







本期内容:
1解密Spark Streaming运行机制
2解密Spark Streaming架构
一切不能进行实时流处理的数据都是无效的数据。在流处理时代,SparkStreaming有着强大吸引力,而且发展前景广阔,加之Spark的生态系统,Streaming可以方便调用其他的诸如SQL,MLlib等强大框架,它必将一统天下。
Spark Streaming运行时与其说是Spark Core上的一个流式处理框架,不如说是Spark Core上的一个最复杂的应用程序。如果可以掌握Spark streaming这个复杂的应用程序,那么其他的再复杂的应用程序都不在话下了。这里选择Spark Streaming作为版本定制的切入点也是大势所趋。
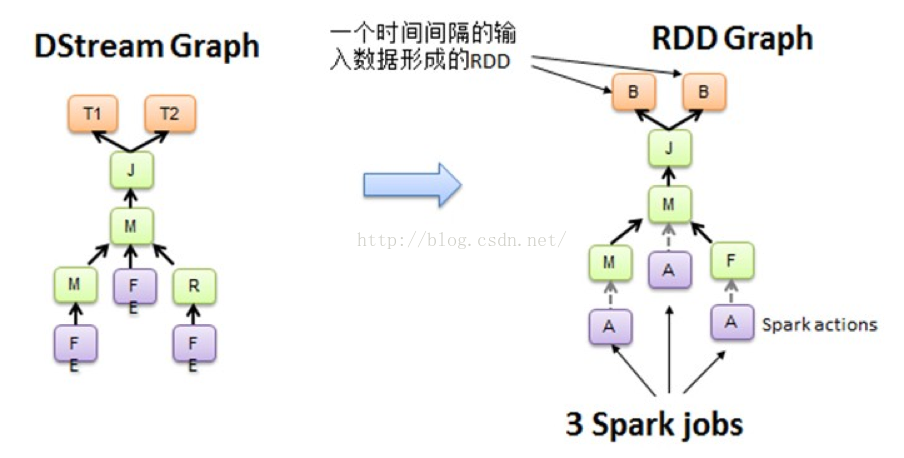
我们知道Spark Core处理的每一步都是基于RDD的,RDD之间有依赖关系。上图中的RDD的DAG显示的是有3个Action,会触发3个job,RDD自下向上依赖,RDD产生job就会具体的执行。从DSteam Graph中可以看到,DStream的逻辑与RDD基本一致,它就是在RDD的基础上加上了时间的依赖。RDD的DAG又可以叫空间维度,也就是说整个Spark Streaming多了一个时间维度,也可以成为时空维度。
从这个角度来讲,可以将Spark Streaming放在坐标系中。其中Y轴就是对RDD的操作,RDD的依赖关系构成了整个job的逻辑,而X轴就是时间。随着时间的流逝,固定的时间间隔(Batch Interval)就会生成一个job实例,进而在集群中运行。
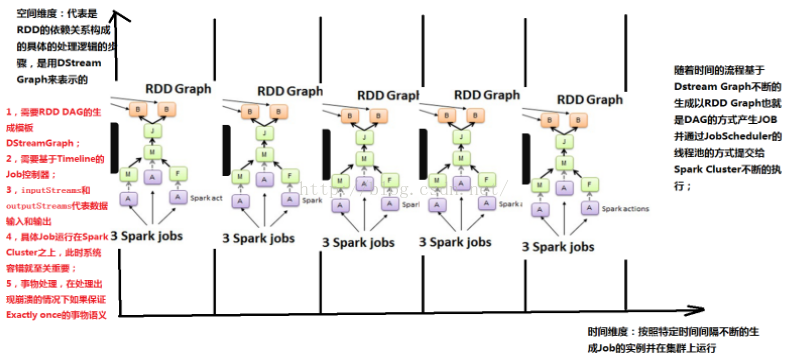
对于Spark Streaming来说,当不同的数据来源的数据流进来的时候,基于固定的时间间隔,会形成一系列固定不变的数据集或event集合(例如来自flume和kafka)。而这正好与RDD基于固定的数据集不谋而合,事实上,由DStream基于固定的时间间隔行程的RDD Graph正是基于某一个batch的数据集的。
从上图中可以看出,在每一个batch上,空间维度的RDD依赖关系都是一样的,不同的是这个五个batch流入的数据规模和内容不一样,所以说生成的是不同的RDD依赖关系的实例,所以说RDD的Graph脱胎于DStream的Graph,也就是说DStream就是RDD的模版,不同的时间间隔,生成不同的RDD Graph实例。
从Spark Streaming本身出发:
1.需要RDD DAG的生成模版:DStream Graph
2需要基于Timeline的job控制器
3需要inputStreamings和outputStreamings,代表数据的输入和输出
4具体的job运行在Spark Cluster之上,由于streaming不管集群是否可以消化掉,此时系统容错就至关重要
5事务处理,我们希望流进来的数据一定会被处理,而且只处理一次。在处理出现崩溃的情况下如何保证Exactly once的事务语意。
从源码解读DStream
/**
* A Discretized Stream (DStream), the basic abstraction in Spark Streaming, is a continuous
* sequence of RDDs (of the same type) representing a continuous stream of data (see
* org.apache.spark.rdd.RDD in the Spark core documentation for more details on RDDs).
* DStreams can either be created from live data (such as, data from TCP sockets, Kafka, Flume,
* etc.) using a[[org.apache.spark.streaming.StreamingContext]]or it can be generated by
* transforming existing DStreams using operations such as`map`,
*`window`and `reduceByKeyAndWindow`. While a Spark Streaming program is running, each DStream
* periodically generates a RDD, either from live data or by transforming the RDD generated by a
* parent DStream.
*
* This class contains the basic operations available on all DStreams, such as`map`,`filter`and
*`window`. In addition,[[org.apache.spark.streaming.dstream.PairDStreamFunctions]]contains
* operations available only on DStreams of key-value pairs, such as`groupByKeyAndWindow`and
*`join`. These operations are automatically available on any DStream of pairs
* (e.g., DStream[(Int, Int)] through implicit conversions.
*
* DStreams internally is characterized by a few basic properties:
* - A list of other DStreams that the DStream depends on
* - A time interval at which the DStream generates an RDD
* - A function that is used to generate an RDD after each time interval
*/
abstract classDStream[T: ClassTag] (
@transient private[streaming]var ssc: StreamingContext
)extends Serializablewith Logging {
validateAtInit()
// =======================================================================
// Methods that should be implemented by subclasses of DStream
// =======================================================================
/** Time interval after which the DStream generates a RDD */
def slideDuration: Duration
/** List of parent DStreams on which this DStream depends on */
def dependencies:List[DStream[_]]
/** Method that generates a RDD for the given time */
def compute(validTime: Time): Option[RDD[T]]
从这里可以看出,DStream就是Spark Streaming的核心,就想Spark Core的核心是RDD,它也有dependency和compute。更为关键的是下面的代码:
// RDDs generated, marked as private[streaming] so that testsuites can access it
@transient
private[streaming]var generatedRDDs= newHashMap[Time,RDD[T]] ()
这是一个HashMap,以时间为key,以RDD为value,这也正应证了随着时间流逝,不断的生成RDD,产生依赖关系的job,并通过jobScheduler在集群上运行。再次验证了DStream就是RDD的模版。
DStream可以说是逻辑级别的,RDD就是物理级别的,DStream所表达的最终都是通过RDD的转化实现的。前者是更高级别的抽象,后者是底层的实现。DStream实际上就是在时间维度上对RDD集合的封装,DStream与RDD的关系就是随着时间流逝不断的产生RDD,对DStream的操作就是在固定时间上操作RDD。
总结:
在空间维度上的业务逻辑作用于DStream,随着时间的流逝,每个Batch Interval形成了具体的数据集,产生了RDD,对RDD进行transform操作,进而形成了RDD的依赖关系RDD DAG,形成job。然后jobScheduler根据时间调度,基于RDD的依赖关系,把作业发布到Spark Cluster上去运行,不断的产生Spark作业。
自己理解欢迎喷:
1、dstream是对rdd的封装,一个dstream有多个rdd,一个rdd里有多个block;
2、例如从kafka中pull数据时,假如一个batchInterval的时间是2秒,sparkstreaming框架触发Job的时间间隔是6秒:
那么每个batchInterval 对应一个Dstream中的一个RDD,即有3个batchInterval对应3个RDD
18秒内会产生3个Dstream
3个Dstream 对应一个DstreamGraph
博主:罗白莲
资料来源于:王家林(Spark版本定制班课程)
新浪微博:http://www.weibo.com/ilovepains















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









