







今天是其他的个技术:Logstash+Kibana,中间穿插着讲解Kafka应用
话不多说,直接上正题
一、 Logstash数据采集工具安装和使用
1. 简介
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
而在官网,对于Logstash的介绍更是完整,我这里就展示一下官网的介绍
输入:采集各种样式、大小和来源的数据
过滤器:实时解析和转换数据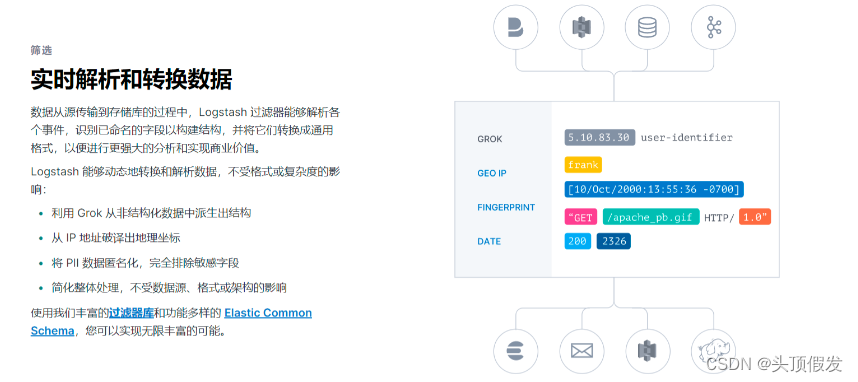
输出:选择你的存储,导出你的数据
而在官网的介绍中,最让我兴奋的就是可扩展性,Logstash 采用可插拔框架,拥有 200 多个插件。您可以将不同的输入选择、过滤器和输出选择混合搭配、精心安排,让它们在管道中和谐地运行。这也就意味着可以用自己的方式创建和配置管道,就跟乐高积木一样,我自己感觉太爽了
好了,理论的东西过一遍就好
ps:不过这也体现出官网在学习的过程中的重要性,虽然都是英文的,但是,现在可以翻译的软件的太多了,这不是问题
2. 安装
所有的技术,不自己实际操作一下是不可以的,安装上自己动手实践一下,毛爷爷都说:实践是检验真理的唯一标准,不得不夸奖一下Logstash的工程师,真的太人性化了,下载后直接解压,就可以了。
而且提供了很多的安装方式供你选择,舒服
3. helloword使用
开始我们今天的第一个实践吧,就像我们刚开始学Java的时候,第一个命令就是helloworld,不知道各位还能不能手写出来呢?来看一下logstash的第一个运行时怎么处理的
通过命令行,进入到logstash/bin目录,执行下面的命令:
input {
kafka {
type => "accesslogs"
codec => "plain"
auto_offset_reset => "smallest"
group_id => "elas1"
topic_id => "accesslogs"
zk_connect => "172.16.0.11:2181,172.16.0.12:2181,172.16.0.13:2181"
}
kafka {
type => "gamelogs"
auto_offset_reset => "smallest"
codec => "plain"
group_id => "elas2"
topic_id => "gamelogs"
zk_connect => "172.16.0.11:2181,172.16.0.12:2181,172.16.0.13:2181"
}
}
filter {
if [type] == "accesslogs" {
json {
source => "message"
remove_field => [ "message" ]
target => "access"
}
}
if [type] == "gamelogs" {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_X" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => [ "message" ]
}
}
}
output {
if [type] == "accesslogs" {
elasticsearch {
index => "accesslogs"
codec => "json"
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
if [type] == "gamelogs& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4681
4681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









