







 本文深入探讨了AI/ML中计算和内存需求,包括Conv2D、SeparableConv2D、Dense等层的操作数量和激活数。通过公式解读,分析了各层的权重、偏置、操作数,并比较了计算要求和能耗。讨论了激活函数内存使用、屋顶线模型,以及在minigooglenet模型上的应用,强调了参数压缩和片上存储器的重要性。
本文深入探讨了AI/ML中计算和内存需求,包括Conv2D、SeparableConv2D、Dense等层的操作数量和激活数。通过公式解读,分析了各层的权重、偏置、操作数,并比较了计算要求和能耗。讨论了激活函数内存使用、屋顶线模型,以及在minigooglenet模型上的应用,强调了参数压缩和片上存储器的重要性。
计算操作的数量和操作数的数量估计性能和能耗
Conv2D 函数

权重数:对于每一个(输入和输出)通道对,有一个3*3内核:
3 x 3 x 3 x 128 = 3456 weights
偏移:每个输入通道,有一个偏差,共有:
128偏差
公式解读
(K,K) 内核,F 滤波器,S 步长(stride),P 填充(padding)
输入为:批量bi,高hi,宽wi,通道ci
输出为:
» Bo = Bi
» Co = F
» Ho = (Hi + 2 x P - K) / S + 1
» Wo = (Wi + 2 x P - K) / S + 1
权重和偏移量:
w = Ci x K x K x Co
b = Co
SeparableConv2D
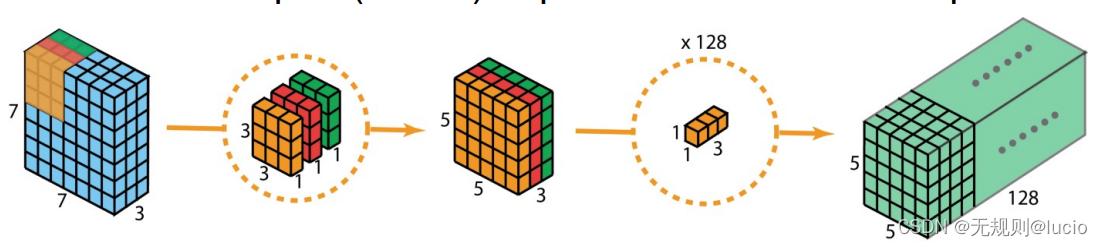
对于depthwise(深度)
权重数:3 x 3 x 3 = 27 weights;
偏移数: 0 (bias not used)
对于pointwise(点式)
权重数:3 x 1 x 1 x 128 = 384 weights
偏移数:128 biases
共有411/128 weights/biases
所以有:
(3456+128)/(411+128) = 6.6x fewer #params
公式解读
与Conv2D有同样的输入输出,但权重和偏移量为:
w = Ci x ( K x K + Co )
b = Co
权重比率(weight ratio):Co/(1+ (Co/K∙K))
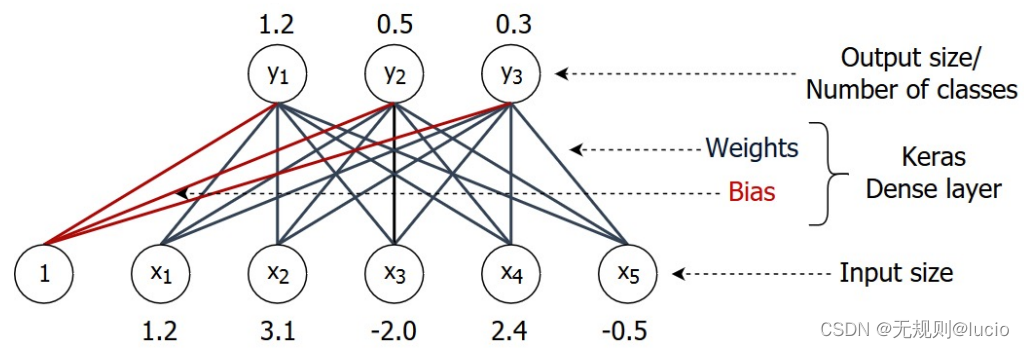
Dense
输入:bi,xi 批量和输入数组尺寸
输出:bo,yo 批量和输出数组尺寸大小
权重数:w = Xi x Yo
偏移量:b = Yo
MaxPooling2D
和Conv2D和SeparableConv2D的输出张量尺寸相同。无可训练参数权重和偏移量
AveragePooling2D
和AveragePooling2D一样。
Batch Normalization
输入:bi,hi,wi,ci。批量,高度,宽度,通道
输出:(Bo,Ho,Wo,Co) = (Bi,Hi,Wi,Ci)
gamma和beta参数可训练:
pt = 2 x Ci = 2 x Co
其他参数,mean和variance不能训练:
p = 4 x Ci = 4 x Co
激活数(#activs)
正常激活数的参数:
- 当激活停留在片上缓冲区,参数存储在外部DRAM中。
- 我们需要在片上给参数留出空间,这样可以在需要它的时候从DRAM中提取参数。
我们需要根据实际数据类型计算出实际的存储需求(memory requirement),为参数和激活函数。
操作的数量(#OPs)
卷积层(convolutional)和全连接层(Full-connected layer)主导操作数量。
MULs和ADDs决定计算的要求(computing requirement)。
Conv2D层的操作数量
输出张量的每个Co x Ho x Wo元件:
MULs: K x K x Ci
ADDs: K x K x Ci
一共2 x Co x Ho x Wo x K x K x Ci个操作
SeparableConv2D层的操作数量
MULs: K x K
ADDs: K x K-1 (no bias addition)
对于Depthwise:
一共有2 x Ci x Ho x Wo x K x K个操作
对于Pointwise:一共2 x Co x Ho x Wo x 1 x 1 x Ci个操作
总共有2 x Ho x Wo x (K x K + Co) x Ci个操作
Dense层的操作数量
MULS: Xi
ADDs: Xi
一共2 x Yo x Xi 个操作
Shallownet Sequential
// 浅谈顺序性
def shallownet_sequential(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" ordering
model = Sequential()
i_s = (height, width, depth)
# define the first (and only) CONV => RELU layer
model.add(Conv2D(32, (3, 3), padding="same", input_shape=i_s))
model.add(Activation("relu"))
# softmax classifier
model.add(Flatten 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









