







Improved Word Representation Learning with Sememes
来自:acl2017
网址:https://github.com/thunlp/SE-WRL
代码:https://github.com/thunlp/SE-WRL
Hownet
知网(HowNet)的构建秉承还原论思想,即所有词语的含义可以由更小的语义单位构成,而这种语义单位被称为“义原”(Sememe),即最基本的、不宜再分割的最小语义单位。知网构建了包含 2000 多个义原的精细的语义描述体系,并为十几万个汉语和英语词所代表的概念标注了义原。
论文中给出的例子:

论文贡献
论文利用词语的义原信息来学习更加准确的词表征,这里并不考虑不同义原的在hownet词典中的顺序(顺序与词频有关嘛?)
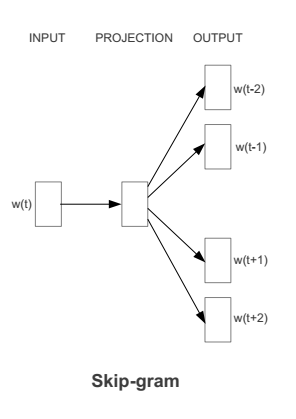
skip-gram模型结构,利用中心词来预测周围词,得到额外的词向量表征。来自论文Efficient Estimation of Word Representations in Vector Space
在skip-gram词向量训练的模型基础上做出改进:
(1) Simple Sememe Aggregation Model (SSA)
模型完全和skip-gram 模型一样,只是在考虑每个单词的时候,考虑义原信息,将义原信息的初始化向量和初始化词向量相加求平均
(2) Sememe Attention over Target Model (SAC)

利用输入词,即target word的信息,将其attention向量来组合每个周围词的多个义原,从而a加强周围词的词表征
(3) Sememe Attention over Target Model (SAT)

利用周围词,获得图中的contextual embedding,作为attention向量来组合输入词的多个义原,从而加强输入词的词表征
在语义相似度计算上的结果:

















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











