







在前面的例子里,我使用的是从雅虎财经获取的股票数据。要回测期权的话,需要导入从通达信获取的数据。如何下载和解析通达信期权数据请参考:利用BackTrader进行期权回测之一:获取期权数据
为了加载自己的数据,Backtrader提供了两种常用方法:
- 从CSV文件加载
- 从Pandas DataFrame加载数据
从DataFrame加载数据
如果我已经有了如下图这样一个dataframe:
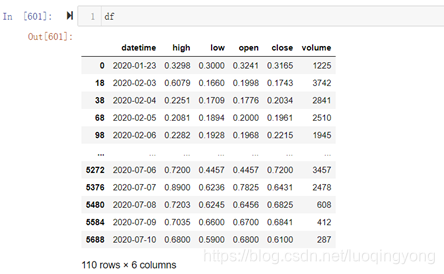
注意,backtrader要求至少有6列数据,包括:日期,最高价,最低价,开盘价,收盘价,成交量。
有个这个dataframe以后,加载数据就可以通过创建一个PandasData实例来实现:
from backtrader.feeds import PandasData
# 从dataframe加载数据
data = PandasData(dataname=df, datetime=-1)
# 添加数据到回测引擎
cerebro.adddata(data)
在创建PandasData的时候,参数datetime=-1表示“交易日期”通过列名自动识别。如果在dataframe中日期列的名称不是“datetime”,除了修改dataframe列名以外,还可以使用下面的方法。
- 通过一个字符串指定日期列的名称:
# 日期列的名称是“col_name”
data = PandasData(dataname=df, datetime='col_name')
- 或通过一个整数指定日期列在第几列:
# 日期列在第1列
data = PandasData(dataname=df, datetime=1)
如果datetime参数没有指定(相当于datetime=None),PandasData会尝试从dataframe的索引中获取日期。
其它列与之类似,可以使用标准的列名high,low,open,close,volume;也可以指定列的名称和位置。如果没有指定,则会自动根据列的名称去匹配。
加载数据以后,就可以在策略类中访问数据了。
添加额外的数据指标
对于期权来说,通常除了价格和成交量以外,还需要增加一些重要的指标,比如期权到期时间等。那么应该怎么办呢?
通过扩展一个新的数据加载类,可以很方便地在这个类中定义新增的数据。
现在我dataframe中新增了两列数据,分别是ttm(到期时间)和impvol(隐含波动率),如下图所示:
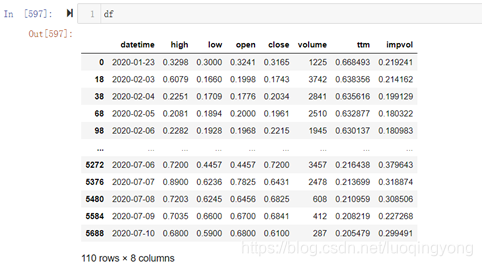
扩展后的数据加载类的代码如下:
class ETFOptionPandasData(PandasData):
# 新增两条数据线
lines = ('ttm', 'impvol',)
# 新增数据在dataframe中的位置,分别是第6列和第7列
params = (('ttm', 6), ('impvol',7), )
Backtrader把一列数据叫做一个line,所以新增两列数据需要增加两个line。
在Backtrader中添加数据特别方便的地方在于:只需要定义数据名称和位置,不用编写实现代码。
定义好扩展数据加载类以后,就可以创建类实例来加载数据了:
data = ETFOptionPandasData(dataname=df, datetime=-1)
cerebro.adddata(data)
新增数据在策略类中可以通过以下方式引用:
class SimpleStratedy(bt.Stratedy):
...
def next(self):
# 显示当天的收盘价
print(self.datas[0].close[0])
在Backtrader中,next方法会在每个交易日调用,close[0]表示“close”列在当天的值,close[-1]表示前一个交易日,close[-2]表示往前两个交易日,依次类推。
其中datas[0]的含义我在下面解释。
加载多个期权的数据
可能有些读者已经看出来了:dataframe数据里没有期权代码!那么要怎么知道交易哪个期权呢?
在Backtrader中,每只股票(或期权)的数据是一个数据流(data feed),如果有多个期权,那么就要为每个期权创建一个数据流。假设包含期权代码的dataframe数据如下:
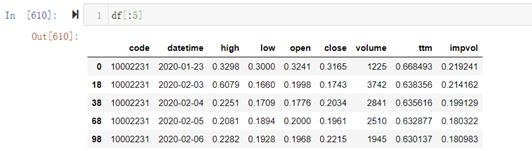
加载多个数据流的代码是:
for opt in list(set(df[‘code’])):
# 筛选出每个期权的数据并去掉“代码”列(第一列)
d = df[ df[‘code’] == opt ].iloc[:, 1:]
# 加载数据并添加到回测引擎
data = ETFOptionPandasData(dataname=d, datetime=-1)
cerebro.adddata(data, name=opt)
cerebro.adddata方法中的name=opt参数是给每个数据流一个名称,这里我使用期权代码作为数据流的名称。然后在程序里可以通过数据流名称来获取对应的数据流。
在交易的时候,在策略类里指定交易标的:
class SimpleStrategy(bt.Strategy):
…
def next(self):
for d in self.datas: # 循环处理每个期权的数据
if d.impvol[0] < 0.1:
self.buy(d, size=10000) # 指定买入期权和买入数量
elif d.impvol[0] > 0.5:
self.sell(d, size=10000) # 卖出标的和数量
这里的self.datas是一个列表,列表里的每个元素是一个数据流(data feed),也就是通过cerebro.adddata()添加的一个期权的数据。第1次调用adddata添加的是self.datas[0],第2次调用添加的是self.datas[1], 依次类推。所以前面提到的self.datas[0].close[0]就是第1个期权当天的收盘价。
除了通过序号访问data feed以外,也经常需要通过名称来访问,这可以通过self.getdatabyname()来实现。
class SimpleStrategy(bt.Strategy):
def next(self):
d = self.getdatabyname('option_name') # 通过名称获取data feed
self.buy(d, size=10000) # 使用获得的data feed买入期权
期权开始日期不一致问题
加载多个期权数据之后,出现了一个新问题:策略的next()方法只从最晚创建的期权开始交易的那一天才会被调用到。假设我们有3个数据流(Data Feed),其中:
- 期权0从1月23日开始交易
- 期权1从2月23日开始交易
- 期权2从3月23日开始交易
那么Backtrader引擎在回测的时候,只会从3月23日开始调用next()方法,而在此之前的日期则不会调用。
Backtrader这样的设计会带来一个大问题,期权是滚动创建的,这意味回测只能从data feed中最晚的期权开始交易那一天开始。这显然不是我想要的结果。怎么解决呢?
研究backtrader文档发现,一个策略的生命周期是这样的:
- 策略实例化:调用一次init()方法。
- 策略开始:调用一次start()方法
- 策略数据准备:每天调用prenext()方法。有些数据需要一定的准备时间,在这段时间里,每天会调用prenext()方法。比如前面提到的5日均线,需要5个交易日才能够产生第1个均线的值,因此在前4个交易日会每天调用prenext()。在数据准备完成,开始调用next()方法之后,prenext()不会再被调用。
- 策略执行:每天调用next()方法。在数据准备完成以后每天调用,主要实现策略的交易逻辑。
- 策略停止:调用一次stop()方法。
根据上面的说明,我可以在prenext()中调用next(),这样就可以在每个交易日都执行next()了。类似下面这样:
class SimpleStrategy(bt.Strategy):
…
def prenext(self):
# 调用next()方法
self.next()
def next(self):
for d in self.datas:
# 如果期权还未创建,跳过这条期权
if len(d) == 0 :
continue
由于现在每个交易日都会调用next(),调用的时候会出现有些期权有数据,而另一些期权还没有创建所以没有数据的情况。为了解决这个问题,可以在next()方法中用len(d)来判断期权是否有数据,如果期权还未开始则d的长度为0。
好了,现在解决了期权数据的加载问题,终于可以开始实现一个真正的期权策略了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









