







 本文介绍了BWT轮换矩阵的完全桶排序算法,详细阐述了算法的核心思想、预处理、分发、收集和收尾步骤。算法通过桶排序处理大量基因串,利用字符特点进行分布式处理,虽然涉及大量文件操作,但易于扩展到分布式系统,适用于大规模数据处理。
本文介绍了BWT轮换矩阵的完全桶排序算法,详细阐述了算法的核心思想、预处理、分发、收集和收尾步骤。算法通过桶排序处理大量基因串,利用字符特点进行分布式处理,虽然涉及大量文件操作,但易于扩展到分布式系统,适用于大规模数据处理。
BWT轮换矩阵之完全桶排序算法

算法所需要的数据保存在堆中的一个区域,这个区域的头为指针P,区域长度为N。那么第一个字符串便是从P到P+(N-1)。第a个字符串的第b个元素为 P+(a + b)%N。
F a(b)= P+( a + b)%N.
核心思想:
算法的核心思想就是利用人类基因组串内有用字符只有ACGT的特点,对数百万个基因串进行桶排序,并且对每一个子桶也进行相同的桶排序,直到桶里边的元素只剩下1个或0个,触法桶的收集。桶的收集在检查到父桶可以合并时触法合并,直到合并完成。
详细:
桶存放的是串标识。桶里边的元素4,就表示第5个串,按照上页得公式便表示从P+(5+0)%N到P+(5+N-1)%N的串。
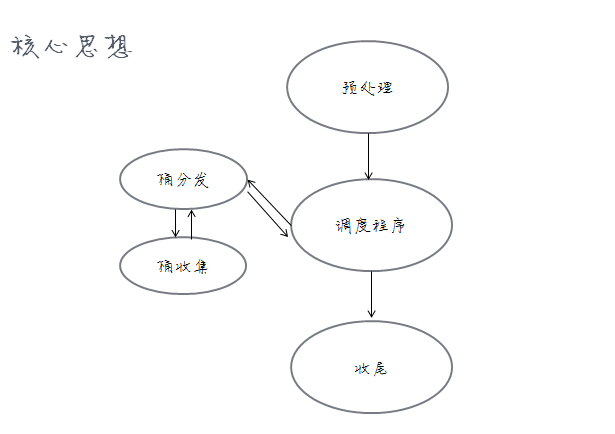
预处理:首先由预处理程序从文件中读入原始数据文件,对所有的N进行过滤,并将其他内容加载到内容堆中的一个字符数组中。然后初始化一个0桶,这个桶包含了所有的字符串(桶里边只存的是字符串所在的偏移,比方说,我存了4,那么就表示自 P+4 到P + (4 + N-1)%N的那个字符序列)。
分发:由控制程序将0桶传递给分发程序进行分发处理。分发程序按照字符序列的首个字母是A还是C、G、T,把这些字符标示分发到0A、0C、0G、0T桶里边。并且一边分发一边统计分发到这些桶里的entry数量,若数量大于等于2则继续下一层分发,否则对桶做标记,并触发收集。(比如:如果检测到桶0AA的数据条目少于两条,将桶0AA重命名为桶$AA)。
收集:收集时先检测同目录的桶是不是都被收集,若有桶没有收集,则放弃执行,否则生成父收集桶,然后将四个子桶的数据收集到父桶之中。如果父桶不是$(最终桶),则触发父桶的收集。(同样接着前面的例子:现在触发了对桶$AA的收集,则首先检测$AC、$AG、$AT是否存在,如果有一个不存在则放弃执行并退出,如果都存在则创建父收集桶$A,并把$AA、$AC、$AG、$AT里边的数据收集到父桶$A中)
收尾:程序到这里,顶层收集桶$已经生成。依次提取桶中的串,输出此串的最后一个字符。即可得到bwt轮换矩阵的最后一列L。比如在里边拿到一个int数据a,则需要输出的是P+(a+N-1)%N。
问题: 这里最直接的一个问题就是,桶作为一个文件时,文件的名称的长度会随着原始数据的增长而同步增长。解决的办法是,在逻辑上还是使用刚才提到的方法,而在实际使用桶时,使用此桶名的32位md5值作为实际的文件名称。
还有一个问题,就是如果使用上面介绍的方法时在操作上会出现内存不够、堆栈溢出的情况,解决的方法也很直接,通过第三方控制函数对这两个原子操作进行控制,彻底抛弃递归方法。这个在以后慢慢改过来,现在贴一个递归的实现,注意,这个程序有bug,主程序我会在有时间了把控制程序加进去,就可以避免内存问题了。
想了想还是直接上传工程吧,工程是code::blocks的工程,使用标准C,现在的工程还很烂,等过几天改改。
链接地址:http://download.csdn.net/source/3414631
算法的优缺点: 缺点很明显了,就是需要大量的文件操作,需要动态的建立和删除文件,但是优点也是很明显的,整个生成过程不需要比较操作,操作被原子的分为了分发和收集,酱紫的模型与分布式hadoop几乎完全一样,也就是说,这样的模型很容易被扩展到分布式处理应用当中,所以,尽管在单机看来,不如其他一些成型的算法,也不如桶排加快排的做法,但是可以很容易的扩展到分布式处理当中,那时候性能的提高就非常明显了。















 2599
2599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









