







Exact Adversarial Attack to Image Captioning via Structured Output Learning with Latent Variables
时间:2019 CVPR
Intro
深度神经网络对于恶意样本是很脆弱的,即便这些样本和普通样本看起来几乎没有区别,大多数对于这一问题的研究都是基于卷积神经网络的任务(图像分类、目标检测),它们的损失函数输出都是独立的,因此很容易通过梯度来生成恶意噪声(adversarial noises),然而对于结构化的输出,这个梯度就很难计算,比如image caption
给一个训练好的CNN+RNN的image caption模型,通过添加恶意噪声我们想要欺骗模型来输出目标部分输出(targeted partial caption),它与图像的内容完全无关,这个任务称为exact adversarial attack of targeted partial captions,以前的工作中还未被研究过,如图所示

一个目标部分输出(targeted partial caption)指的是某些位置的词是确定的,而其他位置的词没有指定,或者说是latent的,当所有位置的词都被指定,这就是一个targeted complete caption,如上图©所示
本文的贡献:
- 首次提出targeted partial caption的学习
- 将问题形式化为带隐变量的结构化输出学习
- state-of-the-art的Image caption模型可以被很容易的攻击
- 使用攻击方法来理解image caption的内层机理
Structured Outputs of CNN+RNN based Image Captioning Systems
给定CNN+RNN模型以及参数
θ
\theta
θ,和一张不稳定的图片
I
=
I
0
+
ϵ
∈
[
0
,
1
]
I=I_0+\epsilon \in [0,1]
I=I0+ϵ∈[0,1],caption
S
S
S的后验概率为
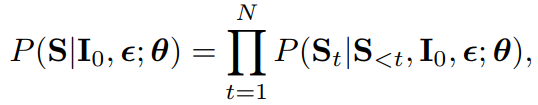
其中
I
0
I_0
I0是普通的图片,
ϵ
\epsilon
ϵ是恶意噪声,
S
=
S
1
,
S
2
,
.
.
.
,
S
N
S={S_1,S_2,...,S_N}
S=S1,S2,...,SN
partial caption 记为
S
O
S_\mathcal{O}
SO,意味着位置
O
\mathcal{O}
O上的词被指定了,
O
⊂
1
,
2
,
.
.
.
,
N
\mathcal{O}\subset{1,2,...,N}
O⊂1,2,...,N,latent variable记为
S
H
S_\mathcal{H}
SH,则partial caption的后验概率
S
O
S_\mathcal{O}
SO记为

其中
∑
S
H
\sum_{S_\mathcal{H}}
∑SH表示在所有可能的latent variables
S
H
S_\mathcal{H}
SH上求和
Adversarial Attack of Targeted Partial Captions to Image Captioning
learning ϵ \epsilon ϵ,学习目标是让预测的caption S S S和 S O S_\mathcal{O} SO尽可能兼容,因此,在最小化恶意误差的同时,需要采用以下两者之一的criterion:(1)最大化log marginal likelihood l n P ( S O = S O ∣ ϵ ) lnP(\mathbf{S}_\mathcal{O}=S_\mathcal{O}|\epsilon) lnP(SO=SO∣ϵ)(2)最大化目标caption和其他caption之间的margin, l n P ( S O = S O ∣ ϵ ) lnP(\mathbf{S}_\mathcal{O}=S_\mathcal{O}|\epsilon) lnP(SO=SO∣ϵ), l n P ( S O 不 等 于 S O ∣ ϵ ) lnP(\mathbf{S}_\mathcal{O}不等于S_\mathcal{O}|\epsilon) lnP(SO不等于SO∣ϵ)
Inference,给定最优的
ϵ
\epsilon
ϵ,caption生成为
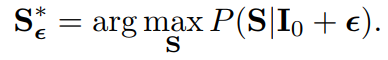
Maximizing Log Marginal Likelihood via Generalized EM Algorithm
根据第一个criterion,目标函数为
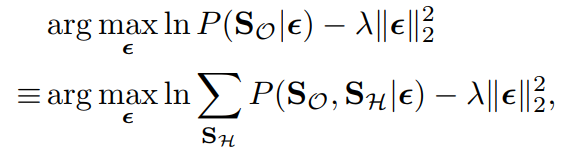
并满足约束
I
0
+
ϵ
∈
[
0
,
1
]
I_0+\epsilon\in[0,1]
I0+ϵ∈[0,1],这个约束可以通过clipping满足,因为要计算
∑
S
H
\sum_{S_{\mathcal{H}}}
∑SH,所以难以优化,为了解决这个问题,我们使用了generalized expectation maximization(GEM)算法,GEM的核心思想是利用factorized posterior
q
(
S
H
)
=
∏
t
∈
H
q
(
S
t
)
q(S_\mathcal{H})=\prod_{t\in\mathcal{H}}q(S_t)
q(SH)=∏t∈Hq(St)来逼近posterior probability
P
(
S
H
∣
S
O
,
ϵ
)
P(S_H|S_\mathcal{O},\epsilon)
P(SH∣SO,ϵ)
Structural SVMs with Latent Variables
根据第二个criterion,恶意噪声
ϵ
\epsilon
ϵ是通过带隐变量的结构化SVMs得到的

优化时通过优化它的两个子问题进行
Experiments
实验在Show-Attend-and-Tell、SCST和show-and-tell上进行,并与show-and-fool进行对比




passive attack

untargeted attack

Conclusion
本文提出了一种欺骗CNN+RNN的image caption模型的方法,将问题形式化为生成结构化输出的学习问题,使用了两个不同的criterion来进行优化,结果表明,我们的模型能很容易地欺骗SoTA的image caption 模型,表明了当前的image captioning模型与人类captioning相去甚远















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









