









1.1 IO
Hadoop中,系统结点上进行间的通信通过RPC实现的,其将消息序列化成二进制流后发送给远程结点,远程节点将二进制流反序列化成员是消息。
Writable接口定义了write(DataOutput)和readFields(DataInput)两个方法;WritableComparable接口继承至Writable和Comparable接口,MapReduce中的key均需要实现该接口;
1.2 RPC
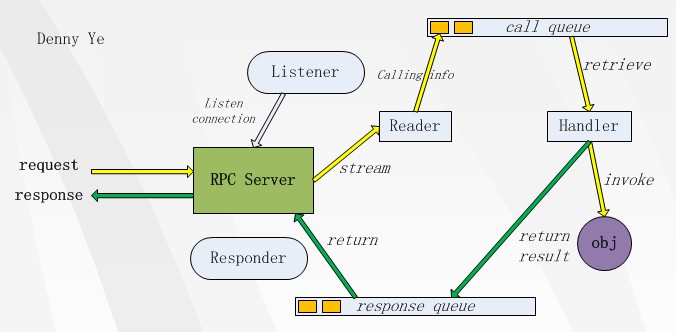
采用线程池,将消息的处理进行拆分多线程执行,并且每个现成根据网络情况返回给客户端相应的response。
RPC 为整个系统运行的前提
1.3 FileSystem

所有以上都可以通过URI访问,比如:
hadoop dfs -lsr har:///user/hadoop/foo.har
hadoop dfs -cat har:///user/hadoop/foo.har/dir/filea
hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
hadoop fs -cat file:///file3 /user/hadoop/file4
API:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set(“fs.default.name”, “hdfs://xxx.xxx.xxx.xxx:9000”);
HarFileSystem fs = new HarFileSystem();
fs.initialize(new URI("har:///user/heipark/20120108_15.har"), conf);
FileStatus[] listStatus = fs.listStatus(new Path("sub_dir"));
for (FileStatus fileStatus : listStatus) {
System.out.println(fileStatus.getPath().toString());
}
}
1. public class FileSystemCat {
2. public static void main(String[] args) throws Exception {
3. String uri = args[0];
4. Configuration conf = new Configuration();
5. FileSystem fs = FileSystem.get(URI.create(uri), conf);
6. InputStream in = null;
7. try {
8. in = fs.open(new Path(uri));
9. IOUtils.copyBytes(in, System.out, 4096, false);
10. } finally {
11. IOUtils.closeStream(in);
12. }
13. }
14. }
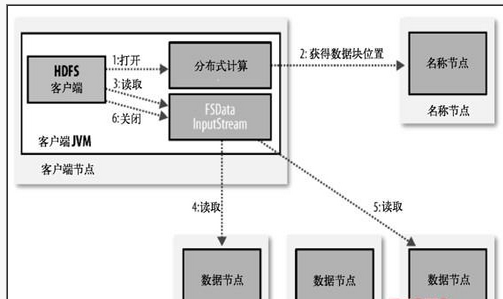
HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
HBase则可以达到高速查询的目的















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









