







记得读大学时,看课程信息,查分数,看美女(嘘)都会使用超级课程表APP,当时这款APP非常火爆,今天,就带领大家回到大学,看看大学生都在干嘛?
该文涉及内容:
- 爬虫简介
- 性别分布
- 高校分布
- 帖子时间
- 帖子词云
爬虫简介
这次爬虫和以往不同,利用fiddler抓包工具,爬取手机APP数据,爬取的内容为热门内容,总共只有150条,爬虫代码很乱,下次整理好再分享给大家。
数据分析
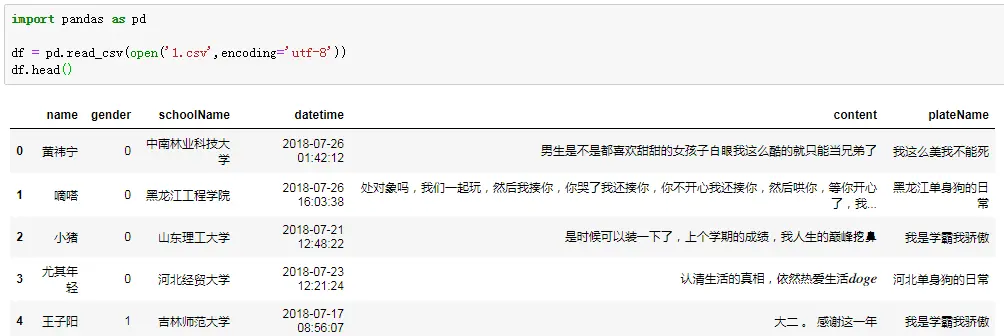
首先,我们看看数据情况。包括的字段有:
- 用户名
- 性别(0为女性)
- 学校
- 发帖时间
- 发帖内容
- 发帖标签
性别分布
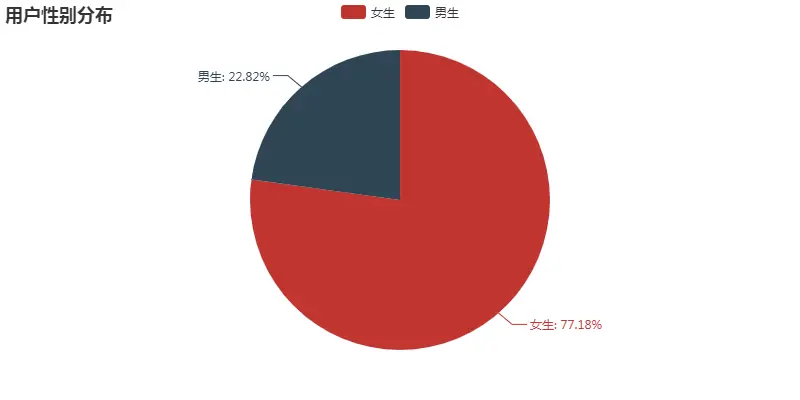
统计性别分布,通过图可以看出,女生占大多数,毕竟小姐姐上热门更为简单,随便爆个照,卖个萌,阅读妥妥的。
data1 = df.groupby('gender')['gender'].count()
from pyecharts import Pie
attr = ['女生', '男生']
v1 = list(data1)
pie = Pie('用户性别分布')
pie.add("", attr, v1, is_label_show=True)
pie
高校分布
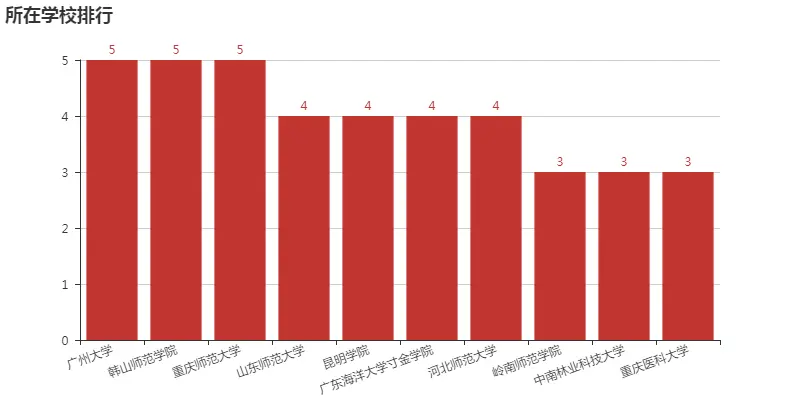
接着,我们看看哪些高校学生更喜欢玩超级课程表。由于数据量较少,代表性不够强,不过可以看出,师范类上榜更多,可能师范类小姐姐比较多吧。
data2 = df.groupby('schoolName')['schoolName'].count()
data2 = data2.sort_values(ascending=False)[:10]
from pyecharts import Bar
bar = Bar('所在学校排行')
attr = list(data2.index)
v2 = list(data2)
bar.add("", attr, v2,xaxis_interval=0,xaxis_rotate=20,xaxis_margin=8,is_label_show=True)
bar
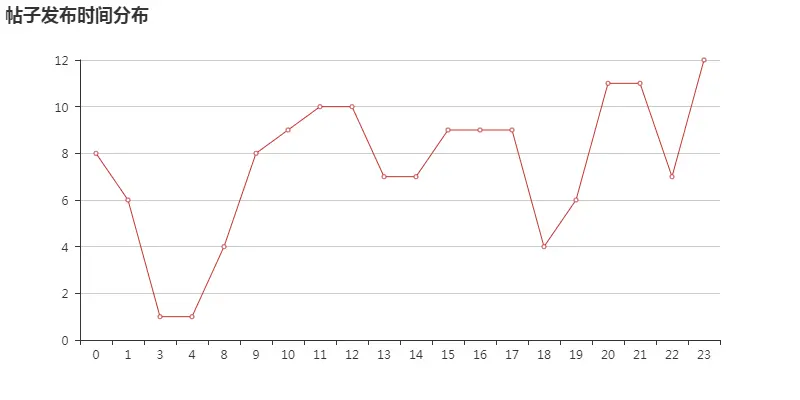
帖子时间
再来看看学生都爱啥时候发帖。首先,我们把时间字段当做字符串处理u最好转换为时间序列),获取小时。
如图可以看出,除了凌晨过后到早上10点,其余时间都爱发帖(大学生普遍0点过后睡,早上也起的比较晚)。他们可以说是,上课发、下课发,白天发,晚上发,skr。
df['hour'] = df['datetime'].str.split(':').str[0].str.split(' ').str[1]
data3 = df['hour'].value_counts()
data3 = data3.sort_index()
from pyecharts import Line
attr = list(data3.index)
v = list(data3)
line = Line("帖子发布时间分布")
line.add("", attr, v)
line
帖子词云
最后,我们来看看,发帖的词云,这里只是上部分代码。
大概可以分为两派:
- 学习备考考研约图书馆
- 单身小哥哥小姐姐求脱单
如果你要问我doge是什么,可能就是屏幕前的你吧。

from pyecharts import WordCloud
wordcloud = WordCloud(width=800, height=620)
wordcloud.add("", label, attr, word_size_range=[20, 100])
wordcloud

讨论
- 数据不多,代表性可能不强
- 珍惜大学时光,不要做后悔之事















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









