






 文章讲述了作者在使用iText库合并PDF时遇到的`PDFheadersignaturenotfound`问题,以及后续对代码进行的分析,包括解决文件占用、流关闭等问题,优化了处理速度和资源管理。
文章讲述了作者在使用iText库合并PDF时遇到的`PDFheadersignaturenotfound`问题,以及后续对代码进行的分析,包括解决文件占用、流关闭等问题,优化了处理速度和资源管理。
目录
1、原文链接:
2、代码分析
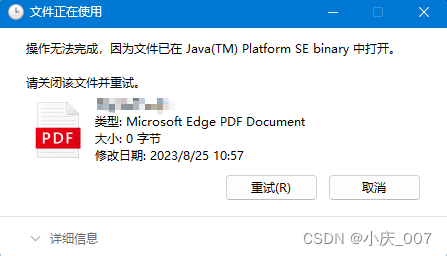
这是我上篇关于 itext 的代码,已经解决了 PDF header signature not found 这个问题。后面分析了一下还是存在很多问题。例如:手动删除文件时被占用,PdfReader 对象循环创建没有完全关闭。FileOutputStream 流没有正确关闭。将文件全部加载到内存中处理速度过快,导致影响 wkhtmltopdf 工具线程还没处理完,主线程就已经跑完了导致的 IO 异常等等
package com.lxq.utils;
import com.itextpdf.text.Document;
import com.itextpdf.text.pdf.PdfCopy;
import com.itextpdf.text.pdf.PdfImportedPage;
import com.itextpdf.text.pdf.PdfReader;
import java.io.FileOutputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
public class PdfUtil {
/**
* author luXiaoQing
* @param filePaths 需要拼接的多个pdf文件路径
* @param outputFilePath 合并后pdf输出路径
* @param outputFileName 合并后pdf文件名
*/
public static void mergePdf(List<String> filePaths, String outputFilePath, String outputFileName) {
if (filePaths.isEmpty()) {
return;
}
if (!Utils.checkNotNull(outputFilePath) || !Utils.checkNotNull(outputFileName)) {
return;
}
Document document = null;
PdfCopy copy = null;
PdfReader reader = null;
try {
List<byte[]> fileBytes = new ArrayList<byte[]>();
for (String filePath : filePaths) {
fileBytes.add(Files.readAllBytes(Paths.get(filePath)));
}
document = new Document(new PdfReader(filePaths.get(0)).getPageSize(1));
copy = new PdfCopy(document, new FileOutputStream(outputFilePath + outputFileName));
document.open();
for (byte[] fileByte : fileBytes) {
reader = new PdfReader(fileByte);
int numberOfPage = reader.getNumberOfPages();
//注意 i 从 1 开始
for (int i = 1; i <= numberOfPage; i++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, i);
copy.addPage(page);
}
}
} catch (Exception e) {
System.out.println(e.getMessage() + e);
} finally {
if (Utils.checkNotNull(document)) {
document.close();
}
if (Utils.checkNotNull(reader)) {
reader.close();
}
if (Utils.checkNotNull(copy)) {
copy.close();
}
}
}
}3、解决问题
package com.lxq.utils;
import com.itextpdf.text.Document;
import com.itextpdf.text.pdf.PdfCopy;
import com.itextpdf.text.pdf.PdfImportedPage;
import com.itextpdf.text.pdf.PdfReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
public class PdfUtil {
/**
* author luXiaoQing
* @param filePaths 需要拼接的多个pdf文件路径
* @param outputFilePath 合并后pdf输出路径
* @param outputFileName 合并后pdf文件名
*/
public static void mergePdf(List<String> filePaths, String outputFilePath, String outputFileName) {
if (filePaths.isEmpty()) {
return;
}
if (!Utils.checkNotNull(outputFilePath) || !Utils.checkNotNull(outputFileName)) {
return;
}
Document document = null;
PdfCopy copy = null;
FileOutputStream fos = null;
File outputFile = new File(outputFilePath + outputFileName);
try {
fos = new FileOutputStream(outputFile);
for (String filePath : filePaths) {
File pdf = new File(filePath);
if (!pdf.exists()) {
throw new IOException("文件" + filePath + "不存在");
}
PdfReader reader = null;
try {
reader = new PdfReader(filePath);
if (document == null) {
//使用第1页的尺寸
document = new Document(reader.getPageSize(1));
copy = new PdfCopy(document, fos);
document.open();
}
int numberOfPage = reader.getNumberOfPages();
//for循环从1开始
for (int i = 1; i <= numberOfPage; i++) {
document.newPage();
assert copy != null;
PdfImportedPage page = copy.getImportedPage(reader, i);
copy.addPage(page);
}
} catch (Exception e) {
System.out.println(e.getMessage() + e);
} finally {
if (reader != null) {
reader.close();
}
}
}
} catch (Exception e) {
System.out.println(e.getMessage() + e);
} finally {
if (document != null) {
document.close();
}
if (copy != null) {
copy.close();
}
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
System.out.println(e.getMessage() + e);
}
}
}
}
}4、使用扩展
我使用这个方法时将我的文件按顺序批量将文件路径添加到了 filePaths 集合中,其中第一个文件是主文件。要求是拼接完成后还是原文件名。所以需要在使用时多一些操作
File oldPdfFile = new File(filePath + fileName);
File newPdfFile = new File(filePath + fileName + ".tmp");
PdfUtil.mergePdf(filePaths, filePath, newPdfFile.getName());
if (!oldPdfFile.delete()) {
throw new IOException("删除文件" + oldPdfFile.getAbsoluteFile() + "失败");
}
newPdfFile.renameTo(oldPdfFile);

















 7066
7066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









