








动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。如果我们能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。我们可以用一个表来记录所有已解的子问题的答案。不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。这就是动态规划法的基本思路。具体的动态规划算法多种多样,但它们具有相同的填表格式。
如果大家对于动态规划不是很熟悉的话,可能看着上面一段文字会不知所云,我一般的学习方法是首先扫描一下基本定义,不深究(有点不求甚解的味道),然后去看一些实例,结合自己的体会,最后再回顾,精读一下定义,这样我对定义才能够真正的理解。下面我们依托一个经典的算法问题来体现上面这段文字的思想,0-1背包问题在算法学习中可谓是必修课程,一般在讲动态规划问题的时候都会用到这个例子。
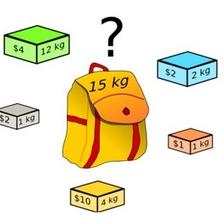
问题描述:一个旅行者有一个最多能用M公斤的背包,现在有N件物品, 它们的重量分别是W1,W2,...,Wn, 它们的价值分别为P1,P2,...,Pn. 若每种物品只有一件 在不超过M公斤的前提下,求旅行者能获得最大总价值的方案。
输入格式:M,N W1,P1 W2,P2 ......
问题分析:最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。用子问题定义状态:即f[i][j]表示前i件物品恰放入一个容量为j的背包可以获得的最大价值。则其状态转移方程便是:f[i][j] = max{f[i-1][j], f[i-1][j-w[i]]+P[i]} 则问题就迎刃而解了。
动态规划算法的基本思想是:将待求解的问题分解成若干个相互联系的子问题,先求解子问题,然后从这些子问题的解得到原问题的解;对于重复出现的子问题,只在第一次遇到的时候对它进行求解,并把答案保存起来,让以后再次遇到时直接引用答案,不必重新求解。动态规划算法将问题的解决方案视为一系列决策的结果,与贪婪算法不同的是,在贪婪算法中,每采用一次贪婪准则,便做出一个不可撤回的决策;而在动态规划算法中,还要考察每个最优决策序列中是否包含一个最优决策子序列,即问题是否具有最优子结构性质。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









