









1.用户增长
- 数据技术驱动全渠道用户触达(网易严选)
- 有赞数据驱动增长体系的建设(有赞)
- 基于doris构建的小程序私域流量增长(智能小程序)
2.知识图谱
- 百度知识图谱技术及应用(百度)
- 美团大脑系列商品知识图谱的构建及应用(美团)
- 基于事理图谱的智能培训(贝壳)
3.推荐算法
- 深度树匹配召回体系演进(阿里妈妈)
- 粗排技术体系与最新进展(阿里)
- EdgeRec:边缘计算在推荐系统中的应用(阿里)
- 算力效能技术体系@阿里定向广告(阿里妈妈)
- 多目标排序在快手短视频推荐中的实践(快手)
- 多业务融合推荐场景下的深度学习实践(58同城)
4.风控安全
- 模型可解释性在保险理赔反欺诈中的应用实践(中国人寿)
5.大数据架构
- 如何让Ozone成为HDFS的下一代分布式存储系统(腾讯)
- Data Quality Architecture at Tubi(tubi)
- 结构化大数据链路在车好多的实践(车好多)
- 基于Apache Hudi构建数据湖上低延迟CDC的实践(T3出行)
- 基于Logi-KafkaManager打造专业易用KafkaPAAS服务(滴滴)
6.自然语言处理
- Volctrans: Application and Research(volctrans)
- 阿里多语言翻译模型的前沿探索以及技术实践(阿里巴巴)
- 小米对机器翻译的探索和实践(小米)
- LightSeq: 高性能NLP序列推理实践
- 细粒度文本情感分析及其应用(华为云)
7.数据仓库
- 滴滴指标体系建设实践分享(滴滴)
- 陌陌大数据治理与优化实践(陌陌)
- 贝壳基于Apache Druid的OLAP引擎应用实践(贝壳)
- 金融资管数据中台体系的探索和实践(北京熵简)
- 云数据库clickhouse技术分享暨海量数据分析场景应用实践(阿里云)
8.数据产品
- AI手机产品化实践与思考
- 转变,贝壳找房数据平台演进(贝壳)
- 全链路市场投放的数据产品(网易严选)
9.大数据应用
- 基于大数据技术构建爱奇艺全链路监控平台(爱奇艺)
- 数据湖的初步探索与实践落地(bilibili)
- 爱奇艺数据中台服务化建设(爱奇艺)
- Impala 3.4在网易的优化实践(网易)
- Doris 在⼩小⽶米数据中台中的应⽤(小米)
10.广告算法
- 阿⾥妈妈定向⼴告智能投放体系和技术(阿里妈妈)
- 短视频场景下信息流广告的挑战和技术(快手)
- 因果推断在飞猪广告预算分配中的应用(飞猪技术)
11.计算机视觉
- 视频技术技术在百度的应用(百度)
- 计算机视觉中的自监督学习 与Transformer注意力(微软亚洲)
- 一种面向自然场景下的低质文本识别方法(图匠数据)
- 边缘计算时代下的计算机视觉技术落地实践(地平线)
- 多媒体内容理解在美图社区的应⽤实践(美图)
12.搜索算法
- 5G+智能时代的多模搜索技术(百度)
- 搜狗搜索精准问答技术研究与应用(搜狗)
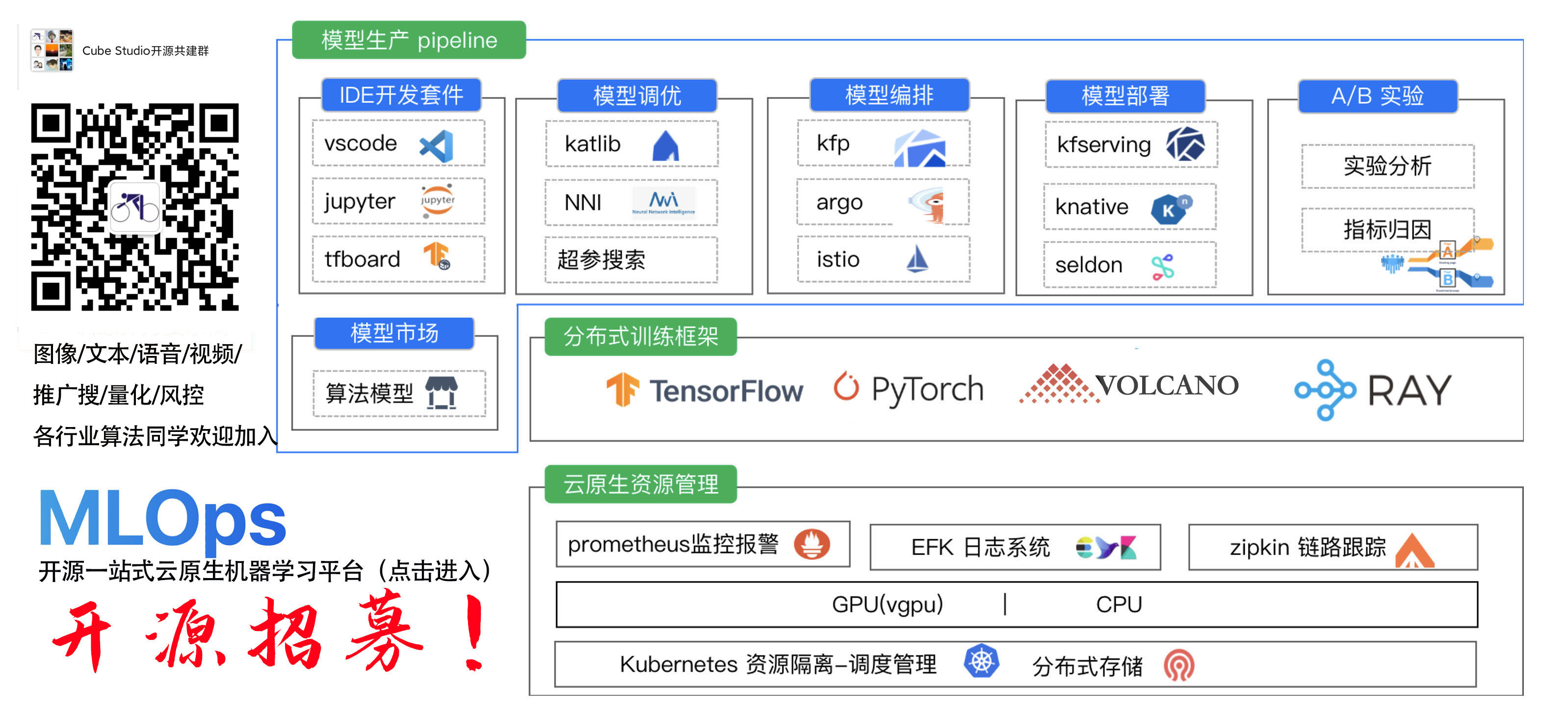
13.机器学习平台
- vGPU在机器学习平台中的多场景应用(小米)
- Data Provider Solution for DLT on Brain++(旷视)
- 58深度学习平台在提高模型推 理性能和 GPU使用率上实践(58同城)
14.数据治理
- 美团酒旅数据治理实践(美团)
- 网易严选数据任务治理实践(网易严选)
- 有赞数据治理之提质降本(有赞)


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











