







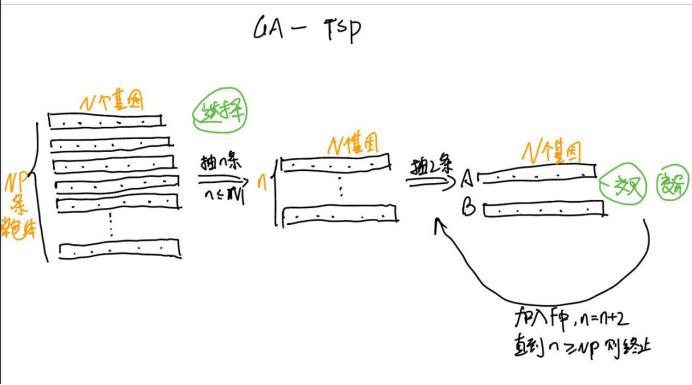
🧡🧡实验内容🧡🧡
用遗传算法求解不同规模(例如 10 个城市、20 个城市100个城市)的 TSP 问题
🧡🧡代码🧡🧡
代码主要思路
定义染色体:一条染色体代表行走路径,其上的基因代表城市编号
Ex:染色体:[5,1,2,3,4],,代表5->1->2->3->4->5。
定义适应度函数:路径之间的距离和,是使得这个值最小
Ex:染色体:[5,1,2,3,4],,代表 min( len(5->1) + len(1->2) + len(2->3) + len(3->4) + len(4->5) )。
clear all;
close all;
clc;
%% 初始化参数
n = 20; % 城市数量
% 设置随机数生成器的种子
seed = 128; % 设置种子值
rng(seed); % 使用种子值设置随机数生成器
x = datasample(0:5000, n, 'Replace', false); % 生成不重复的 x 坐标
y = datasample(0:5000, n, 'Replace', false); % 生成不重复的 y 坐标
% 生成城市坐标
C = [x; y]';
N=size(C,1); %TSP问题的规模,即城市数目 (31个),染色体的基因数目
D=zeros(N); %任意两个城市距离间隔矩阵
%% 求任意两个城市距离间隔矩阵
for i=1:N
for j=1:N
D(i,j)=((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5;
end
end
NP=100; % 种群数目 染色体条数
G=500; % 遗传代数
pc=0.85; % 交叉概率
pm=0.15; % 变异概率
f=zeros(NP,N); % 用于存储种群 每一行代表一条染色体
F = []; % 种群更新中间存储
for i=1:NP
f(i,:)=randperm(N); % 随机生成初始种群
end
best_f = f(1,:); % 存储最优种群
len=zeros(NP,1); % obj:走完所有城市总共要走的路径长度
fitness = zeros(NP,1); % 归一化后的len
gen = 0;
%% 遗传算法循环
tic;
while gen<G
%% 计算路径长度
for i=1:NP % 计算所有染色体
len(i,1)=D(f(i,N),f(i,1)); % 初始化 为城市1到城市终点N的路径长度
for j=1:(N-1)
len(i,1)=len(i,1)+D(f(i,j),f(i,j+1)); % 走完所有城市总共要走的路径长度:(1,N)+(1,2)+(2,3)+....(N-1,N)
end
end
maxlen = max(len);
minlen = min(len);
%% 更新最短路径
rr = find(len==minlen); % 可能有多个相等的min
best_f = f(rr(1,1),:); % 这里取第一个min, best_f代表路径距离len最短的那条路径(怎么个走法)
%% 计算归一化适应度
for i =1:length(len) % NP fitness=归一化后的路径长度
fitness(i,1) = (1-((len(i,1)-minlen)/(maxlen-minlen+0.001))); % fitness = - len,即要len越小,fitness则越大
end
%% 选择操作
% 随机选择
% nn = 0;
% for i=1:NP
% if fitness(i,1)>=rand % rand = 0-1的某个数
% nn = nn+1;
% F(nn,:)=f(i,:);
% end
% end
% 轮盘赌选择
nn=30;
F=zeros(nn,N);
total_fitness = sum(fitness);
selection_prob = fitness / total_fitness;
cumulative_prob = cumsum(selection_prob);
rng('shuffle');
r = rand(nn, 1); % 生成一组随机数
for i=1:nn
select=find(cumulative_prob>=r(i)); % 下标数组
select_idx=select(1); % 事件序号
F(i,:)=f(select_idx,:);
end
[aa,bb] = size(F); % aa<=NP=200:选出的染色体数目 bb=N=31:染色体基因个数
while aa<NP
% 每次循环选出两条染色体
nnper = randperm(nn); % 对数字1-nn随机打乱
A = F(nnper(1),:);
B = F(nnper(2),:);
%% 交叉操作
if rand<=pc % 交叉概率
W = ceil(N/10); % 交叉点个数
p = unidrnd(N-W+1); % 交叉点范围,随机起始点p,从p到p+W
for i =1:W
x = find(A==B(p+i-1)); % 先记录要交换的位置
y = find(B==A(p+i-1));
temp = A(p+i-1);
A(p+i-1) =B(p+i-1);
B(p+i-1) = temp;
temp = A(x); % 确保所有城市只走一次,即A、B中元素均为1-31,不重复
A(x) = B(y);
B(y) = temp;
end
end
%% 变异操作
if rand<=pm % 变异概率
p1 = floor(1+N*rand()); % N*rand()可能<1,因此+1确保>1, floor向下取整
p2 = floor(1+N*rand());
while p1==p2 % 确保 p1!=p2
p1 = floor(1+N*rand());
p2 = floor(1+N*rand());
end
% % 逆转变异:计算变异前的路径长度大小
% L1_A=D(A(1,1),A(1,N));
% for k=1:(N-1)
% L1_A=L1_A+D(A(1,k),A(1,k+1));
% end
% L1_B=D(B(1,1),B(1,N));
% for k=1:(N-1)
% L1_B=L1_B+D(B(1,k),B(1,k+1));
% end
% 交换位置
tmp = A(p1);
A(p1) = A(p2);
A(p2) = tmp;
tmp = B(p1);
B(p1) = B(p2);
B(p2) = tmp;
% % 逆转变异:计算变异后的路径长度大小
% L2_A=D(A(1,1),A(1,N));
% for k=1:(N-1)
% L2_A=L2_A+D(A(1,k),A(1,k+1));
% end
% L2_B=D(B(1,1),B(1,N));
% for k=1:(N-1)
% L2_B=L2_B+D(B(1,k),B(1,k+1));
% end
% if L2_A>L1_A % 如果变异后距离变大,则换回来
% tmp = A(p1);
% A(p1) = A(p2);
% A(p2) = tmp;
% end
% if L2_B>L1_B % 如果变异后距离变大,则换回来
% tmp = B(p1);
% B(p1) = B(p2);
% B(p2) = tmp;
% end
end
F = [F;A;B]; % 添加经过选择、交叉、变异过后的A、B两条染色体
[aa,bb] = size(F);
end
if aa>NP
F = F(1:NP,:); % 保持种群规模为NP
end
f = F; % 更新种群
f(1,:) = best_f; % 保留每代最优个体
clear F;
gen = gen+1;
Rlength(gen) = minlen;
end
elapsed_time = toc;
%% 绘制图形
figure
for i = 1:N-1
plot([C( best_f(i),1),C( best_f(i+1),1)],[C( best_f(i),2),C( best_f(i+1),2)],'bo-');
hold on;
end
plot([C( best_f(N),1),C( best_f(1),1)],[C( best_f(N),2),C( best_f(1),2)],'ro-'); % 终点和起点用红线连起来
title(['优化最短距离:',num2str(minlen)]);
figure
plot(Rlength)
xlabel('迭代次数')
ylabel('目标函数值')
title('适应度进化曲线')
fprintf("最短距离: %d\n",min(Rlength()));
fprintf("最坏适应度: %d\n",max(Rlength()));
fprintf("平均适应度: %d\n",mean(Rlength()));
disp("程序运行时间为:" + elapsed_time + " 秒");
🧡🧡实现流程🧡🧡
设置的主要参数如下:
种群规模:200
迭代数:1000
交叉概率:0.8
变异概率:0.1
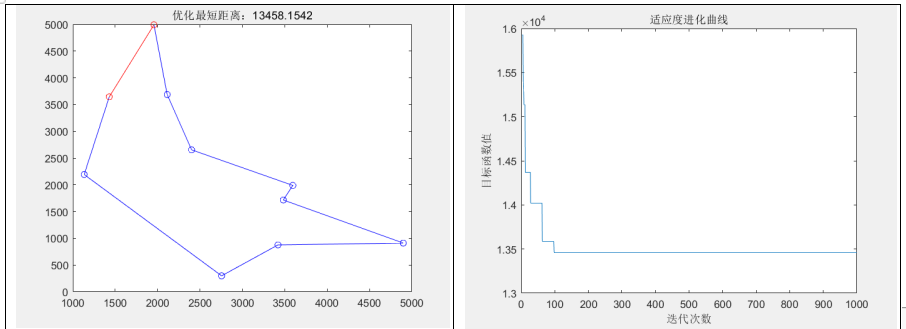
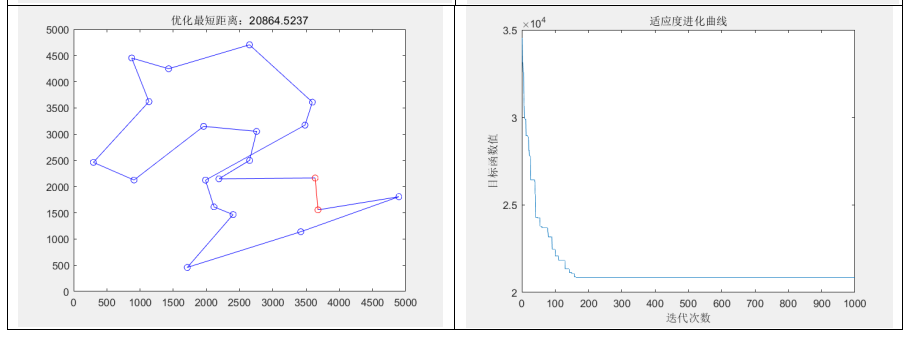
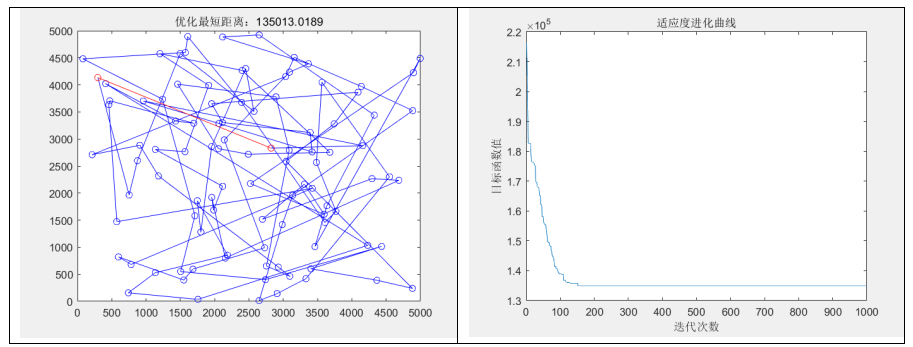
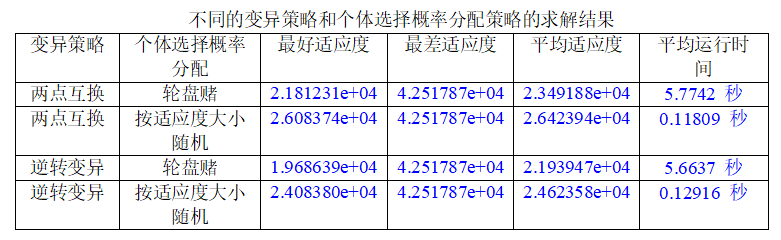
通过分别随机生成城市规模为10、20、100,计算它们的最好、最差、平均适应度,以及平均运行时间如下表
分析实验结果可知:
- 最好适应度、最差适应度和平均适应度:
从实验结果来看,随着问题规模的增加,最好适应度、最差适应度和平均适应度都呈现上升趋势。这是因为随着问题规模的增加,搜索空间变得更大,相应地需要更多的迭代次数才能找到较优解。同时,最差适应度和平均适应度也受到局部最优解的影响,可能会出现波动。- 平均运行时间:
随着问题规模的增加,平均运行时间也呈现增加的趋势。这是因为较大规模的 TSP 问题需要更多的迭代次数和计算量才能收敛,从而导致算法的运行时间增加。例如,在实验中观察到,当问题规模从10增加到100时,平均运行时间从0.56566秒增加到1.7829秒。- 同时,发现当城市规模到达100时,求解的路径不如人意,一方面可能是种群规模设置小了,(100个基因,只配200个染色体显然不够合理),另一方面还可能是因为NP问题本身的限制。

增加一种变异策略和一种个体选择概率分配策略,比较求解同一 TSP 问题时不
同变异策略及不同个体选择概率分配策略对算法结果的影响。
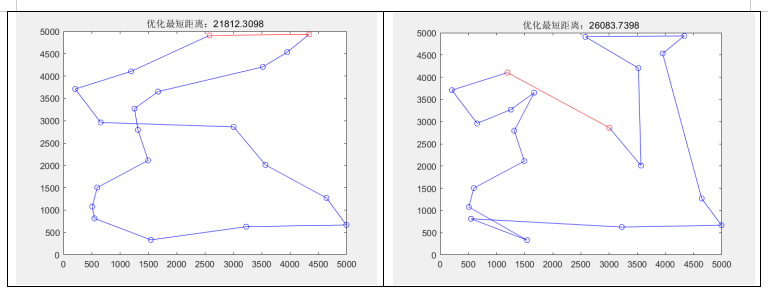
两点互换变异:左图采用轮盘赌选择,右图采用按适应度大小随机选择
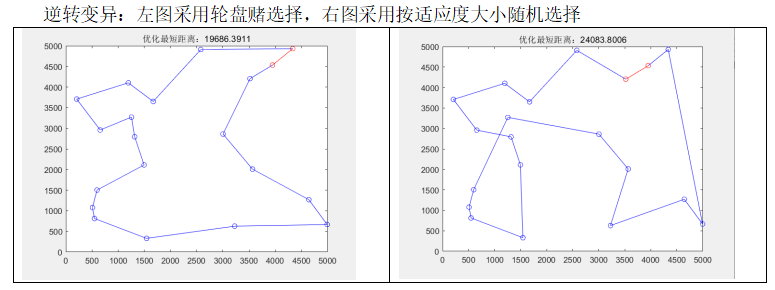
逆转变异:左图采用轮盘赌选择,右图采用按适应度大小随机选择
分析最优适应度和路径图可知:
- 轮盘赌选择相比适应度随机选择:
从结果来看,轮盘赌寻找最优值的能力更强,它可以根据个体适应度的相对大小进行选择,适应度高的个体有更高的概率被选中,从而增加了进化过程中优秀个体的保留概率,此外,较差的个体仍然有一定的机会被选中,这有助于防止种群陷入局部最优解,促进全局搜索。但由于需要涉及到排序、随机种子的问题,本实验中轮盘赌的运行速度稍微差了一些。- 两点变异和逆转变异:
实验中,逆转变异较两点变异的搜索能力有更好的提升,逆转变异在两点变异的基础上,增加了“反悔”的机制,即通过比较变异前后计算得出的适应度值,若变异后适应度变小,则“反悔”这次变异,变回变异之前的模样,这样,能确保变异后的个体总是更优秀的。
🧡🧡实验心得🧡🧡
本次实验使我更加直观地感受到启发式算法的魅力,如果在大二的时候,面对这种路径问题,我头脑可能第一反应是数据结构算法中的迪杰斯特拉和克鲁斯卡尔算法来求解,但它们对于求解这种NP Hard的问题运行效率十分低;而启发式算法能以极短的时间迅速接近最优解。
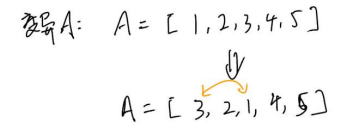
相比上个实验直接求解函数最值问题,TSP问题中对于染色体的交叉和变异又有进一步的要求,例如,为确保每个城市只走一次,因此染色体交叉前后,其上面的基因都应该满足含有城市编号1~N(N为城市个数),且各个基因不重复,因此采用如下交叉方式:
同理变异时,也需要保证各个基因不重复:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









