









预备知识:
随机变量:
给定样本空间 ,其上的实值函数
,其上的实值函数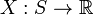 称为(实值)随机变量,如果X 是
称为(实值)随机变量,如果X 是  (实值)可测函数。初等概率论中通常不涉及到可测性的概念,而直接把任何的函数称为随机变量。
(实值)可测函数。初等概率论中通常不涉及到可测性的概念,而直接把任何的函数称为随机变量。
相关性:
在概率论和统计学中,相关(Correlation,或称相关系数或关联系数),显示两个随机变量之间线性关系的强度和方向。在统计学中,相关的意义是用来衡量两个变量相对于其相互独立的距离。在这个广义的定义下,有许多根据数据特点而定义的用来衡量数据相关的系数。
理论讨论:
例子:
首先介绍一个简单的例子,用户在当当或者亚马逊等购物网站上浏览一些商品后,即使没有登录,页面的某一块也会显示系统推荐给用户的商品。这些商品是如何计算出来的。用常识来思考这个问题很简单,对当前商品的浏览数据进行分析,对浏览过此商品的人曾经浏览过的其他商品进行分类统计,把浏览次数最多的商品展现给正在浏览此商品的用户。
理论分析:
再从理论上思考一下这个问题,随机变量为什么?计算了那两个随机变量的相关性?随机变量是用户A浏览的商品的序列,另一个随机变量是用户B浏览的商品的序列。计算可知两随机变量的相关性较强,来预测用户A将要浏览的下一个商品是什么。请记住任意两个随机变量都是可以计算相关性的,比如我每天在食堂吃的中饭的米粒数与晚上操场上散步的人数的相关性是可计算的。如果我根据将两个离散的随机序列抽样后计算出相关性显示两者是强相关的,那么我可以根据今天中午食堂阿姨给我打的饭的米粒数预测今晚操场散步的人数,甚至我可以故意通过今天中午少吃或者不吃来控制晚上操场上散步的人。我们结论是不是很神奇?
再想一点更神奇的,我买的彩票号码是随机变量,其他用户买的彩票号码也是随机变量,本次摇奖号码也可以看作是一个用户买的彩票号码。我可以通过计算所有用户的买的彩票号码的相关性来预测下一次开奖的号码,甚至我可以通过我买的彩票号码来控制今晚开奖的彩票号码。蝴蝶效应。
量化分析:
Manhattan Distance——曼哈顿距离
最简单的距离计算方法就是曼哈顿距离,在二维图上,点Amy的坐标是(x1,y1),X的坐标是(x2,y2),那么amy和X之间的曼哈顿距离就是:
|x1-x2|+|y1-y2|。
则X到三个人的曼哈顿距离是:
|
| 到X的曼哈顿距离 |
| Amy | 4 |
| Bill | 5 |
| Jim | 6 |
Amy是最近的,从图上也可以看出。那么如果Amy喜欢《The windup girl》,那么我们就把这本书推荐给X先生。
曼哈顿距离的优点是计算速度快,单过于简单。
EuclideanDistance——欧几里得距离
欧几里得距离是根据毕达哥拉斯定律得到的,至于该定律,想必大家都学过的,就不再多说了。
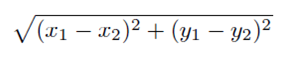
重新计算三个点到X的欧几里得距离:
|
| 到X的欧几里得距离 |
| Amy | 3.16 |
| Bill | |
| Jim | 3.61 |
N维扩展
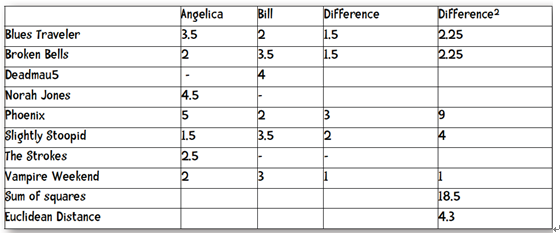
实际情况中,用户可能不止给两本书打分,而是多个,这样就把距离的计算从二维空间推广到了N维空间,当然计算方法是不变的。

计算距离的时候,我们只计算共同项,即标有-标记的书不在计算项目中。
Minkowski距离算法
从曼哈顿距离和欧几里得距离的计算公式,可以推演出所谓的Minkowski距离算法:

当r=1时,就是曼哈顿距离;
当r=2时,就是欧几里得距离;
当r=∞时,就是无上界距离。
程序实现:
首先如果用户A尚未登录,或者首次浏览该网站,则展现给他按分类浏览数最多的商品。
如果他已经浏览过n个商品,则推荐算法如《参考文献3》的程序。.http://my.oschina.net/jekey/blog/77748
结论:
很惭愧,本篇大部分都是摘自《参考文献3》中。但是有一个重要结论:用户可以通过购买彩票号码来控制开奖的彩票号码!!!!
参考文献:
1.http://zh.wikipedia.org/wiki/%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F
2.http://zh.wikipedia.org/wiki/%E7%9B%B8%E5%85%B3
3.http://my.oschina.net/jekey/blog/77748















 3539
3539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









