







本篇博文将从以下几点组织文章:
1. 解密Spark Streaming运行机制
2. 解密Spark Streaming架构
一:解密Spark Streaming运行机制
1. DAG生成模板 :DStreamGraph
a) Spark Streaming中不断的有数据流进来,他会把数据积攒起来,积攒的依据是以Batch Interval的方式进行积攒的,例如1秒钟,但是这1秒钟里面会有很多的数据例如event,event就构成了一个数据的集合,而RDD处理的时候,是基于固定不变的集合产生RDD。实际上10秒钟产生一个作业的话,就基于这10个event进行处理,对于连续不断的流进来的数据,就会根据这个连续不断event构成batch,因为时间间隔是固定的,所以每个时间间隔产生的数据也是固定的,基于这些batch就会生成RDD的依赖关系。b) 这里的RDD依赖关系是基于时间间隔中的一个batch中的数据。随着时间的流逝,产生了不同RDD的Graph依赖关系的实例,但是其实RDD的Graph的依赖关系都是一样的。DStream Graph是RDD的Graph的模板,因为RDD的Graph只是DStreamGraph上空间维度上的而已。c) 所以从整个Spark Streaming运行角度来看,由于运行在Spark Core上需要一种机制表示RDD DAG的处理逻辑,也就是空间维度,所以就产生了DStreamGraph.2. DStreamGraph就是RDD的静态模板,来表示空间的处理逻辑具体该怎么做,随着时间的流逝,会将模板实例化。
a) 如何实例化?就是在时间间隔中用数据来填充模板,然后就变成了RDD的Graph.b) 这个时候就需要一个感知时间,也就是所谓的动态的Job控制器,将不断流进来的数据,每流进来的数据从Spark Streaming的角度来说,他也会根据时间间隔将数据进行切分,并且按照我们的DStreamGraph的模板实例化RDD的DAG的具体实例来针对这个时间间隔产生的数据的集合进行处理。3. 静态的RDD的Graph模板 DStreamGraph.
动态的Job控制器:它会根据我们设定的时间间隔收集到数据让我们的DStreamGraph变成RDD DAG.
4. Spark Streaming流式系统:
a) DAG生成模板 :DStreamGraph
b) Timeline的Job生成:
c) 输入和输出流
d) 具体的容错
e) 事务处理:绝大多数情况下,数据流进来一定被处理,而且仅被处理一次。二:解密Spark Streaming架构
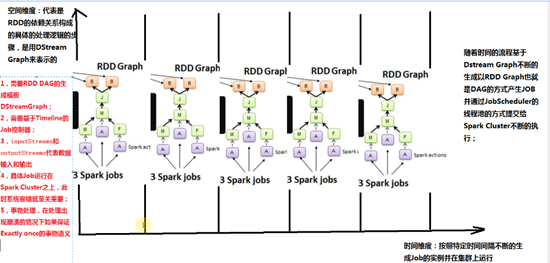
1. Spark Streaming系统的容错是基于DStreamGraph这个模板,不断的根据时间间隔产生Graph也就是DAG依赖的实例,产生具体的作业,作业具体运行时基于RDD,也就是对于单个Job的容错是基于RDD的。2. Spark Streaming是一个框架,本身也有自己的容错方式,例如数据接收的太多处理不完,这个时候Spark Streaming就会限流。3. Spark Streaming会根据数据的大小,动态的调整CPU和内存等计算资源。比如数据多的话,用更多的资源。DStream源码分析:
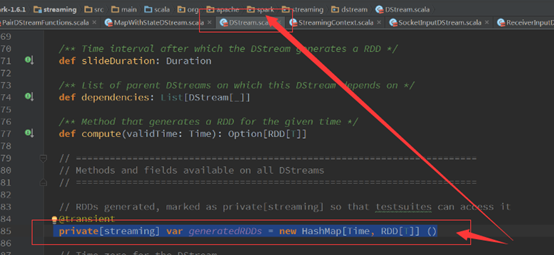
随着时间的流逝不断的产生DStream,然后根据DStream不断的产生RDD,根据RDD不断的产生Job,DStream之间有依赖关系,从源码中就可以了解到RDD的创建时在DStream中。
总结:
DStream是逻辑级别的,RDD是物理级别的。
DStream是RDD的模板,
DStream的依赖关系构成的DStreamGraph是RDD的DAG的模板。
DStream随着时间的序列生成一系列的RDD
DStream和RDD之间的关系随着时间的流逝不断产生RDD,















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









