







可以先看下线性表一,有个过渡,对线性表整体认识。http://blog.csdn.net/luobo140716/article/details/51263779
单链表的整表创建
对于顺序存储结构的线性表的整表创建,我们可以用数组的初始化来直观理解。
而单链表和顺序存储结构就不一样了,它不像顺序存储结构数据这么集中,它的数据可以是分散在内存各个角落的,他的增长也是动态的。
对于每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
创建单链表的过程是一个动态生成链表的过程,从“空表”的初始状态起,一次简历各元素节点并逐个插入链表。
所以单链表整表创建的算法思路如下:
1.生命一结点p和计数器变量i;
2.初始化一空链表L;
3.让L的头节点的指针指向NULL,即建立一个带头结点的单链表。
4.循环实现后继结点的赋值和插入。
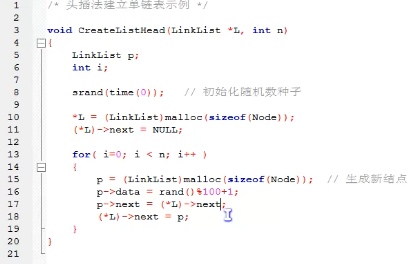
头插法建立单链表
头插法从一个空表开始,生成新结点,读取数据存放到新结点的数据域中,然后将新结点插入到当前链表的表头上,直到结束为止。
简单来说就是把新加进的元素放在表头后的第一个位置。
-先让新节点的next指向头节点之后。
-然后让表头的next指向新节点。
恩,用现实环境模拟的话就是插队的方法,始终让新结点插在第一的位置。
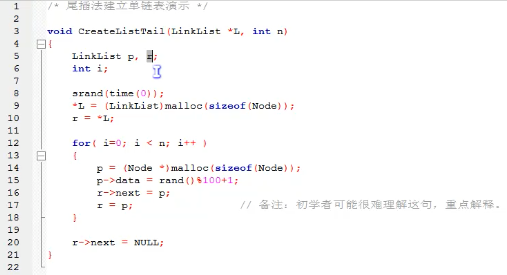
尾插法建立单链表
头插法建立链表虽然算法简单,但生成的链表中结点的次序和输入的顺序相反。
就像现实社会我们鄙视插队不遵守纪律的孩子,那编程中我们也可以不这么干,我们可以把思维逆过来,把新结点都插入到最后,这种算法称之为尾插法。(起一个艺名就是“菊花”)。
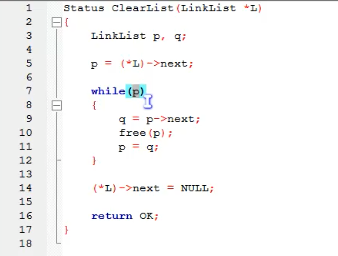
单链表的整表删除
单链表的删除其实也就是在内存中将它释放掉,以便于留出空间给其他程序或软件使用。
单链表整表删除的算法思路如下:
1.声明结点p和q。
2.将第一个结点赋值给p,下一个结点赋值给q。
3.循环执行释放p和q赋值给p的操作。
单链表的结构和顺序存储结构的优缺点
我们分别从存储分配,时间性能,空间性能三方面来做对比。
存储分配方式:
-顺序存储结构用一段连续的存储单元一次存储线性表的数据元素。
-单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素。
时间性能:
-查找
-顺序存储结构O(1)
-单链表O(N)
-插入和删除
-顺序存储结构需要平均移动表长一般的元素,时间为O(N)
-单链表在计算出某位置的指针后,插入和删除时间仅为O(1)
空间性能:
-顺序存储结构需要预分配存储控件,分大了,容易造成控件浪费,分小了,容易发生溢出。
-单链表不需要分配存储控件,只要有就可以分配,元素个数也不受限制。
总之,线性表的顺序存储结构和单链表结构各有其优缺点,不能简单的说哪个好,哪个不好,需要根据实际情况,来综合平衡采用哪种数据结构更能满足和达到需求和性能。
接下来要总结的就是静态链表,双链表和循环链表了~。
循环链表
对于单链表,由于每个结点只存储了向后的指针,到了尾部标识就停止了向后链的操作,也就是说按照这样的方式,只能索引后继结点不能索引前驱结点。
这会带来什么问题呢?
例如不从头结点出发,就无法访问到全部结点。事实上要解决这个问题也并不麻烦,只需要将单链表中终端结点的指针端由空指针改为指向头结点,问题就结了。
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表成为单循环链表,简称循环链表。

注意:这里并不是说循环链表一定要有头结点。其实循环链表的单链表主要差异就在于循环的判断空链表的条件上,原来判断head->next是否为Null,现在则是head->next是否等于head。
由于终端结点用尾指针rear指示,则查找终端结点是O(1),而开始结点是rear->next->next,当然也是O(1)。
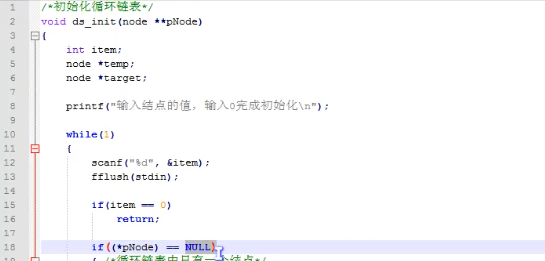
下图是循环链表的初始化:

下图是循环链表的插入结点操作
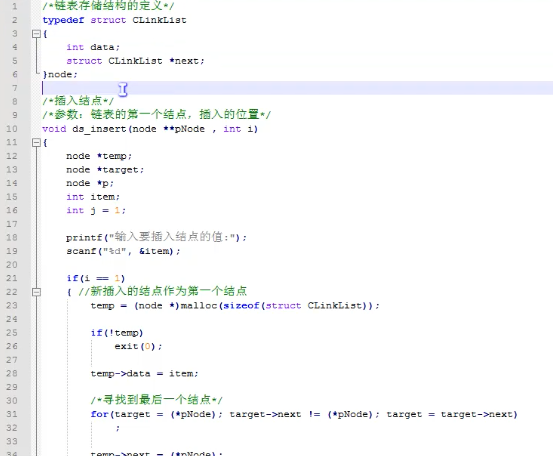

下图是讯款链表删除操作
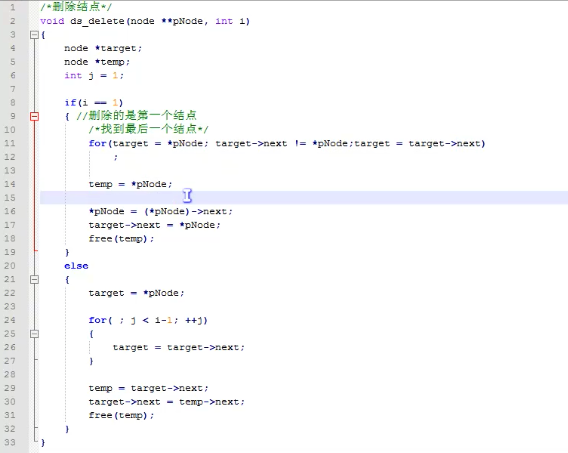
下图是返回循环链表的某个结点所在位置
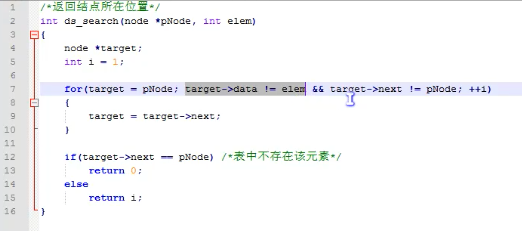
来一道经典面试题:
题目:快速找到未知长度单链表的中间结点。
既然是面试题就一定有普通方法和高级方法,而高级方法无疑会让面试官大大加分,那么我们分别介绍一下、
普通方法:
首先遍历一遍单链表以确定单链表的长度L。然后再次从头节点触发循环L/2次找到单链表的中间节点。
算法复杂度为:O(L+L/2)=O(3L/2).
高级方法(优化时间复杂度):
就是利用快慢指针的原理。设置两个指针*search,*mid都指向单链表的头节点。其中*search的移动速度是*mid的两倍。当*search指向末尾节点的时候,mid正好就在中间了。这也是标尺的思想。
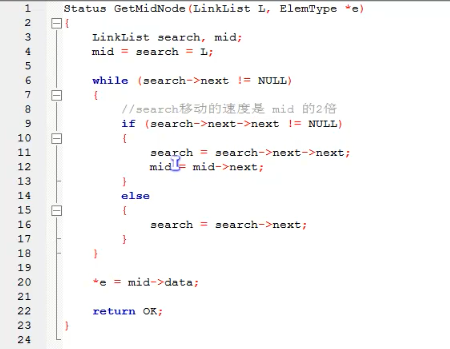
所以时间复杂度是O(L/2),比普通方法提高了三倍效率。
双向链表
大家都知道,任何事物出现的初期都显得有些不完善。例如我们的火车刚发明的时候是只有一个“头“的,所以如果它走的路线是如下:
A->B->C->D->E->F->G->H->I->J->K->L->A
假设这会儿火车正停在K处呢,要他送一批货到J处,俺么它将走的路线是:
K->L->A->B->C->D->E->F->G->H->I->J
恩,所以后来我们的火车就都有两个头了。看完这个例子,大家就明白双向链表的必要性了吧~
双向链表结点结构
typedef struct DualNode
{
ElemType data;
struct DualNode *prior;//前驱结点
struct DualNode *next;//后继结点
}DualNode,*DuLinkList;
既然单链表可以有循环链表,那么双向链表当然也可以有。
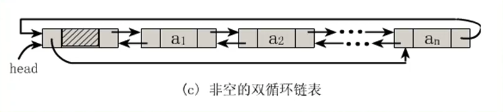
在这里问大家一个问题,由于这是双向链表,那么对于链表中的某一个结点P。它的后继结点的前驱结点是什么?答案很简单还是自己。
双向链表的插入操作
插入操作其实并不复杂,不过顺序很重要,千万不能写反了。
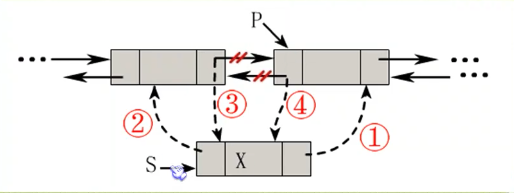
代码实现:
- s->next = p;
- s->prior = p->prior;
- p->prior->next = s;
-p->prior = s;
关键在于交换的过程中不要出现矛盾,例如第四步先被执行了,那么p->prior就会提前变成s,是的插入的工作出错。严重性打个比方就是打电话给老婆的时候不小心叫成了小三的名字。
双向链表的删除操作
如果双线链表的 插入操作理解了,那么再来理解接下来的删除操作就容易多了。
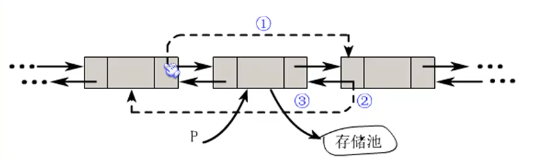
代码实现:
- p->prior ->next = p->next
- p->next ->prior = p->prior
- free(p)
总结一下,双向链表相对于单链表来说,是要更复杂一点,每个节点多了一个prior指针,对于插入和删除操作的属性怒大家要格外小心。
至此,线性表的博客系列到此全部结束,接下来就是数据结构 - 栈和队列的学习。















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









