







今天说一说,线程池,从设计思想到源码解析。
前言
初识线程池
我们知道,线程的创建和销毁都需要映射到操作系统,因此其代价是比较高昂的。出于避免频繁创建、销毁线程以及方便线程管理的需要,线程池应运而生。
线程池优势
- 「降低资源消耗」:线程池通常会维护一些线程(数量为 corePoolSize),这些线程被重复使用来执行不同的任务,任务完成后不会销毁。在待处理任务量很大的时候,通过对线程资源的复用,避免了线程的频繁创建与销毁,从而降低了系统资源消耗。
- 「提高响应速度」:由于线程池维护了一批 alive 状态的线程,当任务到达时,不需要再创建线程,而是直接由这些线程去执行任务,从而减少了任务的等待时间。
- 「提高线程的可管理性」:使用线程池可以对线程进行统一的分配,调优和监控。
线程池设计思路
有句话叫做艺术来源于生活,编程语言也是如此,很多设计思想能映射到日常生活中,比如面向对象思想、封装、继承,等等。今天我们要说的线程池,它同样可以在现实世界找到对应的实体——工厂。
先假想一个工厂的生产流程: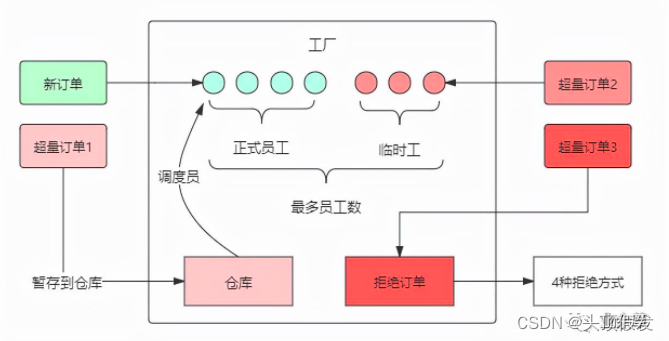
线程池设计思路
工厂中有固定的一批工人,称为正式工人,工厂接收的订单由这些工人去完成。当订单增加,正式工人已经忙不过来了,工厂会将生产原料暂时堆积在仓库中,等有空闲的工人时再处理(因为工人空闲了也不会主动处理仓库中的生产任务,所以需要调度员实时调度)。仓库堆积满了后,订单还在增加怎么办?工厂只能临时扩招一批工人来应对生产高峰,而这批工人高峰结束后是要清退的,所以称为临时工。当时临时工也以招满后(受限于工位限制,临时工数量有上限),后面的订单只能忍痛拒绝了。
我们做如下一番映射:
- 工厂——线程池
- 订单——任务(Runnable)
- 正式工人——核心线程
- 临时工——普通线程
- 仓库——任务队列
- 调度员——getTask()
❝
getTask()是一个方法,将任务队列中的任务调度给空闲线程,在解读线程池有详细介绍
❞
映射后,形成线程池流程图如下,两者是不是有异曲同工之妙?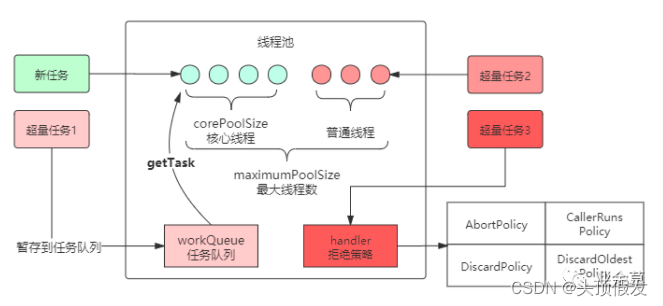
线程池流程图
这样,线程池的工作原理或者说流程就很好理解了,提炼成一个简图: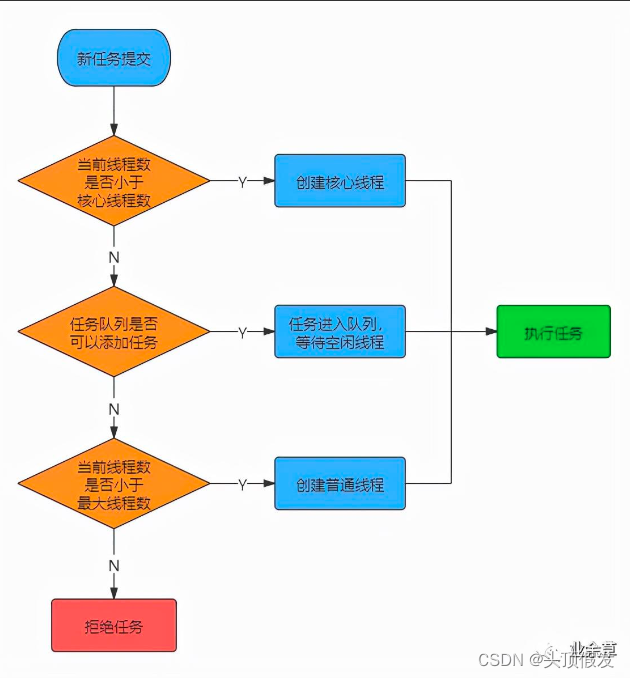
线程池的工作原理
深入线程池
那么接下来,问题来了,线程池是具体如何实现这套工作机制的呢?从Java线程池Executor框架体系可以看出:线程池的真正实现类是ThreadPoolExecutor,因此我们接下来重点研究这个类。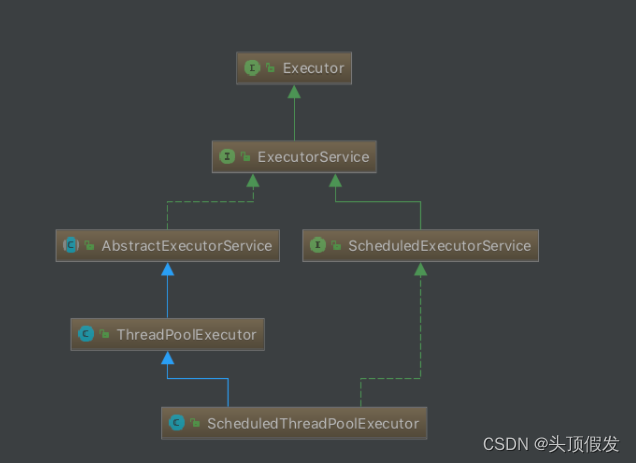
线程池工作机制
构造方法
研究一个类,先从它的构造方法开始。ThreadPoolExecutor提供了4个有参构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
解释一下构造方法中涉及到的参数:
- 「corePoolSize」(必需):核心线程数。即池中一直保持存活的线程数,即使这些线程处于空闲。但是将allowCoreThreadTimeOut参数设置为true后,核心线程处于空闲一段时间以上,也会被回收。
- 「maximumPoolSize」(必需):池中允许的最大线程数。当核心线程全部繁忙且任务队列打满之后,线程池会临时追加线程,直到总线程数达到maximumPoolSize这个上限。
- 「keepAliveTime」(必需):线程空闲超时时间。当非核心线程处于空闲状态的时间超过这个时间后,该线程将被回收。将allowCoreThreadTimeOut参数设置为true后,核心线程也会被回收。
- 「unit」(必需):keepAliveTime参数的时间单位。有:TimeUnit.DAYS(天)、TimeUnit.HOURS(小时)、TimeUnit.MINUTES(分钟)、「TimeUnit.SECONDS(秒)」、「TimeUnit.MILLISECONDS(毫秒)」、TimeUnit.MICROSECONDS(微秒)、TimeUnit.NANOSECONDS(纳秒)
- 「workQueue」(必需):任务队列,采用阻塞队列实现。当核心线程全部繁忙时,后续由execute方法提交的Runnable将存放在任务队列中,等待被线程处理。
- 「threadFactory」(可选):线程工厂。指定线程池创建线程的方式。
- 「handler」(可选):拒绝策略。当线程池中线程数达到maximumPoolSize且workQueue打满时,后续提交的任务将被拒绝,handler可以指定用什么方式拒绝任务。
放到一起再看一下: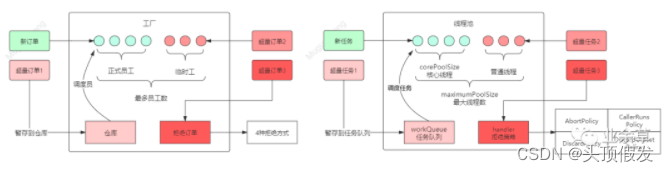
工厂与线程池
任务队列
使用ThreadPoolExecutor需要指定一个实现了BlockingQueue接口的任务等待队列。在ThreadPoolExecutor线程池的API文档中,一共推荐了三种等待队列,它们是:SynchronousQueue、LinkedBlockingQueue和ArrayBlockingQueue;
- 「SynchronousQueue」:同步队列。这是一个内部没有任何容量的阻塞队列,任何一次插入操作的元素都要等待相对的删除/读取操作,否则进行插入操作的线程就要一直等待,反之亦然。
- 「LinkedBlockingQueue」:无界队列(严格来说并非无界,上限是Integer.MAX_VALUE),基于链表结构。使用无界队列后,当核心线程都繁忙时,后续任务可以无限加入队列,因此线程池中线程数不会超过核心线程数。这种队列可以提高线程池吞吐量,但代价是牺牲内存空间,甚至会导致内存溢出。另外,使用它时可以指定容量,这样它也就是一种有界队列了。
- 「ArrayBlockingQueue」:有界队列,基于数组实现。在线程池初始化时,指定队列的容量,后续无法再调整。这种有界队列有利于防止资源耗尽,但可能更难调整和控制。
另外,Java还提供了另外4种队列:
- 「PriorityBlockingQueue」:支持优先级排序的无界阻塞队列。存放在PriorityBlockingQueue中的元素必须实现Comparable接口,这样才能通过实现compareTo()方法进行排序。优先级最高的元素将始终排在队列的头部;PriorityBlockingQueue不会保证优先级一样的元素的排序,也不保证当前队列中除了优先级最高的元素以外的元素,随时处于正确排序的位置。
- 「DelayQueue」:延迟队列。基于二叉堆实现,同时具备:无界队列、阻塞队列、优先队列的特征。DelayQueue延迟队列中存放的对象,必须是实现Delayed接口的类对象。通过执行时延从队列中提取任务,时间没到任务取不出来。更多内容请见DelayQueue:面试官:谈谈Java中的阻塞延迟队列DelayQueue原理和用法。
- 「LinkedBlockingDeque」:双端队列。基于链表实现,既可以从尾部插入/取出元素,还可以从头部插入元素/取出元素。
- 「LinkedTransferQueue」:由链表结构组成的无界阻塞队列。这个队列比较特别的时,采用一种预占模式,意思就是消费者线程取元素时,如果队列不为空,则直接取走数据,若队列为空,那就生成一个节点(节点元素为null)入队,然后消费者线程被等待在这个节点上,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,并唤醒该节点等待的线程,被唤醒的消费者线程取走元素。
拒绝策略
线程池有一个重要的机制:拒绝策略。当线程池workQueue已满且无法再创建新线程池时,就要拒绝后续任务了。拒绝策略需要实现RejectedExecutionHandler接口,不过Executors框架已经为我们实现了4种拒绝策略:
- 「AbortPolicy」(默认):丢弃任务并抛出RejectedExecutionException异常。
- 「CallerRunsPoli
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5702
5702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









