






导语:本文主要介绍如何用 TensorFlow 让 AI 在 24 分钟内学会玩飞车类游戏。我们使用 Distributed PPO 训练 AI,在短时间内可以取得不错的训练效果。
本方法的特点:
- 纯游戏图像作为输入
- 不使用游戏内部接口
- 可靠的强化学习方法
- 简单易行的并行训练
1. PPO简介
PPO (Proximal Policy Optimization) 是 OpenAI 在 2016 年 NIPS 上提出的一个基于 Actor-Critic 框架的强化学习方法。该方法主要的创新点是在更新 Actor 时借鉴了 TRPO,确保在每次优化策略时,在一个可信任的范围内进行,从而保证策略可以单调改进。在 2017 年,DeepMind 提出了 Distributed PPO,将 PPO 进行类似于 A3C 的分布式部署,提高了训练速度。之后,OpenAI 又优化了 PPO 中的代理损失函数,提高了 PPO 的训练效果。
本文不介绍 PPO 的算法细节,想学习的同学可以参考文末参考文献中的三篇论文。
2. 图像识别
2.1 游戏状态识别
游戏状态识别是识别每一局游戏关卡的开始状态和结束状态。在飞车类游戏中,开始状态和结束状态的标志如图 1 所示。因为红色框中的标志位置都固定,因此我们使用模板匹配的方法来识别这些游戏状态。

从开始状态到结束状态之间的图像是游戏关卡内的图像,此时进行强化学习的训练过程。当识别到结束状态后,暂停训练过程。结束状态之后的图像都是 UI 图像,我们使用 UI 自动化的方案,识别不同的 UI,点击相应的按钮再次进入游戏关卡,开始下一轮的训练过程,如图 2 所示。

2.2 游戏图像识别
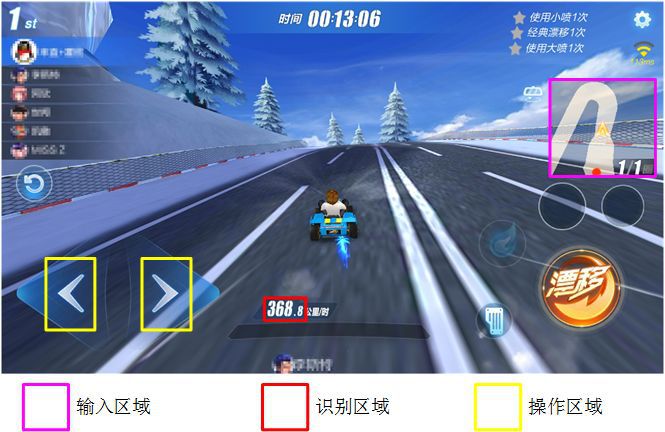
我们对游戏关卡中的图像识别了速度的数值,作为强化学习中计算激励 (Reward) 的依据,如图 3 所示。速度识别包括三个步骤:
- 图像分割,将每一位数字从识别区域中分割出来;
- 数字识别,用卷积神经网络或者模板匹配识别每一位图像中的数字类别;
- 数字拼接,根据图像分割的位置,将识别的数字拼接起来。
3. AI 设计
3.1 网络结构
我们使用的网络结构如图 4 所示。输入为游戏图像中小地图的图像,Actor 输出当前时刻需要执行的动作,Critic 输出当前时刻运行状态的评价。AlexNet 使用从输入层到全连接层之间的结构,包含 5 个卷积层和 3 个池化层。Actor 和 Critic 都有两个全连接层,神经元数量分别为 1024 和 512。Actor 输出层使用 softmax 激活函数,有三个神经元,输出动作策略。Critic 输出层不使用激活函数,只有一个神经元,输出评价数值。

3.2 输入处理
我们将小地图图像的尺寸变为 121X121,输入到 AlexNet 网络后,在第三个池化层可以获得 2304 维的特征向量 (576*2*2=2304)。将这个特征向量作为 Actor 和 Critic 的输入。我们使用在 ImageNet 上训练后的 AlexNet 提取图像特征,并且在强化学习的过程中没有更新 AlexNet 的网络参数。
3.3 动作设计
我们目前在设计飞车类游戏动作时,使用离散的动作,包括三种动作:左转、右转和 NO Action。每种动作的持续时间为 80ms,即模拟触屏的点击时间为 80ms。这样的动作设计方式比较简单,便于 AI 快速地训练出效果。如果将动作修改为连续的动作,就可以将漂移添加到动作中,让 AI 学习左转、右转、漂移和 NO Action 的执行时刻和执行时长。
3.4 激励计算
如果将游戏的胜负作为激励来训练 AI,势必会花费相当长的时间。
在本文中,我们根据游戏图像中的速度数值,计算当前时刻的激励。假定当前时刻的速度为 Vp,前一时刻的速度为Vq,那么激励R按照以下方式计算:
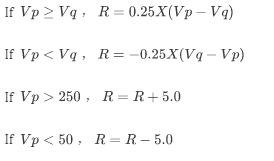
这样的激励计算方式可以使 AI 减少撞墙的概率,并且鼓励 AI 寻找加速点。
4. 训练环境
4.1 硬件
我们搭建了一个简单的分布式强化学习环境,可以提高采样效率和训练速度,硬件部署方式如图 5 所示。

主要包含以下硬件:、
- 3 部相同分辨率的手机,用于生成数据和执行动作;
- 2 台带有显卡的电脑,一台电脑 Proxy 用于收集数据、图像识别以及特征提取,另一台电脑 Server 用于训练 AI;
- 1 个交换机,连接两台电脑,用于交换数据。
4.2 软件
Ubuntu 14.04 + TensorFlow 1.2 + Cuda 7.0
5. 分布式部署
我们使用的分布式部署方式如图 6 所示。

在 Proxy 端设置三个 proxy 进程,分别与三部手机相连接。
在Server端设置一个 master 进程和三个 worker 线程。master 进程和三个 worker 线程通过内存交换网络参数。master 进程主要用于保存最新的网络参数。三个 proxy 进程分别和三个 worker 线程通过交换机传输数据。
Proxy 进程有 6 个功能:
- 从手机接收图像数据;
- 识别当前游戏状态;
- 识别速度计算激励;
- 利用 AlexNet 提取图像特征;
- 发送图像特征和激励到 worker 线程,等待 worker 线程返回动作;
- 发送动作到手机。
Worker 线程有 5 个功能:
- 从 proxy 进程接收图像特征和激励;
- 从 master 进程拷贝最新的网络参数;
- 将 Actor 输出的动作发送到 proxy 进程;
- 利用 PPO 更新网络参数;
- 将更新后的网络参数传输到 master 进程。
6. 核心代码
6.1 AlexNet 代码
我们使用 AlexNet 从输入图像中提取特征,代码如下:

由于 AlexNet 的网络结构中使用了分组卷积,QQ账号出售平台因此卷积层需要根据分组 (group) 的数量划分输入特征图和卷积核,最后再合并卷积后的结果,卷积层的代码为:

6.2 PPO 代码
在 PPO 中,我们将 AlexNet 提取的特征向量作为 state,Critic 输出评价值 value,Actor 输出动作的概率分布 pi。Critic 和 Actor 都有两个全连接层,代码如下:

在 master 进程中,仅仅保留 PPO 的参数,不涉及参数更新的操作,因此 master 进程只需要构建 Critic 和 Actor 的网络结构,代码如下:

在每个 worker 线程中,不仅需要构建 Critic 和 Actor 的网络结构,并且要定义参数更新和参数同步的操作,代码如下:

训练 Actor 和 Critic 时调用的函数为:

worker 线程与 master 进程之间的参数同步使用以下两个函数:

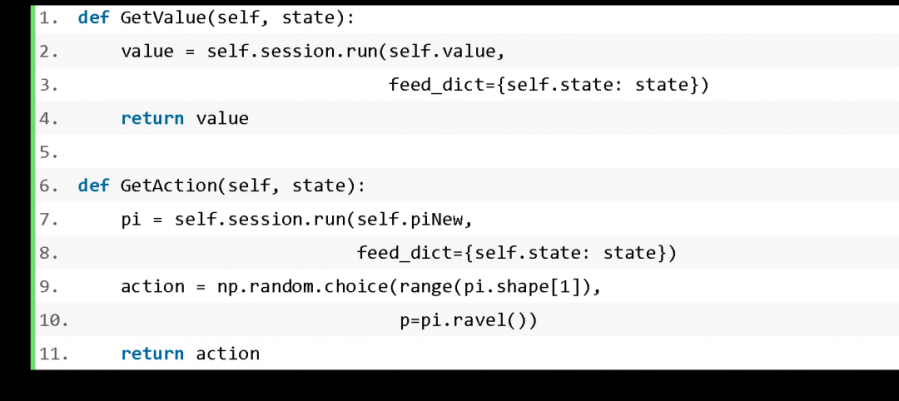
获取评价值和动作使用以下两个函数:
6.3 worker 代码
在 worker 线程中,主要负责与游戏环境进行交互,进行训练流程,代码如下:

在 Learn 函数中,我们首先按照设定的步长反向计算 reward,然后进行参数更新,最后将参数同步到 master 线程中,代码如下:

6.4 Server 代码
Server 主要进行 master 进程和 worker 线程的启动和管理,初始化的部分代码为:


在运行过程中,Server 与 Proxy 进行交互,从 Proxy 接收游戏信息,向 Proxy 发送游戏动作,代码如下:

6.5 Proxy 代码
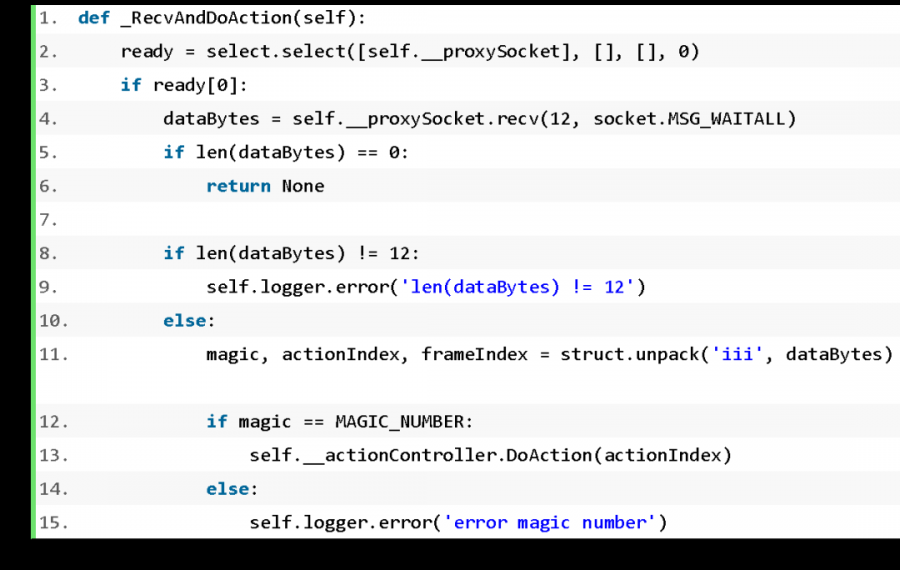
Proxy 从 worker 线程接收动作,在动作执行后将新的游戏信息返回给 worker 线程,保证训练可以循环进行,代码如下:


7. 实验
7.1 参数设置
PPO 的训练参数很多,这里介绍几个重要参数的设置:
- 学习速率:Actor 和 Critic 的学习率都设置为 1e-5
- 优化器:Adam 优化器
- Batch Size: 20
- 采样帧率:10 帧/秒
- 更新次数:15 次
- 激励折扣率:0.9
7.2 AI 效果
7.3 数据分析
表 1 和表 2 分别对比了不同并行数量和不同输入数据情况下 AI 跑完赛道和取得名次的训练数据。
最快的训练过程是在并行数量为 3 和输入数据为小地图的情况下,利用 PPO 训练 24 分钟就可以让 AI 跑完赛道,训练 7.5 小时就可以让 AI 取得第一名(和内置 AI 比赛)。并且在减少一部手机采样的情况下,也可以达到相同的训练效果,只是训练过程耗时更长一点。另外,如果将输入数据从小地图换成全图,AI 的训练难度会有一定程度的增加,不一定能达到相同的训练效果。
表 1 AI 跑完赛道的数据对比


如 7 展示了利用 PPO 训练 AI 过程中激励的趋势图,曲线上每一个点表示一局累计的总激励。训练开始时,AI 经常撞墙,总激励为负值。随着训练次数的增加,总激励快速增长,AI 撞墙的几率很快降低。当训练到 1400 多次时,总激励值超过 400,此时 AI 刚好可以跑完赛道。之后的训练过程,总激励的趋势是缓慢增长,AI 开始寻找更好的动作策略。

8. 总结
本文介绍了如何使用 TensorFlow 实现 Distributed PPO 算法在 24 分钟内让 AI 玩飞车类游戏。当前的方法有一定训练效果,但是也存在很多不足。
目前,我们想到以下几个改进点,以后会逐一验证:
- 将 AlexNet 替换为其他卷积神经网络,如 VGG、Inception-V3 等等,提高特征提取的表达能力;
- 提高并行数量,添加更多手机和电脑,提高采样速度和计算速度;
- 增加 Batch Size,使用较长的时间序列数据训练 AI;
- 将离散动作替换为连续动作,增加漂移的学习;
- 多个关卡同时训练,提高 AI 的泛化能力。















 1619
1619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









