







python爬虫实战(二)
利用seleium模拟鼠标操作爬取某中文网站搜索到的指定内容新闻数据
一、利用seleium模拟鼠标操作
1、通过浏览器登录某新闻网后,F12开发模式的查看器,找到搜索栏和搜索按键两个元素的css表达式
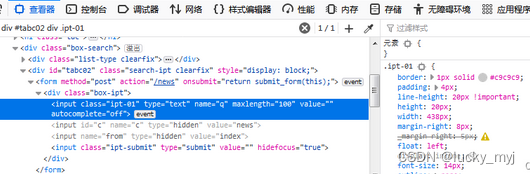
首先模拟登录某新闻网后,在搜索栏输入搜索内容,点击搜索按键,获取结果数据
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
#headers可以通过浏览器F12模式的网络中获取请求头中user-agent的信息,这里不再赘述
headers = {
'User-Agent':''}
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
url = 'https://********.com.cn/'
driver.get(url)
driver.implicitly_wait(5)
driver.maximize_window()
WebDriverWait(driver, 15).until(
EC.presence_of_element_located( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









