







索引
简介
数据库索引与书籍的索引类似。有了索引就不需要翻整本书,数据库可以直接在索
引中查找,在索引中找到条目以后,就可以直接跳转到目标文档的位置,这能使查
找速度提高几个数量级。
不使用索引的查询称为全表扫描(这个术语来自关系型数据库),也就是说,服务器
必须查找完一整本书才能找到查询结果。这个处理过程与我们在一本没有索引的书
中查找信息很像:从第1 页开始一直读完整本书。通常来说,应该尽量避免全表扫
描,因为对于大集合来说,全表扫描的效率非常低。
来看一个例子,我们创建了一个拥有1 000 000 个文档的集合(如果你想要10 000 000
或者100 000 000 个文档也行,只要你有那个耐心):
var start = (new Date()).getTime();
for(i = 0;i<100000;i++)
{
db.testdata.insert({"i":i,"username":"user"+i,"age":Math.floor(Math.random()*120), "created":new Date()});
}
print("cost time :" +((new Date()).getTime() - start) + " ms" );
load('testdata.js')
cost time :66210 ms
true
> db.testdata.find()如果在这个集合上做查询,可以使用explain() 函数查看MongoDB 在执行查询的
过程中所做的事情。下面试着查询一个随机的用户名:
db.testdata.find({"username":"user101"}).explain()
{
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 2,
"nscannedObjects" : 100827,
"nscanned" : 100827,
"nscannedObjectsAllPlans" : 100827,
"nscannedAllPlans" : 100827,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 787,
"nChunkSkips" : 0,
"millis" : 69,
"server" : "localhost.localdomain:27017",
"filterSet" : false
}“nscanned” 是MongoDB 在完成这个查询的过程中扫描的文档总数。可以看到,
这个集合中的每个文档都被扫描过了。也就是说,为了完成这个查询,MongoDB
查看了每一个文档中的每一个字段。这个查询耗费了将近1 秒的时间才完成:
“millis” 字段显示的是这个查询耗费的毫秒数。
字段”n” 显示了查询结果的数量, 这里是1, 因为这个集合中确实只有一个
username 为”user101” 的文档。注意,由于不知道集合里的username 字段是唯
一的,MongoDB 不得不查看集合中的每一个文档。为了优化查询,将查询结果限
制为1,这样MongoDB 在找到一个文档之后就会停止了:
> db.testdata.find({"username":"user101"}).limit(1).explain()
{
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 102,
"nscanned" : 102,
"nscannedObjectsAllPlans" : 102,
"nscannedAllPlans" : 102,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"server" : "localhost.localdomain:27017",
"filterSet" : false
}现在,所扫描的文档数量极大地减少了,而且整个查询几乎是瞬间完成的。但是,
这个方案是不现实的:如果要查找的是user999999 呢?我们仍然不得不遍历整个
集合,而且,随着用户的增加,查询会越来越慢。
对于此类查询,索引是一个非常好的解决方案:索引可以根据给定的字段组织数据,
让MongoDB 能够非常快地找到目标文档。下面尝试在username 字段上创建一个
索引:
db.testdata.ensureIndex({"username":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}由于机器性能和集合大小的不同, 创建索引有可能需要花几分钟时间。如果
对ensureIndex 的调用没能在几秒钟后返回, 可以在另一个shell 中执行
db.currentOp() 或者是检查mongod 的日志来查看索引创建的进度。
索引创建完成之后,再次执行最初的查询:
db.testdata.find({"username":"user101"}).explain()
{
"cursor" : "BtreeCursor username_1",
"isMultiKey" : false,
"n" : 2,
"nscannedObjects" : 2,
"nscanned" : 2,
"nscannedObjectsAllPlans" : 2,
"nscannedAllPlans" : 2,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 58,
"indexBounds" : {
"username" : [
[
"user101",
"user101"
]
]
},
"server" : "localhost.localdomain:27017",
"filterSet" : false
}这次explain() 的输出内容比之前复杂一些, 但是目前我们只需要注意”n”、
“nscanned” 和”millis” 这几个字段,可以忽略其他字段。可以看到,这个查询
现在几乎是瞬间完成的(甚至可以更好),而且对于任意username 的查询,所耗费
的时间基本一致:
可以看到,使用了索引的查询几乎可以瞬间完成,这是非常激动人心的。然而,使
用索引是有代价的:对于添加的每一个索引,每次写操作(插入、更新、删除)都
将耗费更多的时间。这是因为,当数据发生变动时,MongoDB 不仅要更新文档,
还要更新集合上的所有索引。因此,MongoDB 限制每个集合上最多只能有64 个索
引。通常,在一个特定的集合上,不应该拥有两个以上的索引。于是,挑选合适的
字段建立索引非常重要。
为了选择合适的键来建立索引,可以查看常用的查询,以及那些需要被优化的查
询,从中找出一组常用的键。例如,在上面的例子中,查询是在”username” 上
进行的。如果这是一个非常通用的查询,或者这个查询造成了性能瓶颈,那么在
“username” 上建立索引会是非常好的选择。然而,如果这只是一个很少用到的查
询,或者只是给管理员用的查询(管理员并不需要太在意查询耗费的时间),那就不
应该对”username” 建立索引。
复合索引
索引的值是按一定顺序排列的,因此,使用索引键对文档进行排序非常快。然
而,只有在首先使用索引键进行排序时,索引才有用。例如,在下面的排序里,
“username” 上的索引没什么作用:
> db.users.find().sort({"age" : 1, "username" : 1})这里先根据”age” 排序再根据”username” 排序,所以”username” 在这里发挥的
作用并不大。为了优化这个排序,可能需要在”age” 和”username” 上建立索引:
> db.users.ensureIndex({"age" : 1, "username" : 1})这样就建立了一个复合索引(compound index)。如果查询中有多个排序方向或者查
询条件中有多个键,这个索引就会非常有用。复合索引就是一个建立在多个字段上
db.testdata.find().limit(10).sort({"username":1}).explain()
{
"cursor" : "BtreeCursor username_1",
"isMultiKey" : false,
"n" : 10,
"nscannedObjects" : 10,
"nscanned" : 10,
"nscannedObjectsAllPlans" : 10,
"nscannedAllPlans" : 10,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"username" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
},
"server" : "localhost.localdomain:27017",
"filterSet" : false
}在没有索引的列上排序:
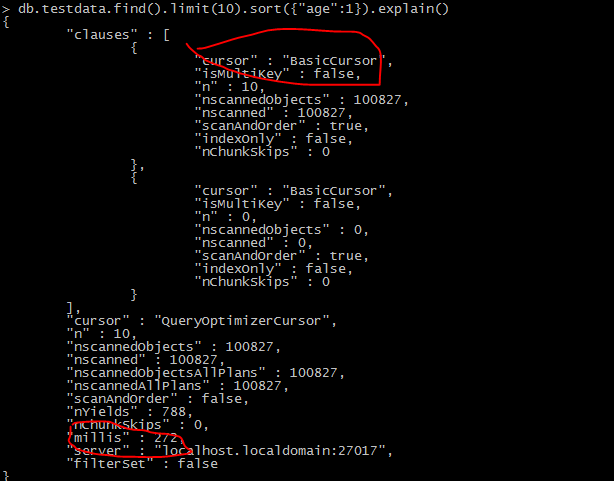
性能低的惊人.
建立复合索引
> db.testdata.ensureIndex({"age":1,"username":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}建立复合索引后性能惊人的高
db.testdata.find().limit(10).sort({"age":1,"username":1}).explain()
{
"cursor" : "BtreeCursor age_1_username_1",
"isMultiKey" : false,
"n" : 10,
"nscannedObjects" : 10,
"nscanned" : 10,
"nscannedObjectsAllPlans" : 10,
"nscannedAllPlans" : 10,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"age" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
],
"username" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
},
"server" : "localhost.localdomain:27017",
"filterSet" : false假如我们有一个users 集合(如下所示),如果在这个集合上执行一个不排序(称为
自然顺序)的查询:
> db.users.find({}, {"_id" : 0, "i" : 0, "created" : 0})
{ "username" : "user0", "age" : 69 }
{ "username" : "user1", "age" : 50 }
{ "username" : "user2", "age" : 88 }
{ "username" : "user3", "age" : 52 }
{ "username" : "user4", "age" : 74 }
{ "username" : "user5", "age" : 104 }
{ "username" : "user6", "age" : 59 }
{ "username" : "user7", "age" : 102 }
{ "username" : "user8", "age" : 94 }
{ "username" : "user9", "age" : 7 }
{ "username" : "user10", "age" : 80 }如果使用{“age” : 1, “username” : 1} 建立索引,这个索引大致会是这个样子:
[0, "user100309"] -> 0x0c965148
[0, "user100334"] -> 0xf51f818e
[0, "user100479"] -> 0x00fd7934
...
[0, "user99985" ] -> 0xd246648f
[1, "user100156"] -> 0xf78d5bdd
[1, "user100187"] -> 0x68ab28bd
[1, "user100192"] -> 0x5c7fb621
...
[1, "user999920"] -> 0x67ded4b7
[2, "user100141"] -> 0x3996dd46
[2, "user100149"] -> 0xfce68412
[2, "user100223"] -> 0x91106e23索引数组
也可以对数组建立索引,这样就可以高效地搜索数组中的特定元素。
假如有一个博客文章的集合,其中每个文档表示一篇文章。每篇文章都有一个
“comments” 字段,这是一个数组,其中每个元素都是一个评论子文档。如果想要
找出最近被评论次数最多的博客文章,可以在博客文章集合中嵌套的”comments”
数组的”date” 键上建立索引:
> db.blog.ensureIndex({"comments.date" : 1})对数组建立索引,实际上是对数组的每一个元素建立一个索引条目,所以如果一篇
文章有20 条评论,那么它就拥有20 个索引条目。因此数组索引的代价比单值索引
高:对于单次插入、更新或者删除,每一个数组条目可能都需要更新(可能有上千
个索引条目)。
与上一节中”loc” 的例子不同,无法将整个数组作为一个实体建立索引:对数组建
立索引,实际上是对数组中的每个元素建立索引,而不是对数组本身建立索引。
在数组上建立的索引并不包含任何位置信息:无法使用数组索引查找特定位置的数
组元素,比如”comments.4”。
少数特殊情况下,可以对某个特定的数组条目进行索引,比如:
db.blog.ensureIndex({“comments.10.votes”: 1})
然而,只有在精确匹配第11 个数组元素时这个索引才有用(数组下标从0 开始)。
一个索引中的数组字段最多只能有一个。这是为了避免在多键索引中索引条目爆炸
性增长:每一对可能的元素都要被索引,这样导致每个文档拥有n*m 个索引条目。
假如有一个{“x” : 1, “y” : 1} 上的索引:
// x 是一个数组——这是合法的
db.multi.insert({“x” : [1, 2, 3], “y” : 1})// y 是一个数组——这也是合法的
db.multi.insert({“x” : 1, “y” : [4, 5, 6]})// x 和y 都是数组——这是非法的!
db.multi.insert({“x” : [1, 2, 3], “y” : [4, 5, 6]})
cannot index parallel arrays [y] [x]
如果MongoDB 要为上面的最后一个例子创建索引,它必须要创建这么多索引条目:
{“x” : 1, “y” : 4}、{“x” : 1, “y” : 5}、{“x” : 1, “y” : 6}、{“x” : 2,
“y” : 4}、{“x” : 2, “y” : 5},{“x” : 2, “y” : 6}、{“x” : 3, “y” : 4}、
{“x” : 3, “y” : 5} 和{“x” : 3, “y” : 6}。尽管这些数组只有3 个元素。
索引基数
基数(cardinality)就是集合中某个字段拥有不同值的数量。有一些字段,比如
“gender” 或者”newsletter opt-out”,可能只拥有两个可能的值,这种键的基
数就是非常低的。另外一些字段,比如”username” 或者”email”,可能集合中的
每个文档都拥有一个不同的值,这类键的基数是非常高的。当然也有一些介于两者
之间的字段,比如”age” 或者”zip code”。
通常,一个字段的基数越高,这个键上的索引就越有用。这是因为索引能够迅速将
搜索范围缩小到一个比较小的结果集。对于低基数的字段,索引通常无法排除掉大
量可能的匹配。
假设我们在”gender” 上有一个索引,需要查找名为Susan 的女性用户。通过这个
索引,只能将搜索空间缩小到大约50%,然后要在每个单独的文档中查找”name”
为”Susan” 的用户。反过来,如果在”name” 上建立索引,就能立即将结果集缩小
到名为”Susan” 的用户,这样的结果集非常小,然后就可以根据性别从中迅速地找
到匹配的文档了。
一般说来,应该在基数比较高的键上建立索引,或者至少应该把基数较高的键放在
复合索引的前面(低基数的键之前)。















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









