







 1. 超分辨的概念与应用
1. 超分辨的概念与应用
我们常说的图像分辨率指的是图像长边像素数与图像短边像素数的乘积,比如iPhoneX手机拍摄照片的分辨率为 4032px×3024px,为1200万像素。
显然,越高的分辨率能获得更清晰的成像。与之同时,分辨率越高也意味着更大的存储空间,对于空间非常有限的移动设备来说,需要考虑分辨率与存储空间的平衡。
图像超分,就是要从低分辨率的图像恢复为高分辨率的图像,它在日常的图像和视频存储与浏览中都有广泛的应用。
10年前手机中320px×240px分辨率的图像是主流,其视觉美感相对如今随处可见的4K分辨率来说是无法比拟的。我们可以使用超分技术来恢复当年拍摄的低分辨率图像,如下图是一个典型案例。手机图片浏览中也有超分算法的努力,即同一张图片在不同手机上的显示效果不一样,是因为显示分辨率越高的手机可以使用更清晰的分辨率进行展示。

2. 超分辨的典型模型
近年来CNN等深度学习模型在图像超分任务中取得了非常大的进展,使得超分算法得以真正在产品中落地,目前根据上采样(upsampling)在网络结构中的位置和使用方式不同,最主流的超分网络架构有两种。
2.1 前上采样(pre-upsampling)
即在网络一开始的时候就完成上采样过程
Chao Dong等人提出的SRCNN方法是最早期的尝试,流程示意图如下图所示:
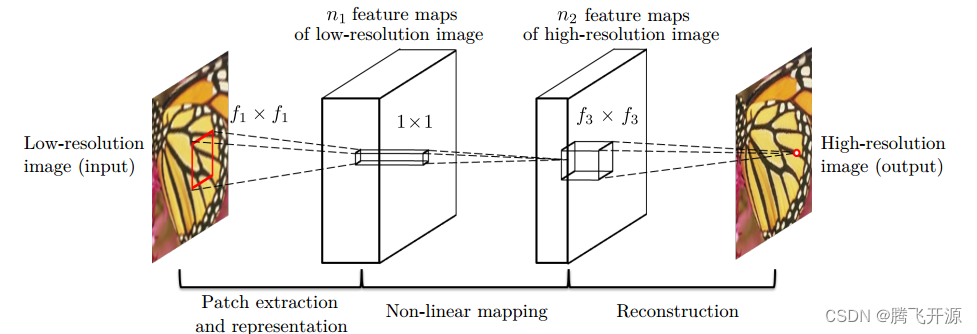
SRCNN框架首先使用双线性插值等上采样方法进行初始化,得到想要恢复的分辨率,这一步也可以使用反卷积来完成。 然后使用卷积层对输入的局部图像块进行特征提取,得到一系列特征图,这相当于完成了稀疏编码中重叠的图像块的构建,这一步骤可以表达如下:
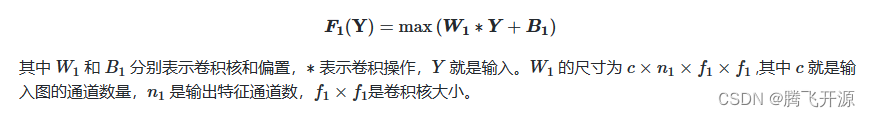
早期的超分算法常常只对亮度通道进行超分,颜色通道则进行双线性上采样。SRCNN算法则同时对RGB通道进行了学习,因为这三个通道之间存在较强的灰度耦合性。
接着,使用 1×1 卷积进行维度变换,即将 𝑛1𝑛1个特征通道转换为 𝑛2𝑛2 个特征通道,这就是相当于稀疏编码中低分辨率字典到高分辨率字典的映射,这一步骤可以表达如下:
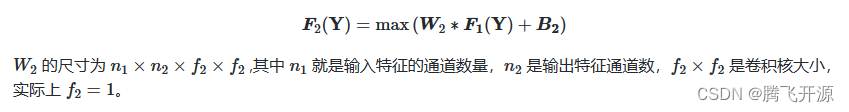
最后就是将高分辨率的图像块重新拼接成完整的图像,这一步骤可以表达如下:

SRCNN框架可以适用于任意分辨率的提升,因为在输入网络之前,上采样过程已经对输出分辨率做了初始化,所以CNN模型要学习的是由粗到精的改进,学习过程比较简单。不过由于整个网络在高分辨率空间进行计算,因此计算量大,而且噪声容易被放大。
SRCNN的整个流程与稀疏编码方法相同,因此它也被看作是使用CNN实现了稀疏编码的方案。
2.2 后上采样(post-upsampling)
即在网络的最后才开始进行上采样
在前上采样框架中首先使用反卷积来完成上采样是一种很自然的操作,但是它计算复杂度较大,因此SRCNN的作者后来将该上采样过程放置在网络最后端,通过一个反卷积来学习该上采样过程,将其命名为FSRCNN框架。而Twitter图片与视频压缩研究组则采用了与反卷积完全不同的上采样思路,提出了ESPCN模型,其中核心思想是亚像素卷积(sub-pixel convolution),完整流程示意图如下:

对于维度为H×W×C的图像,标准反卷积操作输出的特征图维度为rH×rW×C,其中r就是需要放大的倍数,而从上图可以看出,亚像素卷积层的输出特征图维度为H×W×C×r2,即特征图与输入图片的尺寸保持一致,但是通道数被扩充为原来的r2倍,然后再进行重新排列得到高分辨率的结果。
整个流程因为使用了更小的图像输入,从而可以使用更小的卷积核获取较大的感受野,这既使得输入图片中邻域像素点的信息得到有效利用,还避免了计算复杂度的增加,是一种将空间上采样问题转换为通道上采样问题的思路。
相比于前上采样中在开始就进行单一的一次上采样,后采样策略能更好地利用模型的表达能力,学习更加复杂的低分辩率到高分辨率的转换,因此ESPCN模型被验证为更加有效,后续的超分模型基本沿用了该思路。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











