公司有需求啊,所以就得研究哈,最近公司需要读验证码,于是就研究起了图像识别,应该就是传说中的(OCR:光学字符识别OCR),下面把今天的收获整理一个给大家做个分享。
本人程序用的tesseract,官方地址:https://code.google.com/p/tesseract-ocr/,不为别的,谁让它支持我们的天朝的文字呢~哈
下载好程序后解压:
大概可以看到这样一个目录,别见怪楼主里面一堆测试文件。
然后就开始我们的测试之旅:
tesseract的用法:
参数1:需要识别的文件
参数2:输出的文件名称,输出的是文本文件,里面保存了识别的信息
识别英文这两个参数就可以了,下面做个实验:

我们在命令行输入:tesseract 5.jpg 6 ,可以看到程序生成了一个6.txt ,里面保存着识别后的文本,怎么样简单又给力~
上面说道tesseract 是支持中文的,所以么,接下来看看如何使用tesseract 实现我们中文的识别,下面继续介绍其他参数
参数3:-l
参数4: 使用的语言库
参数3 -l应该是知道参数4所使用的语言库,默认英文,也就是为什么上面识别英文的例子,并没有输入参数3和参数4,也实现了识别。
下面继续我们的实验:
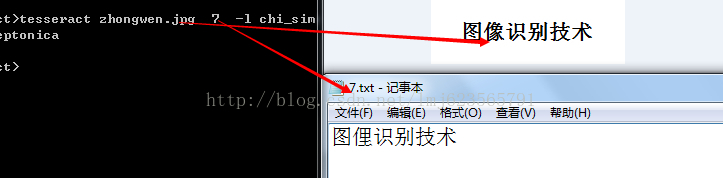
我们准备了一张图片,然后使用tesseract zhongwen.jpg 7 -l chi_sim 指明了中文语言,然后效果图上,还是很不错的,毕竟我们的中文是如此的博大精深,并且tesseract可以经过训练,然后识字的能力就会大幅度提升。
好了,由于一行代码没写,就不上传代码了,大家自己去官网下载。接下来我会使用Java带大家实现这样的小程序。
接着上一篇OCR所说的,上一篇给大家介绍了tesseract 在命令行的简单用法,当然了要继承到我们的程序中,还是需要代码实现的,下面给大家分享下Java实现的例子。

拿代码扫描上面的图片,然后输出结果。主要思想就是利用Java调用系统任务。
下面是核心代码:
代码很简单,中间那部分ProcessBuilder其实就类似Runtime.getRuntime().exec("tesseract.exe 1.jpg 1 -l chi_sim"),大家不习惯的可以使用Runtime。
测试代码:
- package com.zhy.test;
-
- import java.io.File;
-
- public class Test
- {
- public static void main(String[] args)
- {
- try
- {
-
- File testDataDir = new File("testdata");
- System.out.println(testDataDir.listFiles().length);
- int i = 0 ;
- for(File file :testDataDir.listFiles())
- {
- i++ ;
- String recognizeText = new OCRHelper().recognizeText(file);
- System.out.print(recognizeText+"\t");
-
- if( i % 5 == 0 )
- {
- System.out.println();
- }
- }
-
- } catch (Exception e)
- {
- e.printStackTrace();
- }
-
- }
- }
输出结果:
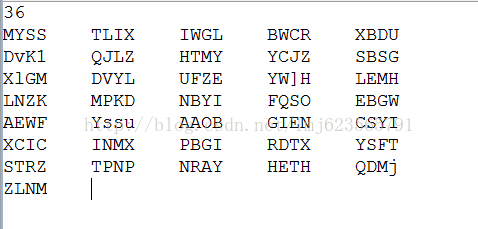
对比第一张图片,是不是很完美~哈哈 ,当然了如果你只需要实现验证码的读写,那么上面就足够了。下面继续普及图像处理的知识。
-------------------------------------------------------------------我的分割线--------------------------------------------------------------------
当然了,有时候图片被扭曲或者模糊的很厉害,很不容易识别,所以下面我给大家介绍一个去噪的辅助类,绝对碉堡了,先看下效果图。
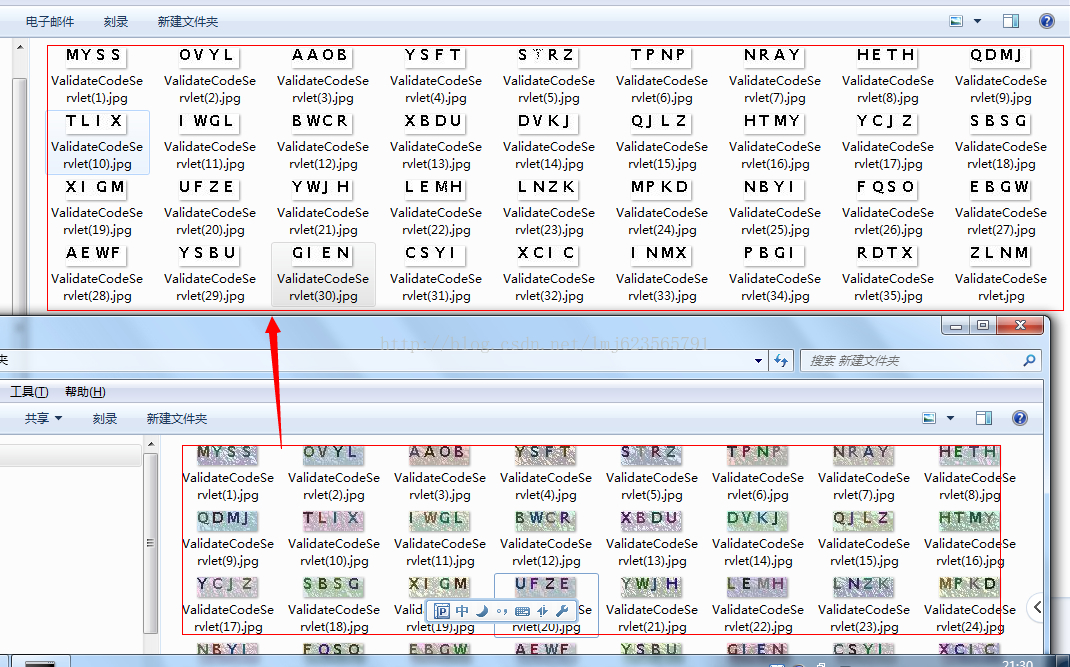
来张特写:

一个类,不依赖任何jar,把图像中的干扰线消灭了,是不是很给力,然后再拿这样的图片去识别,会不会效果更好呢,嘿嘿,大家自己实验~
代码:
- package com.zhy.test;
-
- import java.awt.Color;
- import java.awt.image.BufferedImage;
- import java.io.File;
- import java.io.IOException;
-
- import javax.imageio.ImageIO;
-
- public class ClearImageHelper
- {
-
- public static void main(String[] args) throws IOException
- {
-
-
- File testDataDir = new File("testdata");
- final String destDir = testDataDir.getAbsolutePath()+"/tmp";
- for (File file : testDataDir.listFiles())
- {
- cleanImage(file, destDir);
- }
-
- }
-
-
-
-
-
-
-
-
-
- public static void cleanImage(File sfile, String destDir)
- throws IOException
- {
- File destF = new File(destDir);
- if (!destF.exists())
- {
- destF.mkdirs();
- }
-
- BufferedImage bufferedImage = ImageIO.read(sfile);
- int h = bufferedImage.getHeight();
- int w = bufferedImage.getWidth();
-
-
- int[][] gray = new int[w][h];
- for (int x = 0; x < w; x++)
- {
- for (int y = 0; y < h; y++)
- {
- int argb = bufferedImage.getRGB(x, y);
-
- int r = (int) (((argb >> 16) & 0xFF) * 1.1 + 30);
- int g = (int) (((argb >> 8) & 0xFF) * 1.1 + 30);
- int b = (int) (((argb >> 0) & 0xFF) * 1.1 + 30);
- if (r >= 255)
- {
- r = 255;
- }
- if (g >= 255)
- {
- g = 255;
- }
- if (b >= 255)
- {
- b = 255;
- }
- gray[x][y] = (int) Math
- .pow((Math.pow(r, 2.2) * 0.2973 + Math.pow(g, 2.2)
- * 0.6274 + Math.pow(b, 2.2) * 0.0753), 1 / 2.2);
- }
- }
-
-
- int threshold = ostu(gray, w, h);
- BufferedImage binaryBufferedImage = new BufferedImage(w, h,
- BufferedImage.TYPE_BYTE_BINARY);
- for (int x = 0; x < w; x++)
- {
- for (int y = 0; y < h; y++)
- {
- if (gray[x][y] > threshold)
- {
- gray[x][y] |= 0x00FFFF;
- } else
- {
- gray[x][y] &= 0xFF0000;
- }
- binaryBufferedImage.setRGB(x, y, gray[x][y]);
- }
- }
-
-
- for (int y = 0; y < h; y++)
- {
- for (int x = 0; x < w; x++)
- {
- if (isBlack(binaryBufferedImage.getRGB(x, y)))
- {
- System.out.print("*");
- } else
- {
- System.out.print(" ");
- }
- }
- System.out.println();
- }
-
- ImageIO.write(binaryBufferedImage, "jpg", new File(destDir, sfile
- .getName()));
- }
-
- public static boolean isBlack(int colorInt)
- {
- Color color = new Color(colorInt);
- if (color.getRed() + color.getGreen() + color.getBlue() <= 300)
- {
- return true;
- }
- return false;
- }
-
- public static boolean isWhite(int colorInt)
- {
- Color color = new Color(colorInt);
- if (color.getRed() + color.getGreen() + color.getBlue() > 300)
- {
- return true;
- }
- return false;
- }
-
- public static int isBlackOrWhite(int colorInt)
- {
- if (getColorBright(colorInt) < 30 || getColorBright(colorInt) > 730)
- {
- return 1;
- }
- return 0;
- }
-
- public static int getColorBright(int colorInt)
- {
- Color color = new Color(colorInt);
- return color.getRed() + color.getGreen() + color.getBlue();
- }
-
- public static int ostu(int[][] gray, int w, int h)
- {
- int[] histData = new int[w * h];
-
- for (int x = 0; x < w; x++)
- {
- for (int y = 0; y < h; y++)
- {
- int red = 0xFF & gray[x][y];
- histData[red]++;
- }
- }
-
-
- int total = w * h;
-
- float sum = 0;
- for (int t = 0; t < 256; t++)
- sum += t * histData[t];
-
- float sumB = 0;
- int wB = 0;
- int wF = 0;
-
- float varMax = 0;
- int threshold = 0;
-
- for (int t = 0; t < 256; t++)
- {
- wB += histData[t];
- if (wB == 0)
- continue;
-
- wF = total - wB;
- if (wF == 0)
- break;
-
- sumB += (float) (t * histData[t]);
-
- float mB = sumB / wB;
- float mF = (sum - sumB) / wF;
-
-
- float varBetween = (float) wB * (float) wF * (mB - mF) * (mB - mF);
-
-
- if (varBetween > varMax)
- {
- varMax = varBetween;
- threshold = t;
- }
- }
-
- return threshold;
- }
- }
--------------------------------------------------------------------------------另外一篇文章-------------------------------------------------------------------------------------------------------------------------------------
Tesseract,这里就在这里分享下。
1、Tesserac-ocr简介
[一个Google支持的开源的OCR图文识别开源项目。去持多语言(当前3.02 版本支持包括英文,简体中文,繁体中文),支持Windows,Linux,Mac OSX 多平台。使用中Tesseract 的识别率非常高。可以在项目网站下载:http://code.google.com/p/tesseract-ocr,新版本支持中文,中文语言包定义http://code.google.com/p/tesseract-ocr/downloads/detail?name=chi_sim.traineddata.gz。]
2、Tesseract安装+ U2 E4 O# `2 [+ @
这里使用的版本为Tesseract3.02。直接点击上面的链接,下载windows下的安装文件tesseract-ocr-setup-3.02.02.exe。由于上面的链接经常很难打开,因此在这里提供百度云链接:http://pan.baidu.com/s/1mg21nMK
安装tesseract-ocr-setup-3.02.02.exe。安装成功后会在相应磁盘上生成一个Tesseract-OCR目录。如图我是安装到了如下位置

安装完成打开命令行,输入tesseract,展现如下图说明已经安装成功

3、命令行测试使用
接下来就可以使用tesseract进行图片识别了。准备一副待识别的图像,这里用画图工具随便写了一段字,然后定义成1.jpg

( |4 Z+ g& _. S; X7 N" R! C
在命令行中定位到图片路径然后输入命令:

tesseract 1.jpg result -l eng
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。会发现图片当前目录下生成了1个result.txt文件里面结果为

/ T4 ?) P1 Q5 {9 R9 y) ~. ?2 C9 n' r' f
4、增加中文语言库
安装目录下的tessdata目录存放的是语言识别包,如果想增加中文识别功能,可以将中文的语言库放到此目录下,下载链接在下面地址:http://pan.baidu.com/s/1hqnGq4c,下载后将解压出的chi_sim.traineddata放到此目录下。然后调用的时候指明语言库即可,例如:tesseract xxx.jpg result -l chi_sim
照样,我们搞一个2.jpg图片,来测试下中文识别下的识别率怎么样。

执行后结果

2 Y& r+ n9 O* L5 o8 {2 H
,可以看到,识别率并不是十分令人满意。而且这边使用的例子都是十分正规的字体。如果遇到验证码那种不规则的字体,识别率也会大打折扣的。
当然可以参考网上的相关资料进行对Tesseract字符识别进行样本训练,通过使用训练后的语言库会提高识别精度。这里就不做演示了。参考地址:
http://blog.csdn.net/yasi_xi/article/details/8763385 。但是遗憾的是使用的工具jTessBoxEditor不支持中文训练。附带jTessBoxEditor1.0 下载地址:http://pan.baidu.com/s/1sjBe5el
5、使用java调用tesseract
那如何使用java程序调用相应的tesseract进行操作呢?
这里介绍2种方式。
一种是使用cmd方式,另外一种就是使用tess4j。tess4j的源码地址 http://sourceforge.jp/projects/sfnet_tess4j/ 中文首页
感兴趣的自己下载查看源代码。
由于范例代码较多就不一一贴出来了,会在文章结尾提供一个下载链接,大概讲下结构,

如上图,tess4j包下是使用tess4j调用tesseract,src下的dll文件是需要使用到的。同时,加载的语言库文件也要放到tessdata目录下。而cmd 包下是使用cmd方式调用的范例,额外需要swingx-1.6.1.jar,调用时直接配置使用的安装的路径,并配置语言库即可。

代码下载地址,由于附带了data文件,jar包等,所以会比较大,接近50M。导入到工程即可。各个包下都有测试的Test类,直接右键就可以运行。前提是对应目录下有相应图片。
在cmd包下ClearImageHelper这个类是对图片进行处理的类,比如灰度转换,二值化,缩放等等,对于复杂图片可以先进行处理,来提高图片识别率。而tess4j下也封装了图片处理的工具类,基本都包含这些功能,例子中也给出了部分样例。
Bty,话说使用原生态识别调用,跟tess4j得到的结果还是有所差别的。























 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









