







Lintcode数据结构有这么一些题目:


用任意的数据结构实现一个栈,我是用List实现的,记得写的时候写成List<Integer> array = new ArrayList<Integer>(); 因为List只是Interface,而实现List接口的有多个类,其中一种就是ArrayList,然后记住List的三种操作是add/remove/get,ArrayList可以通过remove操作删除任意下标的元素,可以通过get获得任意下标的元素,可以通过add在末尾添加元素。
40. Implement Queue by Two Stacks
用两个栈stack1、stack2 来实现队列,记得java中自带的Stack是这么写的Stack<Integer>。
push操作:就直接将元素加到stack1上。
pop操作:如果stack2里面有元素,就直接把stack2里的元素pop出来。如果stack2里面没有元素,就把stack1里的所有元素转移到stack2中,然后再把stack2里的元素pop出来。
top操作:类似于pop操作,不再赘述。
要求实现一个栈,这个栈除了push和pop操作外,还要有一个min操作,可以随时拿出stack里面的最小值。我是用2个栈实现的,一个栈用于存储基本元素,另一个栈用于存当前的最小值。
A)第一种方案比较耗空间,stack里面有n个元素,那minStack里面也得有n个元素。这样每次push的时候,minStack里都存进一个当前的最小值;每次pop的时候,当前的最小值也同时pop出来了。如下图所示:
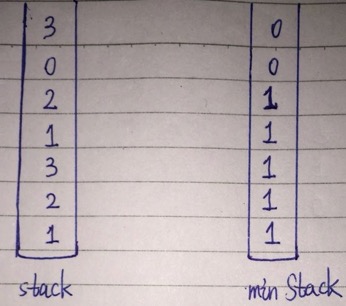
B)第二种方案比较省空间,minStack的上层元素比下层元素要小,minStack是一个最小元素在上面的栈。
每次push的时候,只有当新元素 ≤ minStack里最小的元素(即minStack的顶部元素)的时候,我才把新元素也push进minStack。
每次pop的时候,我先pop 主stack的top元素,而对于minStack的top元素,只有当stack里的top元素和minStack的top元素相等时,我才把minStack的top元素也pop掉。如下所示:

记得判断元素相等的时候用equals函数!!!如果在这里直接用==判断的话,他是判断地址而不是判断值
494. Implement Stack by Two Queues
用两个队列来实现栈,记得java中队列得这样声明才行:Queue<Integer> q1 = new LinkedList<Integer>(); Queue是Interface,实现Queue的方式之一是LinkedList
然后java自带的Queue有两种操作:往队列为部加元素是offer(),获得队列头部元素并同时删除队列头部元素的操作是poll()
我们用两个队列q1和q2来实现,其中q1是存元素的主队列,q2是辅助操作队列
实现栈的push操作时,直接往q1里面添加元素就行
实现栈的pop操作时,因为我要pop的是q1的最末尾的元素,所以我就先把q1的前n-1个元素放到q2,然后再把q1唯一的元素给弹出来。然后再把q2的元素放回q1(或者直接交换q1和q2的引用)
实现top操作和pop操作类似。
实现empty操作时,就判断q1和q2的大小是否为0
492. Implement Queue by Linked List
用链表实现一个Queue,要求有如下两个功能:
enqueue(item). Put a new item in the queue.
dequeue(). Move the first item out of the queue, return it.
实现方法就用头尾指针,进队的时候将尾指针的值设置为新元素,然后尾指针后面添加一个新的尾指针。出队的时候在头结点后面删除一个节点。纯粹考链表基本操作。
class Node {
public int val;
public Node next;
public Node(int n) {
val = n;
next = null;
}
}
public class Queue {
public Node first, last;
public Queue() {
first = new Node(-1);
last = new Node(-1);
first.next = last;
}
public void enqueue(int item) {
Node tmp = new Node(-1);
last.val = item;
last.next = tmp;
last = tmp;
}
public int dequeue() {
int tmp = first.next.val;
first.next = first.next.next;
return tmp;
}
}493. Implement Queue by Linked List II
多了几个操作,push front和pop back操作。
push_front(item). Add a new item to the front of queue.push_back(item). Add a new item to the back of the queue.pop_front(). Move the first item out of the queue, return it.pop_back(). Move the last item out of the queue, return it.
class Node {
public int val;
public Node next;
public Node(int n) {
val = n;
next = null;
}
}
public class Dequeue {
private Node first, last;
public Dequeue() {
// do initialize if necessary
first = new Node(-1);
last = new Node(-1);
first.next = last;
}
public void push_front(int item) {
Node tmp = new Node(item);
tmp.next = first.next;
first.next = tmp;
}
public void push_back(int item) {
Node tmp = new Node(-1);
last.val = item;
last.next = tmp;
last = tmp;
}
public int pop_front() {
int tmp = first.next.val;
first.next = first.next.next;
return tmp;
}
public int pop_back() {
Node p = first;
while (p.next != last) {
p = p.next;
}
int tmp = p.val;
p.val = -1;
last = p;
return tmp;
}
}229. Stack Sorting
对一个栈进行排序,要求只能用到一个额外的辅助栈,
| |
|3|
|1|
|2|
|4|
-| |
|4|
|3|
|2|
|1|
-借鉴冒泡排序的算法,我第一趟把原栈中最大的元素放入辅助栈,第二趟把原栈中第二大的元素沉入辅助栈,以此类推。
每趟遍历的目的就是为了找到原栈中当前的最大值。
可设置一个变量mid,用于记录那一趟遍历所找到的“当前”最大值。
在每一趟遍历中,借助那个变量mid找更新原栈中的最大值,同时把所有比mid小的元素都倒腾到辅助栈中。这个时候mid存入了当前的最大值,然后所有其它元素都在辅助栈中,原栈是空的。然后再把辅助栈中的所有比mid小的元素移动回原栈,再把mid移入辅助栈。这样就保持了辅助栈的下面的元素都比上面的大。
记住要用一个遍历count来处理多个元素相同的情况。然后把count数目个mid元素沉入辅助栈。
然后继续处理下一个原栈的栈顶元素,最后直到原栈中的所有元素都被转移到有序栈中!
总而言之,算法的思想就是借鉴了冒泡排序,借用一个辅助栈和一个中间变量,每趟都把栈的最大元素沉入辅助栈的下面。然后注意的一点就是如何处理存在多个相等元素的问题。
Time: O(N^2), Space: O(N)。算法直观的运行效果如下:
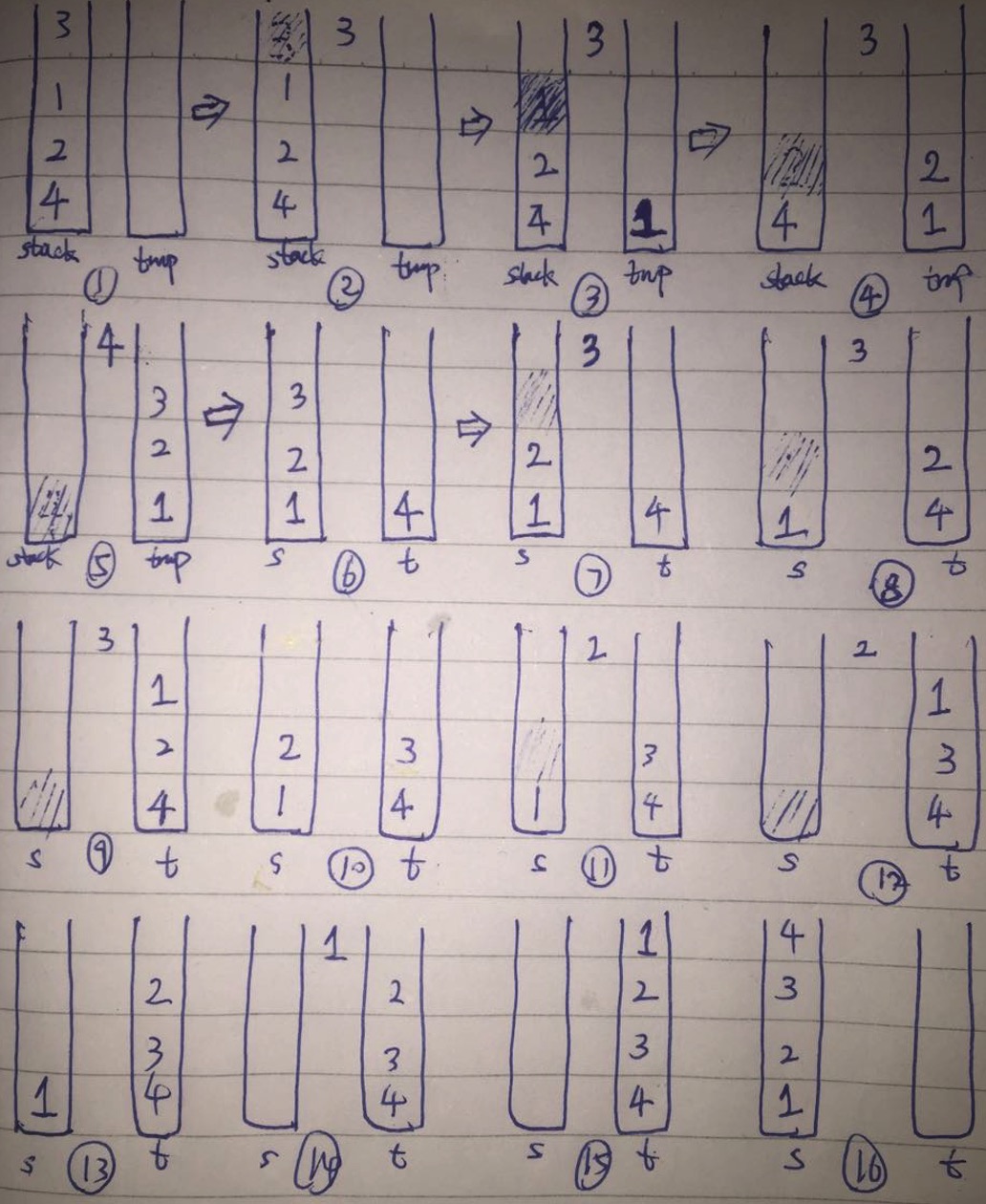
代码如下:
public void stackSorting(Stack<Integer> stack) {
// 辅助栈
Stack<Integer> tmp = new Stack<Integer>();
int mid = Integer.MIN_VALUE;
// 循环条件:当整个stack还没有排好序时
while (!stack.empty()) {
int count = 1;
if (!stack.empty()) {
mid = stack.pop();
}
// 把stack掏空,找出当前stack的最大值
while (!stack.empty()) {
if (stack.peek() <= mid) {
tmp.push(stack.pop());
} else {
tmp.push(mid);
mid = stack.pop();
}
}
// 复原stack
while (!tmp.empty() && mid >= tmp.peek()) {
// 处理相等元素的情况
if (tmp.peek().equals(mid)) {
count++;
tmp.pop();
continue;
}
stack.push(tmp.pop());
}
// 更新全局最大值
for (int i = 1; i <= count; i++) {
tmp.push(mid);
}
}
while (!tmp.empty()) {
stack.push(tmp.pop());
}
}要求实现一个hash函数:
hashcode("abcd") = (ascii(a) * 333 + ascii(b) * 332+ ascii(c) *33 + ascii(d)) % HASH_SIZE
= (97* 333 + 98 * 332 + 99 * 33 +100) % HASH_SIZE
= 3595978 % HASH_SIZE
For key="abcd" and size=100, return 78这道题主要考察对数字溢出的处理,只有把res声明为long长整型,并且在中途不断取模,才能不溢出。
public int hashCode(char[] key,int HASH_SIZE) {
long ans = 0;
for (int i = 0; i < key.length; i++) {
ans = (ans * 33 + (int)(key[i])) % HASH_SIZE;
}
return (int)ans;
}129. Rehashing
要求做一个hash,size是原来的两倍。就不断遍历原来的hash数组,如果那个位置上存在元素,则计算那个元素的新index下标,并加入到新的hash数组中去。记得处理一个下标下存的多个元素。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









