标数据。
得到的数据如下:
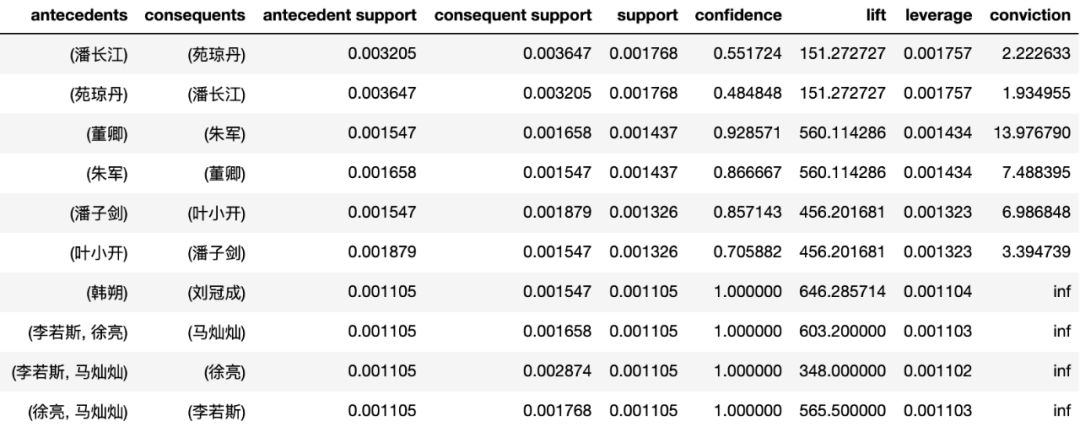
注:上表中的leverage和conviction也是衡量关联度的指标。
【星球伙伴招募】
限时招募100个粉丝登录星球,一起学习和成长!
















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









