







视频检索BLSTM方法论文翻译
Play and Rewind: Optimizing Binary Representations of Videos by Self-Supervised Temporal Hashing
Hanwang Zhang, Meng Wang, Richang Hong, Tat-Seng Chua
摘要
本文致力于用哈希方法将视频编码为简短的二进制码,以支持高效的基于内容的视频检索(CBVR),这是支持网络访问数量日益膨胀的视频的一项关键技术。现有的视频哈希函数基于三个互不相关的步骤:帧合并,松弛学习和二值化,这就无法充分利用视频帧在联合的二进制优化模型中的时序信息,导致严重的信息丢失。本文提出了一种新颖的无监督视频哈希框架,叫做自监督时序哈希(SSTH),能够以一种端到端的哈希学习方式捕获视频的时序性质。SSTH的哈希函数是一个RNN编码器,RNN配有本文提出的二进制LSTM(BLSTM),能够为视频生成二进制码。哈希函数由一种自监督方式学习得到,其中提出了一个RNN解码器来重建视频(正序和倒序)。为了二进制编码优化,本文用一个反向传播机制来应对BLSTM的不可导,它使得高效的深层网络学习免于二值化损失。在YouTube和Flickr的两个真实的用户视频数据集上实验,SSTH的表现均优于目前最优的哈希方法。
PS:关于哈希学习
1 介绍
基于内容的检索是很多多媒体应用的关键,以视觉内容为基础的大数据索引与查询。基于内容的图片检索目前已经得到大量研究,与之不同的视频检索尚未受到足够的注意。然而随着移动视频捕捉设备的普及,视频越来越多……(其他背景略去)。
视频不光光是一些帧。然而,目前视频分析工作通常会通过丢弃帧序列的时序特征,将多个帧级特征合并为单个视频的特征。当使用诸如CNN响应和运动轨迹之类的高维帧级特征时,这种帧包退化效果很好,因为在合并后,以高维编码的特定时序信息可以保留下来。但是,对于大规模的CBVR,其中需要将这些高维特征进行哈希处理(或进行索引处理)转变为简短的二进制代码时,由帧合并引起的时序信息丢失将不可避免地导致视频的次优编码(就是说不是最好的编码)。时序信息丢失通常发生在哈希函数学习的过程中,也就是帧合并的后一步;与主要的视频外观(例如,对象,场景和短期运动)相比,细微的视频动态(例如,长期事件演化)在哈希处理过程中急剧的特征降维时,更可能被当成噪声被丢弃。
我们认为造成上述缺陷的主要原因是时序合并和哈希码学习步骤都无法充分利用视频的时序本质。为此,我们提出了一种新的CBVR视频哈希方法,称为自监督时序哈希。 简而言之,SSTH是一种将m帧视频编码为单个k位二进制码的端到端系统。 本文着重介绍使得SSTH有效且与其他视频哈希方法不同的三个关键特征:
自监督
大多数现有的无监督哈希方法都不具备时序感知能力,因此失去长期的视频动态。因此,我们探索了另一种无监督哈希方法:如何利用视频的帧顺序自监督二进制代码学习?为此,我们在编码器-解码器RNN框架内提出了一种称为“播放和倒带”的策略——在RNN哈希函数对视频进行编码之后(即“播放”),当且仅当同时成功地编码了视频的外观和动态效果时,输出的哈希码才能以特定的顺序解码这些帧(即“倒带”)。
时序感知
SSTH的哈希函数通过使用RNN精确地对帧的时间顺序进行编码,RNN在序列建模中特别有效。我们提出了一个新的循环模块,称为二进制长短时间记忆网络(BLSTM),其中视频在 t 时的二进制编码是在 t-1 时编码的函数。带有BLSTM的RNN以原则性的方式统一了时序建模和视频哈希方法,这样二进制编码有望捕获整个视频的长期动态。
优化的视频二进制表示
由于二进制编码学习的问题本质上是NP难,因此现有的视频哈希方法通常遵循三个阶段的过程:合并,松弛和二值化。步骤之间互不相关使得这些方法不理想。在提出的SSTH框架中,我们将时序建模和二进制编码学习转换为一个联合模型。我们开发了一种二进制反向传播机制,该机制可以解决SSTH的二进制性质而不会产生任何松弛。 这样,SSTH可以视为一个用于优化从视频到二进制编码转换的端到端无监督学习框架。 在离线训练阶段,训练视频由一系列帧级特征(深层CNN提取)表示。带有BLSTM的编码器RNN遍历该序列,生成一组哈希码,然后解码器RNN对其进行解码,以正向和反向顺序重建帧级特征序列。在优化过程中,重构误差会通过整个编码器/解码器RNN反向传播。在线检索阶段,可以将编码器RNN视为时间感知哈希函数,该函数为数据库视频和查询视频生成二进制哈希码。最后,将数据库哈希码索引到哈希表中以进行实际检索。
在离线训练阶段,训练视频由一系列帧级特征(深层CNN提取)表示。带有BLSTM的编码器RNN遍历该序列,生成一组哈希码,然后解码器RNN对其进行解码,以正向和反向顺序重建帧级特征序列。在优化过程中,重构误差会通过整个编码器/解码器RNN反向传播。在线检索阶段,可以将编码器RNN视为时间感知哈希函数,该函数为数据库视频和查询视频生成二进制哈希码。最后,将数据库哈希码索引到哈希表中以进行实际检索。
本文的贡献如下:
1)我们提出了一种新颖的无监督视频哈希框架,称为自监督时序哈希(SSTH)。据我们所知,SSTH是第一个原则上的视频哈希深度框架。它是一种优化的端到端方法,可以解决常规视频哈希方法中的缺点,例如对时间性质的忽视以及对合并,松弛和二值化的分离。
2)我们开发了一种名为二进制LSTM(BLSTM)的新型LSTM变体,它充当了时序感知哈希函数的基础。我们还开发了有效的反向传播机制,可以直接解决BLSTM二进制优化所面临的难题,而无需任何松弛。
3)我们通过结合前向和反向帧重建改进了传统的一阶编码器-解码器RNN。我们的策略是一种新颖的无监督学习目标,可以更好地对数据的时间性质进行建模。
值得一提的是,尽管SSTH是为视频哈希开发的,但实际上它是一个灵活且通用的框架,可以扩展以处理其他信号序列(如音乐和文本)的哈希问题。
2 相关工作
略
3 自监督时序哈希
在本节中,我们对提出的自监督时序哈希(SSTH)框架进行公式推导。首先,我们介绍提出的时序感知哈希函数,该函数为视频序列生成单个压缩的二进制编码。然后,我们提出了一种新型循环单元BLSTM,它是哈希函数的基础。最后,我们引入提出的用于哈希学习的自监督策略及其深度架构。
3.1 时序感知的哈希函数
假设一个由m帧构成的视频序列表示为矩阵V=(v1,…,vm)∈R(d×m),其中第 t 帧用一个特征向量vt∈R(d)表示。我们的目的是找到一个哈希函数H:V∈R(d×m)→ bm∈{±1}k,(也就是把矩阵V映射到k位二进制码bm,±1序列加一再除以2就变成01序列了),k<<d。为了捕获视频的时序性质,我们要求哈希函数是时序感知的,举个栗子,V’是由V列置换得到的,但bm’不一定等于bm。假设前t-1帧的编码bt-1足以表示前 t 帧Vt-1,则有长度为 t 帧的序列哈希编码bt取决于前t-1帧的序列哈希编码bt-1,以及当前帧vt。
很自然地想到用RNN来满足上述时序感知的要求,循环单元的第 t 次输出bt可以用一个非线性函数 f 来表示,函数的输入包括上一次循环单元的输出bt-1和当前帧vt。
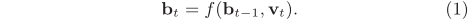
因此,视频V的结果二进制编码可以通过循环生成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









