






目录
一、typing 模块:限定方法的参数类型和返回值类型
常用类型
int,long,float: 整型,长整形,浮点型
bool,str: 布尔型,字符串类型
List, Tuple, Dict, Set,Sequence:列表,元组,字典, 集合
Iterable,Iterator:可迭代类型,迭代器类型
Generator:生成器类型
使用示例:(求两个list的中位数)
from typing import List, Optional
def findMedianSortedArrays( nums1: List[int], nums2: List[int]) -> float:
nums=list(sorted(nums1+nums2))
len_nums=len(nums)
if len_nums%2==0:
return (nums[len_nums/2-1]+nums[len_nums/2])/2
else:
return nums[(len_nums-1)/2]
**注:**因为Tuple是不可变,所以当我们指定Tuple[str, str]时,就只能传入长度为2,并且元组中的所有元素都是str类型。
二、argparse模块:实现在终端命令行传参
代码:
import argparse
def define_myArgs():
parser = argparse.ArgumentParser(description="读取文件并进行解析,传入Excel文件路径与保存路径")
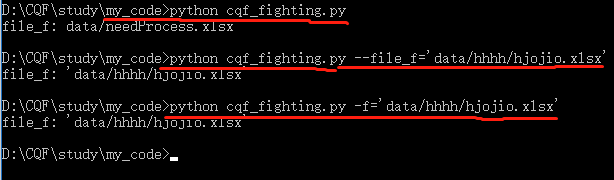
parser.add_argument('--file_f', '-f', default='data/needProcess.xlsx', help='读取的源文件目录')
parser.add_argument('--file_t', '-t', default='data/hasProcessed.xlsx', help='已经处理完成的Excel结果文件保存路径')
args=parser.parse_args()
return args
args=define_myArgs()
print('file_f:',args.file_f)
在终端运行时,传参示例:
三、configparser模块和.ini文件
configparser模块主要用于读取配置文件(.ini)。
ini配置文件:
section:[section]
parameter:name = value
comment:;comments text(注释)
示例:
; mysql host
[db_mysql]
mysql-host=xx.xx.xx.xxx
mysql-user=root
configparser模块使用示例:
import configparser
cf = configparser.ConfigParser()
cf.read('dbconfig.ini', encoding='utf8') # windows下默认都是gbk编码,Linux下默认都是utf-8,所以需要转换编码格式~
# cf.read(conf_file) #Linux下默认都是utf-8(以后字符编码记得通通用utf8 要不服务器上会都是乱码)
cf.sections() # 返回所有节点(section),结果:['db_mysql']
cf.items('db_mysql') # 返回指定节点的配置信息,结果:[('mysql-host', 'xx.xx.xx.xxx'), ('mysql-user', 'root')]
info_conf = {'mysql_host': cf.get('db_mysql', 'mysql-host'),
'mysql_user' : cf.get('db_mysql', 'mysql-user')}
四、sys模块:终端传参的简易操作
1、命令窗口传参数,没有指定的变量名,区别于argparse
import sys
args = sys.argv
print(args) #
在命令窗口运行,结果:

五、time模块
time模块
time.strftime(‘%Y%m%d %H:%M’,time.localtime(time.time()))

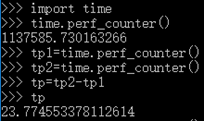
time.perf_counter():只有连续两次perf_counter()进行差值计算才能有意义,一般用于计算程序运行时间。(以秒为单位)
datetime模块:

六、os模块、shutil模块:文件与路径的敏捷操作
1、路径操作模块:os
常用的一些路径操作方法:
import os
file_path=os.path.dirname(__file__) # 获取当前文件所在路径,与os.path.abspath(os.path.curdir)结果一样。结果:e:/my_study/my_code;
file_name='some_pro.py'
if not os.path.exists(file_path): # 判断指定路径是否存在
os.makedirs(file_path) # 不存在则新建,(os.makedirs()递归的建立输入的路径,即使是上层的路径不存在,它也会建立这个路径。;os.mkdir()创建路径中的最后一级目录,而如果之前的目录不存在并且也需要创建的话,就会报错。)
file_path_complete=os.path.join(file_path, file_name) # 路径拼接,函数中可以传入多个路径
>>> os.path.split('e:/my_study/my_code') # 路径拆分。把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名
('e:/my_study', 'my_code')
# os.walk()获取指定路径下文件夹与文件,一层为一个元祖(该层完整路径,[该层路径下所有文件夹名],[该层路径下所有文件名])
>>> walk_obj=os.walk(file_path)
>>> walk_obj
<generator object walk at 0x000001E695092430>
>>> lis_walk=list(walk_obj)
>>> lis_walk
[('e:/my_study/my_code', ['my_pkg', 'my_pkg1'], ['cqf_fighting.py', 'cqf_fighting_home.py', 'cqf_tt.py', 'dynamic_programming.py', 'hash_table.py', 'linked_list.py', 'recall.py', 'stack_queue.py', 'string_my.py']), ('e:/my_study/my_code\\my_pkg', [], ['test.txt']), ('e:/my_study/my_code\\my_pkg1', [], ['test1.txt'])]
# os.listdir()获取指定路径下所有文件夹和文件,以list形式返回
>>> lis_dir=os.listdir('e:/my_study/my_code')
>>> lis_dir
['cqf_fighting.py', 'cqf_fighting_home.py', 'cqf_tt.py', 'dynamic_programming.py', 'hash_table.py', 'linked_list.py', 'my_pkg', 'my_pkg1', 'recall.py', 'stack_queue.py', 'string_my.py']
# 获取指定文件的状态
>>> status=os.stat('e:/my_study/my_code/hash_table.py')
>>> status
os.stat_result(st_mode=33206, st_ino=281474976780821, st_dev=2361123576, st_nlink=1, st_uid=0, st_gid=0, st_size=12351, st_atime=1646031441, st_mtime=1644978688, st_ctime=1644978526)
>>> status.st_ino
281474976780821
>>> os.path.getsize('e:/my_study/my_code/hash_table.py') # 获取指定文件size,与stat结果里的st_size值相等
12351
# 删除指定文件
>>> os.remove(r'E:\my_study\my_code\my_pkg1\test1.txt')
# 文件重命名
os.rename(path_f, path_t) # 将path_f命名为path_t
2、文件或目录操作模块:shutil
shutil模块主要强大之处在于其对文件的复制、移动与删除操作。
1)移动文件:shutil.move(path_f, path_t)
2)复制文件:
①shutil.copy(path_f, path_t):仅复制文件及其权限,但不会复制问文件的状态信息
②shutil.copy2(path_f, path_t):复制文件和状态信息。
③shutil.copytree(path_f, path_t):将路径 path_f 处的文件夹,包括它的所有文件和子文件夹,复制到路径path_t 处的文件夹。
3、常见的字符编码问题
**异常1:**写入到文件时报错,'utf-8' codec can't encode characters in position 13937-13938: surrogates not allowed
原因:一些字符串无法被utf-8解码,所以可以把无法转化为utf-8格式的字符‘ignore’掉,再进行解码然后写入。
解决:
content = content.encode('UTF-8', 'ignore').decode('UTF-8')
异常2: 读取文件时出现错误:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa1 in position 35: illegal multibyte sequence
解决:加入encoding参数,如
f = open('order.log','r', encoding='UTF-8')
异常3: rb方式读取文件并利用正则时出错:TypeError: cannot use a string pattern on a bytes-like object
解决:line=line.strip().decode(‘utf-8’)
异常4: 程行运行中有中文字符串,出现问题:SyntaxError: Non-UTF-8 code starting with '\xe8' in file
解决:在程序最上面添加编码说明:coding:utf-8 / coding=gbk
**异常5:**中文写入文件出现编码问题:
(1)写入csv/Excel乱码:encoding=utf-8 -> encoding=gbk
(2)写入csv/Excel报非法字符错误:encoding=gbk -> encoding=gb18030
(3)还是有非法字符报错:(需要安装 xlsxwriter)
七、tqdm进度条模块
1、基于迭代对象运行
【注意】进度条反映的是整个循环运行的 时间进度。
>>> lis=[[1,'a']]*1000
>>> sum=0
>>> for n,s in tqdm(lis, desc='print:',colour='green'):
... sum+=1
... time.sleep(0.1)
... if sum%100==0:
print('\n',n,s)
...
print:: 10%|████████████████▌ | 99/1000 [00:10<01:35, 9.42it/s]
1 a
print:: 20%|█████████████████████████████████ | 199/1000 [00:21<01:25, 9.36it/s]
1 a
print:: 30%|█████████████████████████████████████████████████▋ | 299/1000 [00:31<01:14, 9.40it/s]
1 a
print:: 40%|██████████████████████████████████████████████████████████████████▏ | 399/1000 [00:42<01:04, 9.37it/s]
1 a
print:: 50%|██████████████████████████████████████████████████████████████████████████████████▊ | 499/1000 [00:52<00:53, 9.43it/s]
1 a
print:: 60%|███████████████████████████████████████████████████████████████████████████████████████████████████▍ | 599/1000 [01:03<00:42, 9.42it/s]
1 a
print:: 70%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 699/1000 [01:14<00:31, 9.45it/s]
1 a
print:: 80%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▋ | 799/1000 [01:24<00:21, 9.46it/s]
1 a
print:: 90%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 899/1000 [01:35<00:10, 9.42it/s]
1 a
print:: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊| 999/1000 [01:46<00:00, 9.46it/s]
1 a
print:: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [01:46<00:00, 9.42it/s]
八、psutil模块:操作系统的信息查看
获取操作系统以及硬件相关的信息,比如:CPU、磁盘、网络、内存等等。
如:
m = 0
for i in range(10):
m += i
print('A:%.2f MB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024)) # 获取当前进程所使用的的内存
del i
gc.collect()
print('B:%.2f MB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024))
print(u'cpu个数:',psutil.cpu_count()) # 获取 CPU 的逻辑数量。 logical=False获取物理核心数量
结果:
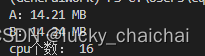
九、logging日志模块
- 创建日志的模块;
- 日志level 包括:严重程度的级别依次是debug< info < warning < error < critical;
- 设置的时候包括Logger’s level 和Handler’s Level ,最终记录的level取较高的那个;
- 日志切分方法:①TimedRotatingFileHandler():按照时间间隔切分;②RotatingFileHandler():按照文件大小进行切分。
from logging.handlers import TimedRotatingFileHandler, RotatingFileHandler
handler = TimedRotatingFileHandler(
filename="./test.log",
when="S", # ‘S’、‘M’、‘H’、‘D’、‘W’ 和 ‘midnight’,分别表示秒、分、时、天、周和每天的午夜
interval=3,
backupCount=5, # 表示最多备份的文件数
encoding="utf8"
)
handler = RotatingFileHandler(
filename='test.log',
maxBytes=6, # 单个日志文件的最大大小,单位为字节
backupCount=3
)
# 每次调用该日志定义的时候,只需要在程序的一开始调用一下MyLogger类,后面的py文件只需要引用mylogger就可以
import logging
import os
import time
mylogger=logging.getLogger() # 改语句若放在MyLogger类中,每次写日志的时候都需要引用这个类,则会引用几次日志语句就会重复几次
class MyLogger(object):
def __init__(self):
time_str=time.strftime(r'%Y%m%d',time.localtime(time.time()))
out_dir=os.path.join(os.curdir, 'logger_files')
if not os.path.exists(out_dir):
os.makedirs(out_dir)
out_dir=os.path.join(out_dir, time_str+'.log')
mylogger.setLevel(logging.INFO)
fh=logging.FileHandler(out_dir, mode='a')
fh.setLevel(logging.DEBUG)
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(pathname)s - %(filename)s[line:%(lineno)d] - %(message)s"
formatter=logging.Formatter(LOG_FORMAT)
fh.setFormatter(formatter)
mylogger.addHandler(fh)
if __name__ == "__main__":
MyLogger()
print('aaaa')
mylogger.info('打印aaa,对我的logger进行测试~~')
十、print实现流式输出
print()实现流式输出效果:
if __name__ == '__main__':
import time
time.sleep(10)
text = '“如果CUDA error: out of memory这句话后面跟了 Tried to allocate ...MB的话,是显存不够,可以尝试缩小batch_size等方法来节省显存;但是如果后面没有这句话,说明是GPU被占用或torch版本与pre-trained model版本不匹配” '
print('waiting', end='')
for w in text:
print(
w,
end='', # 每次print的后缀,默认是换行符'\n'
flush=True # Python通常会将输出缓存起来,并在缓冲区满或者遇到换行符时才实际输出到屏幕上。该参数用于强制立即刷新输出缓冲区,确保用户能够立即看到输出。
)
time.sleep(0.1)
动态效果:
杂七杂八——流式print














 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









