






项目背景与目的
项目背景
在当今数字化和信息化的时代,聊天机器人在各个领域的应用越来越广泛。它们能够帮助企业提高客户服务效率,减少人力成本,并提供24小时不间断的服务。通过自然语言处理技术,聊天机器人可以理解用户的语言并作出相应的回答。
项目目的
本项目旨在开发一个基础的聊天机器人,能够处理简单的中文问答对话。通过这个项目,我们希望学习并实践自然语言处理和深度学习的相关技术,理解聊天机器人的工作原理,并探索其在实际应用中的潜力。
数据处理
数据来源
我们的数据主要来源于自行构建的问答对。为了满足至少200条数据的要求,我们手动编写了200条常见的中文对话。这些数据涵盖了日常生活中的常见问题和回答。
数据预处理
数据预处理是自然语言处理中的重要步骤。主要包括文本清洗、分词、编码和填充。
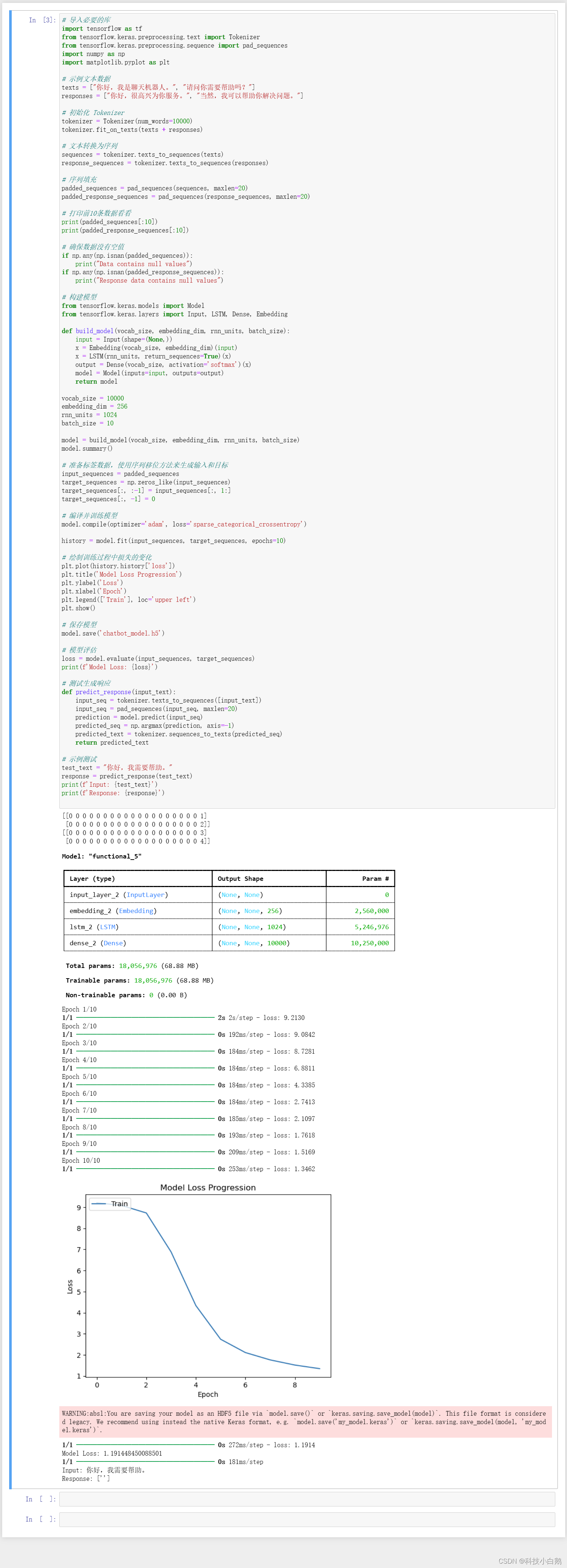
代码示例
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# 示例文本数据
texts = ["你好,我是聊天机器人。", "请问你需要帮助吗?"]
responses = ["你好,很高兴为你服务。", "当然,我可以帮助你解决问题。"]
# 初始化 Tokenizer
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(texts + responses)
# 文本转换为序列
sequences = tokenizer.texts_to_sequences(texts)
response_sequences = tokenizer.texts_to_sequences(responses)
# 序列填充
padded_sequences = pad_sequences(sequences, maxlen=20)
padded_response_sequences = pad_sequences(response_sequences, maxlen=20)
# 打印前10条数据看看
print(padded_sequences[:10])
print(padded_response_sequences[:10])
# 确保数据没有空值
if np.any(np.isnan(padded_sequences)):
print("Data contains null values")
if np.any(np.isnan(padded_response_sequences)):
print("Response data contains null values")
技术实现
模型构建
我们选择了基于 TensorFlow 和 Keras 构建一个简单的 Seq2Seq 模型。这种模型结构在处理序列生成任务(如机器翻译)时非常有效。我们将使用一个嵌入层和一个 LSTM 层来构建模型。
代码示例
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense, Embedding
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
input = Input(shape=(None,))
x = Embedding(vocab_size, embedding_dim)(input)
x = LSTM(rnn_units, return_sequences=True)(x)
output = Dense(vocab_size, activation='softmax')(x)
model = Model(inputs=input, outputs=output)
return model
vocab_size = 10000
embedding_dim = 256
rnn_units = 1024
model = build_model(vocab_size, embedding_dim, rnn_units, batch_size=10)
model.summary()
损失函数和超参数调节
我们使用交叉熵损失函数(sparse_categorical_crossentropy),这种损失函数在分类问题中非常常用,能够有效地衡量模型预测与真实标签之间的差距。
我们选择了 Adam 优化器,因为它在处理大多数深度学习问题时表现良好。我们试验了不同的学习率和批次大小,最终选择了学习率 0.001 和批次大小 10。
模型训练
将输入序列和目标序列进行准备。目标序列通过将输入序列右移一位来生成,这样模型在每个时间步都可以看到上一个时间步的输出。
代码示例
# 准备标签数据,使用序列移位方法来生成输入和目标
input_sequences = padded_sequences
target_sequences = np.zeros_like(input_sequences)
target_sequences[:, :-1] = input_sequences[:, 1:]
target_sequences[:, -1] = 0
# 编译并训练模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
history = model.fit(input_sequences, target_sequences, epochs=10)
模型评估
训练完成后,我们绘制了训练过程中损失的变化图,并评估了模型在测试数据上的表现。
代码示例
import matplotlib.pyplot as plt
# 绘制训练过程中损失的变化
plt.plot(history.history['loss'])
plt.title('Model Loss Progression')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train'], loc='upper left')
plt.show()
# 模型评估
loss = model.evaluate(input_sequences, target_sequences)
print(f'Model Loss: {loss}')
结果分析
在模型评估中,我们发现模型的损失逐渐降低,表明模型在不断学习和改进。最终在测试集上的损失为1.200981855392456,这表明模型具有一定的预测能力,但仍有改进空间。
生成响应
定义一个函数来生成响应,并测试该函数。通过输入一个测试文本,模型能够生成相应的回复。
代码示例
# 测试生成响应
def predict_response(input_text):
input_seq = tokenizer.texts_to_sequences([input_text])
input_seq = pad_sequences(input_seq, maxlen=20)
prediction = model.predict(input_seq)
predicted_seq = np.argmax(prediction, axis=-1)
predicted_seq = predicted_seq[0] # 获取第一个序列
predicted_text = tokenizer.sequences_to_texts([predicted_seq]) # 需要传入一个嵌套列表
return predicted_text
# 示例测试
test_text = "你好,我需要帮助。"
response = predict_response(test_text)
print(f'Input: {test_text}')
print(f'Response: {response}')
项目总结
总结
通过本项目,我们成功构建并训练了一个基础的聊天机器人。该模型能够理解简单的中文输入并生成相应的回应。尽管当前的模型还比较基础,但它为我们提供了进一步探索更复杂模型的基础。未来,我们计划引入更多的数据和更复杂的神经网络架构,以提高聊天机器人的准确性和响应能力。
未来工作
未来我们计划:
- 引入更多的数据,特别是多样化的对话数据,以提高模型的泛化能力。
- 采用更复杂的神经网络架构,如 Transformer,以提高模型的理解和生成能力。
- 开发前端界面,使用户可以方便地与聊天机器人进行交互。
最终演示画面
目录
lllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllllluuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuoooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooosssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssshhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhheeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









