







1.什么是KMP算法
关于KMP算法先看这么一段英文解释:

那KMP算法到底是什么呢?往下看:

在上一段文字中,通过匹配搜索找到了KMP这个字符串,这就是KMP算法,其实就是一种匹配字符串的算法。
我们在主串中查找一个字符串,这个主串用S表示,将要查找的字符串称作模式串,用T表示。

如上图,要在主串S中找模式串T,如果使用朴素的模式匹配算法,会有如下过程:
①模式串依次与主串中的字符匹配,若当前字符匹配上就匹配下一字符,直到全部配对成功

②若配对不成功,i需要回溯,将模式串整体后移一位(到回溯后的i位置)继续①

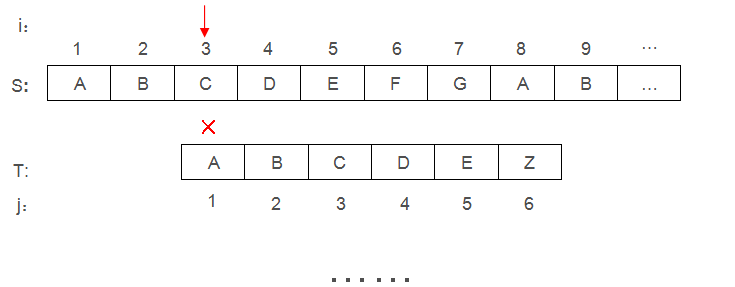

可见,只要出现不匹配字符,i 就需要回溯,j 也需要回溯到1重新开始匹配,这种方法虽然能匹配出模式串,但过程很麻烦,且做了许多不必要的工作。针对这个问题,国外的大佬们提出了KMP算法,利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
KMP:
kmp的算法核心在于发现字符不匹配时不回溯主串的 i 下标,仅仅靠回溯模式串的 j 下标,从而减少不必要的匹配过程。那当出现字符不匹配状况时,模式串的j该回溯到哪呢?这就需要我们根据模式串生成一个next[]数组,这个数组存储的数字告诉我们 j 该回溯到哪个位置。
next满足:
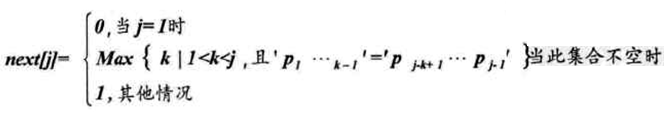
现在假设我们已经根据模式串T得出了一个next[]数组,我们利用这个next[]数组来体验一下KMP算法:

当 i 指向3时发现不匹配,此时next = 1,所以 j 回溯指向1,重新匹配

j 回溯到1后仍然不匹配,所以 i 指向下一个位置4,重新匹配

i 指向8时发生不匹配,此时next=2 , 所以 j 回溯到2位置,重新匹配

任然不匹配,此时next=1 , 所以 j 回溯到1位置,重新匹配

直到 j >6(模式串长度)时任不出现不匹配状况,说明匹配成功,找到模式串T!
代码示例:
int KMP(char *S,char *T,int *next)//S代表主串,T代表模式串
{
int i=1,j=1;
int s_length=strlen(S)-1;//由于字符串首位被占,计算长度时需要减去一位
int t_length=strlen(T)-1;
while(i<=s_length&&j<=t_length)
{
if(j==0||S[i]==T[j])
{
++i;
++j;
}
else
j=next[j];//不相等j就回溯,若j回溯到0说明无相等字符
}
if(j>t_length)//若j超出模式串T的长度,说明已找到,匹配成功
return i-t_length;//返回模式串在主串中的位置
else
return 0;
}
从这个例子中可以看出由于 i 不需要回溯, j 按照next表回溯,所以省去了许多不必要的匹配过程,效率得以提高。下面介绍如何求得next数组。
2.next数组的求取:
(1)推导
例如要求模式串ababaaaba的next数组

根据
①故当 j = 1 时,规定next[1]=0;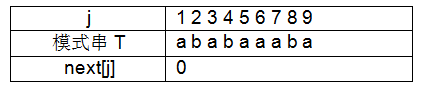
② j = 2 时,串取“a”,只有一个字符,属于其他情况故 next[2]=1;
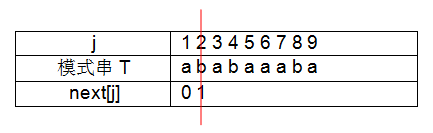
③ j = 3 时,串取“ab”,字符串的前缀=“a”,后缀=“b”,前缀与后缀不相等,故属其他情况,next[3]=1;
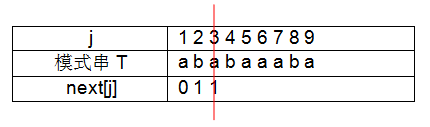
④ j = 4 时,串取“aba”,字符串的前缀取“a”,后缀取“a”时,前缀与后缀相等,且长度为1,故 next[4]=1+1=2;

⑤ j = 5 时,串取“abab”,字符串的前缀取“ab”,后缀取“ab”时,前缀与后缀相等,且长度为2,故 next[5]=2+1=3;
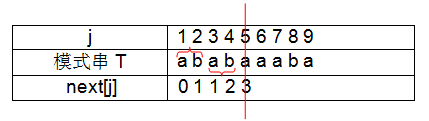
⑥ j = 6 时,串取“ababa”,字符串的前缀取“aba”,后缀取“aba”时,前缀与后缀相等,且长度为3,故 next[6]=3+1=4;
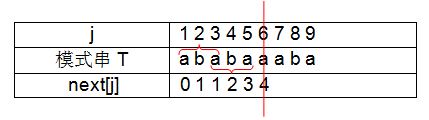
⑦ j = 7 时,串取“ababaa”,字符串的前缀取“a”,后缀取“a”时,前缀与后缀相等,且长度为1,故 next[7]=1+1=2;

⑧ j = 8 时,串取“ababaaa”,字符串的前缀取“a”,后缀取“a”时,前缀与后缀相等,且长度为1,故 next[8]=1+1=2;

⑨ j = 9 时,串取“ababaaab”,字符串的前缀取“ab”,后缀取“ab”时,前缀与后缀相等,且长度为2,故 next[9]=2+1=3;

最后求得next数组

(2)程序设计
刚才的推导易于理解,但不适合设计成程序,接下来继续以求模式串ababaaaba的next数组为例,按照设计程序的思路来推导设计
①初始状态如图所示,T[ k ]为模式串T[ j ]的拷贝,j 初始值为1,k 初始值为0,令next[1]=0

② 此时 j = 1,k = 0 ; k=0时,next[j+1]=k+1=1;

③ j 、k右移一位, 此时 j = 2,k = 1。T[ j ]与T[ k ]不相等,k需要回溯到next[k]位置,即k=next[1]=0位置;
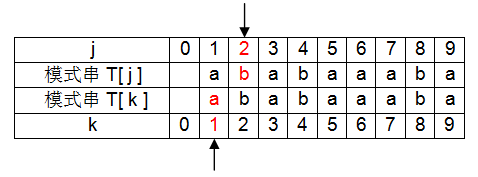

此时,k=0,故有next[j+1]=next[3]=1
④ j 、k右移一位, 此时 j = 3,k = 1。T[ j ]与T[ k ]相等,next[ j+1]= k+1=2 ,即next[4]=2

⑤ j 、k右移一位, 此时 j = 4,k = 2。T[ j ]与T[ k ]相等,next[ j+1]=k+1=3 ,即next[5]=3

⑥ j 、k右移一位, 此时 j = 5,k = 3。T[ j ]与T[ k ]相等,next[ j+1]=k+1=4 ,即next[6]=4

⑦ j 、k右移一位, 此时 j = 6,k = 4。T[ j ]与T[ k ]不相等,k需要回溯到next[k]位置,即k=next[4]=2位置;
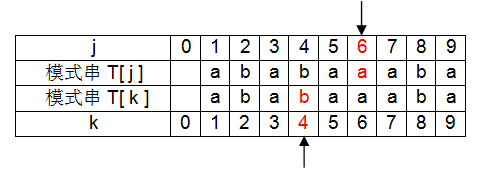
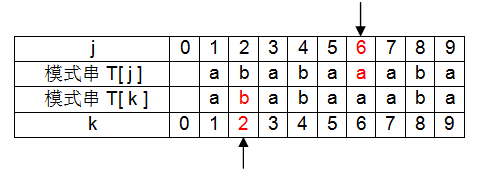
此时 j = 6,k = 2。T[ j ]与T[ k ]不相等,k需要回溯到next[k]位置,即k=next[2]=1位置;

此时 j = 6,k = 1。T[ j ]与T[ k ]相等,next[ j+1]= k+1=2 ,即next[7]=2
⑧ j 、k右移一位, 此时 j = 7,k = 2。T[ j ]与T[ k ]不相等,k需要回溯到next[k]位置,即k=next[2]=1位置;
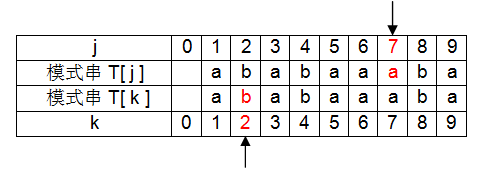

此时 j = 7,k = 1。T[ j ]与T[ k ]相等,next[ j+1]= k+1=2 ,即next[8]=2
⑨ j 、k右移一位, 此时 j = 8,k = 2。T[ j ]与T[ k ]相等,next[ j+1]=k+1=3 ,即next[9]=3

至此,next数组求解成功。
代码示例:
void getNext(char *S,int *next)
{
int j=1,k=0;
next[1]=0;
int s_length=strlen(S)-1;//由于字符串首位被占,计算长度时需要减去一位
while(j<s_length)//注意此处i不能等于length,不然next[i+1]超出范围
{
if(k==0||S[j]==S[k])
{
next[j+1]=k+1;
++k;
++j;
}
else
k=next[k];//不相等j就回溯,若j回溯到0说明无相等字符
}
}
3.KMP改进,nextval数组的求取
我们发现,利用next数组进行KMP匹配时任然会出现多余的匹配步骤,于是提出了一种基于next数组改进后的数组nextval。
nextval数组求取需要参考next数组。核心在于:若无相等前后缀,维持原来的next[ j ];若有后缀与前缀相等,且前缀在k处结束,nextval[ j ]= next[ k ]。
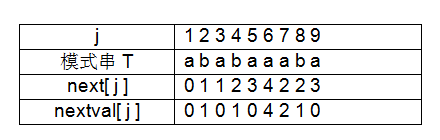
例如,上表中的模式串,
j = 1,nextval[1]=0;
j = 4,子串为“abab”,在此,可以取后缀“ab”与前缀“ab”,他们相等,且前缀最后一位“b” 在位置 j = 2处,故nextval[4 ] = next[ 2 ] = 1;
j = 6,指向字符“ababaa”,此处不存在相等的前后缀,所以维持原值,nextval[6 ] = next[ 6 ] =4
代码示例:
void getNextval(char *T,int *nextval)
{
int i=1,j=0;
nextval[1]=0;
int s_length=strlen(T)-1;//由于字符串首位被占,计算长度时需要减去一位
while(i<s_length)//注意此处i不能等于length,不然next[i+1]超出范围
{
if(j==0||T[i]==T[j])
{
if(T[i+1]!=T[j+1])
nextval[i+1]=j+1;//维持next
else
nextval[i+1]=nextval[j+1];//继承
++j;
++i;
}
else
j=nextval[j];//不相等j就回溯,若j回溯到0说明无相等字符
}
}















 32万+
32万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









