







一、文件类型
此处对文件进行分类是基于编码层次,主要分为:文本文件和二进制文件
1、文本文件
文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。
打开肉眼就能识别内容,可读性强
2、二进制文件
二进制文件是基于值编码的文件,你可以根据具体应用,指定某个值是什么意思。
用txt打开显示鬼码,可读性差
二、文件操作步骤
一般我们对文件进行操作,无非就是如下流程
1、打开文件,获取文件句柄
2、通过文件句柄去读取或者写入内容
3、把文件关掉
举个简单的栗子:
# 文件操作步骤.py
fp = open(r'E:\文件操作流程.txt','w')
fp.write('1、打开文件,获取文件句柄\n')
fp.write('2、通过文件句柄去读取或者写入内容\n')
fp.write('3、把文件关掉\n')
fp.close()
执行该文件成功后,则在本地E盘创建了一个名为《文件操作流程.txt》的文件,打开可以发现写入了内容
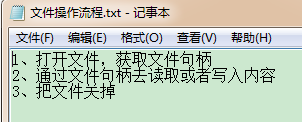
1、打开文件
语法:
file object = open(file_name [, access_mode][, buffering])
参数说明:
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值
access_mode:access_mode决定了打开文件的方式,比如读,或写,或读写等等
buffering: 如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认
2、读/写文件
假设我们获取的文件句柄名为:fp
2.1、读文件
语法:
fp.read() #每次读取整个文件,它通常用于将文件内容放到一个字符串变量中
fp.readline() #每次只读取一行
fp.readlines() #一次性读取文件所有行 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理
以上三种读文件方式的优缺点对比:

2.2、写文件
语法:
fp.write() #将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。 write()方法不会在字符串的结尾添加换行符('\n')
另外:
打开文件(fp.open())还有一个可选参数:encoding,即指定编码格式。该参数可以根据实际情况,选择是否添加
- 写文件时,如果没有指定编码格式,那么文件就会用默认的ANSI格式(GBK格式,适合中文),为了国际化,我们一般指定用UTF8
fp = open(r'E:\utf8编码格式文件.txt','w',encoding='utf8')
fp.write('以utf8编码格式写入的内容')
fp.close()
- 读文件时,文件本身是UTF8编码格式,如果用GBK编码格式读则会报错
如上面刚创建的《utf8编码格式文件.txt》文件,是以UTF8编码格式写入的,此时用GBK编码格式读,执行下面的代码,则会报错:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xa5 in position 2: illegal multibyte sequence
fp = open(r'E:\utf8编码格式文件.txt','r',encoding = 'gbk')
content = fp.read()
fp.close()
print(content)
- 读文件时,文件本身是GBK编码格式,如果用UTF8编码格式读,也会报错
如开头创建的《文件操作流程.txt》,我们没有指定编码格式,则会保存为默认的ANSI编码格式,此时我们指定用UTF8编码格式读该文件,执行下面的代码,则会报错:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd2 in position 0: invalid continuation byte
fp = open(r'E:\文件操作流程.txt','r',encoding = 'utf8')
content = fp.read()
fp.close()
print(content)
3、关闭文件
语法:
fp.close() #刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。 当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件,以释放系统资源。用 close()方法关闭文件是一个很好的习惯
每次打开文件操作完后,都要写一次close()方法关闭文件,显得有点繁琐,为了解决这个问题,Python引入了with语句来自动帮我们调用close()方法:
with open('/filepath/filename') as fp:
with作用:创建临时运行环境,运行环境中的代码执行完后自动安全退出环境。
建议:使用open进行文件操作时建议使用with创建运行环境,可以不用close()方法关闭文件,无论在文件使用中遇到什么问题都能安全的退出,即使发生错误,退出运行时环境时也能安全退出文件并给出报错信息。
三、文件操作方式
不同方式操作文件的完全列表:

再来一张文件操作方式的总结图

四、常用文件处理
1、txt文件处理
首先创建《stu_info.txt》文件
fp = open(r'E:\stu.info.txt','w',encoding='utf8')
fp.write('Jack,25,Beijing\nBob,22,Shanghai\nHarry,24,Shenzhen\n')
fp.close()
案例:读取stu_info.txt文件内容,并将所有文件中学生名称(第一列)显示出来
代码实现:
fp = open('E:\stu.info.txt','r')
lines = fp.readlines()
for line in lines:
print(line.split(',')[0])
2、csv文件处理
2.1、csv概念
csv即为逗号分隔值(Comma-Separated Values,CSV),有时也称为字符分隔值,因为分隔字符也可以不是逗号,其文件以纯文本形式存储表格数据(数字和文本)
2.2、csv文件读取
首先在本地E盘创建《stu_info.csv》文件,内容如下:

案例:读取stu_info.csv文件里所有学生信息
代码实现:
import csv
fp = csv.reader(open(r'E:\stu_info.csv','r'))
for stu in fp:
print(stu)
2.3、csv文件写入
2.3.1、追加写入
案例:对stu_info.csv文件追加写入两个学生信息
代码实现:
import csv
stu1 = ['Tom',12,'Shanghai']
stu2 = ['Jack',15,'Beijing']
out = open(r'E:\stu_info.csv','a',newline='') #以追加模式打开文件
csv_write = csv.writer(out,dialect = 'excel') #设定写入模式
csv_write.writerow(stu1) #写入具体的学生信息
csv_write.writerow(stu2)
print('写入完成')
2.3.2、覆盖写入
把上例中’a’改成’w’ 就是以覆盖的模式打开文件
3、xml文件处理
3.1、xml文件概念
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言
3.2、xml文件定义
<?xml version="1.0" encoding="utf-8"?>
<note>
<to id='001'>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
3.3、xml文件结构
- XML 文档形成了一种树结构,它从“根部”开始,然后扩展到“枝叶”
- 第一行是 XML 声明。它定义 XML 的版本 (1.0) 和所使用的编码
<note>是根元素,也称为根节点<to><from><heading><body>是子元素(子节点)- XML 文档必须包含根元素。该元素是所有其他元素的父元素
3.4、xml文件特征
- 由标签对组成
<aa></aa> - 标签可以有属性
<aa id='123'></aa> - 标签对可以嵌入数据
<aa>abc</aa> - 标签可以嵌入子标签(具有层级关系)
3.5、DOM文档对象模型
3.5.1、DOM概念
文档对象模型(Document Object Model,简称DOM),DOM 就是针对 HTML 和 XML 提供的一个API。
就是说为了能以编程的方法操作这个 HTML 的内容(比如添加某些元素、修改元素的内容、删除某些元素),
我们把这个 HTML或xml 看做一个对象树(DOM树),它本身和里面的所有东西比如<div></div>
这些标签都看做一个对象,每个对象都叫做一个节点(node)
3.5.2、DOM作用
可以操作 HTML或xml 中的元素,比如说我们要通过 JS 把这个网页的标题改了,直接这样就可以了:
document.title = 'new title'
3.6、xml文件节点
- 元素节点
- 文本节点
- 属性节点
每个节点又都有属性
- nodeName(节点名称)
- nodeValue(节点值)
- nodeType(节点类型)
3.7、xml文件读取
首先我们先创建一个《Class_info.xml》文件,代码如下:
<?xml version='1.0' encoding='UTF-8'?>
<Class>
<student>
<name>jack</name>
<age>28</age>
<city>beijing</city>
</student>
<student>
<name>bob</name>
<age>25</age>
<city>shanghai</city>
</student>
<student>
<name>harry</name>
<age>23</age>
<city>shenzhen</city>
</student>
<teacher>
<name>mary</name>
<age>23</age>
<city>changsha</city>
</teacher>
<acount>
<login username='student' password='123456'/>
<login username='teacher' password='888888'/>
</acount>
</Class>
3.7.1、读取元素节点
案例:查看Class_info.xml文件里Class节点的属性(结点名称,节点的值、节点类型)
代码实现:
# Get_NodeInfo.py
from xml.dom import minidom
dom = minidom.parse('Class_info.xml') #打开xml文件
root = dom.documentElement
print(root.nodeName)
print(root.nodeValue)
print(root.nodeType)
3.7.2、读取文本节点的值
案例:分别打印出Class_info.xml里的学生和老师的详细信息(姓名,年龄、城市)
代码实现:
# Get_NoteValue.py
from xml.dom import minidom
dom = minidom.parse('Class_info.xml') #打开文件
root = dom.documentElement #获取文档对象元素
names = root.getElementsByTagName('name') #根据标签名称获取标签对象
ages = root.getElementsByTagName('age')
citys = root.getElementsByTagName('city')
for i in range(4): #分别打印显示xml文档标签对里面的内容
print(names[i].firstChild.data)
print(ages[i].firstChild.data)
print(citys[i].firstChild.data)
3.7.3、读取属性节点的值
案例:分别打印出Class_info.xml文件里老师和学生的账号密码
代码实现:
# Get_NodeType.py
from xml.dom import minidom
dom = minidom.parse('Class_info.xml') #打开文件
root = dom.documentElement #获取文档对象元素
logins = root.getElementsByTagName('login') #根据标签名称获取标签对象
for i in range(2): #获取login标签的username属性
username = logins[i].getAttribute('username')
print(username)
password = logins[i].getAttribute('password')
print(password)
3.7.4、读取子节点信息
案例:读取Class_info.xml里的字节点student的属性(结点名称,节点的值、节点类型)
代码实现:
# Get_ChildNodeinfo.py
from xml.dom import minidom
dom = minidom.parse('Class_info.xml')
root = dom.documentElement
tags = root.getElementsByTagName('student')
print(tags[0].nodeName)
print(tags[0].nodeType)
print(tags[0].nodeValue)















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









