









文章目录
前言
在前面一段时间,我一直在研究python爬虫领域的知识,并且接了一些爬虫的单子来训练自己,在应对客户的各种奇葩要求和处理爬虫中遇到的各种奇怪情况之后,我也慢慢摸索出了一套写爬虫的基本流程思路,在这里分享给大家。作为爬虫学习阶段的收尾了。我要向更高方向进发啦!
注:本篇文章讲的是流程而不提供问题的具体解决办法,具体问题还请具体摸索解决。这里默认大家已经有了一定的爬虫基础,但是对完整的网页分析和爬取流程依旧有困惑。
二注:本篇文章不考虑selenium的使用,因为想用selenium来爬取较多的数据的话不太现实,速度太慢了。
环境(工具)
-
谷歌浏览器(或者火狐浏览器)
-
mitmproxy (通过pip工具下载)
-
pycharm(或者vscode)
-
python3.7及以上
接下来就是爬虫编写的完整流程和中途会碰到的问题分析。
1.网页初步分析
1.网页类型
先悄悄告诉大家,如果大家需要爬取某个网页的话,先去找找这个网页有没有移动版本也就是手机端的页面,通常来说手机端的页面会简单很多。
网页类型可大致分为单页类型, 瀑布加载类型,列表翻页类型,混合类型,单页类型如下所示:
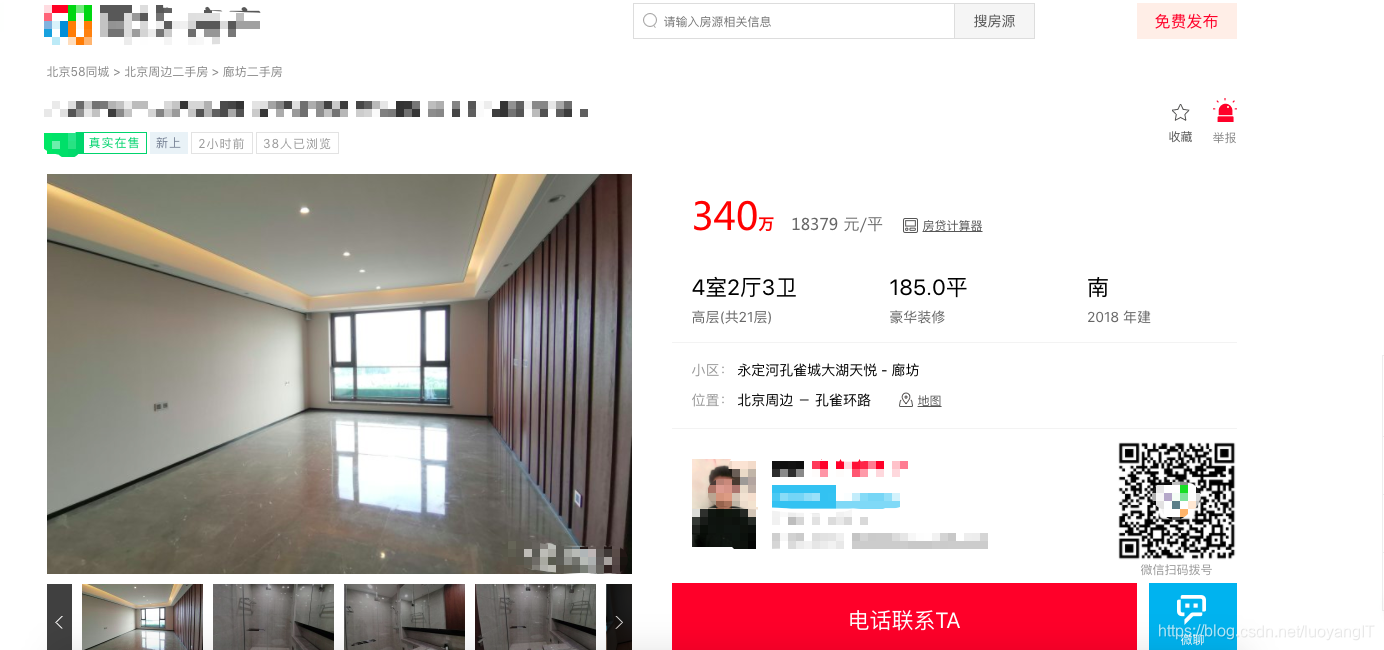
一般这种网页也叫做信息详情页,简称详情页。没有列表出现,有的只是具体信息的排版。信息详情页可能使用ajax异步加载,也可能直接使用静态页面放在html文件当中呈现。
接下来看看瀑布加载类型:
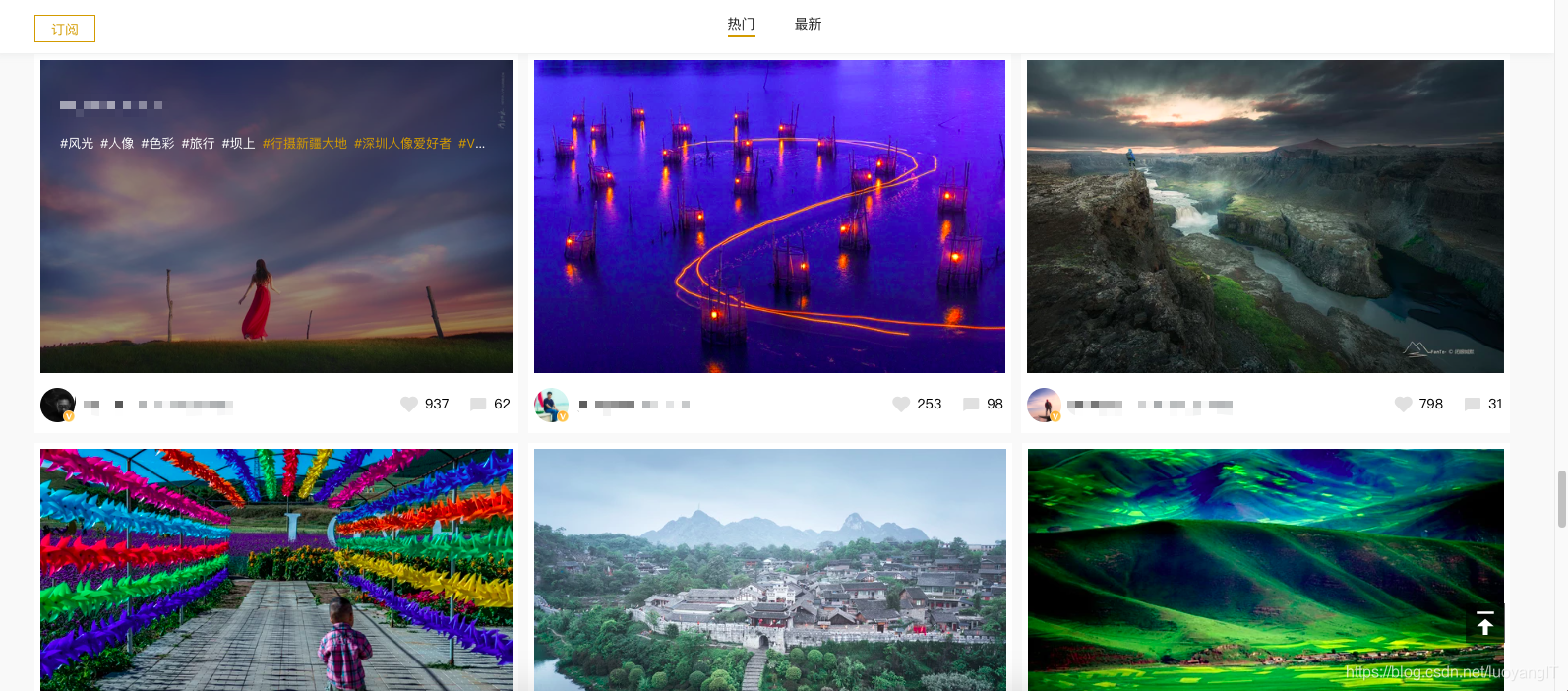
瀑布加载类型,往往会用在图片网站当中,同时,它也经常和列表翻页类型一起出现,判断瀑布加载类型网页的最简单办法就是向下滑动滚动条,若到底之后又有新的内容展现出来同时滑动条往上面自动移动了,那基本确定是瀑布加载类型。瀑布加载类型一般采用ajax异步加载请求方式实现。
然后是列表翻页类型:
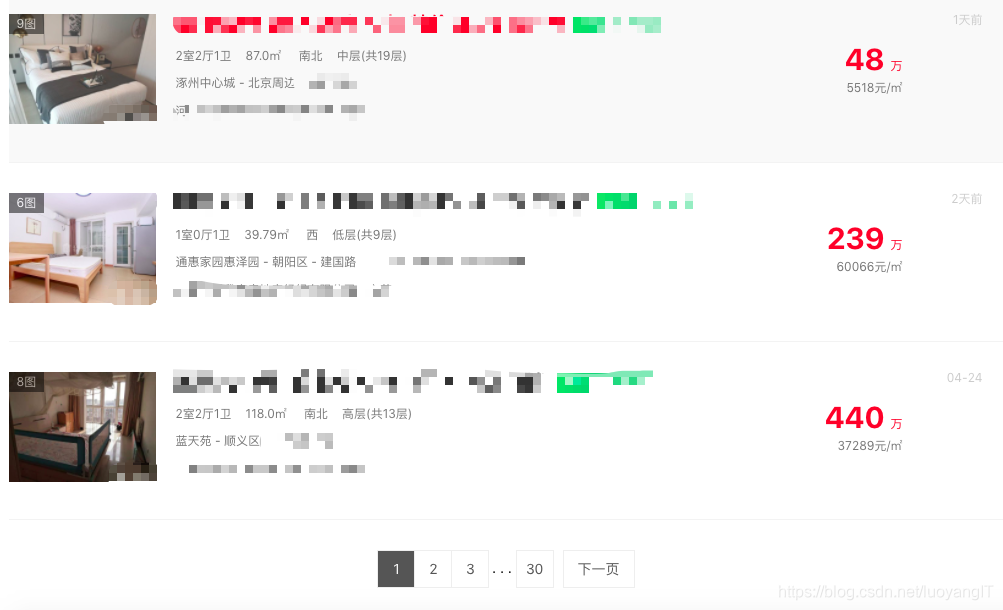
这种页面是爬虫中最常见的一类页面,其标志性在于其页面中往往有许多个相同结构的信息条,并且在底部带有翻页功能,这一类信息往往都是ajax异步加载,很少有直接放在html静态页面里面的。如果我们需要获取的信息从列表页就可以直接获取,那事情就变得非常简单,直接翻页获取每一页的每个列表信息即可,若是需要更详细的信息,则需要通过列表页获取详情页链接,然后进入详情页抓取信息。
最后是混合页面:
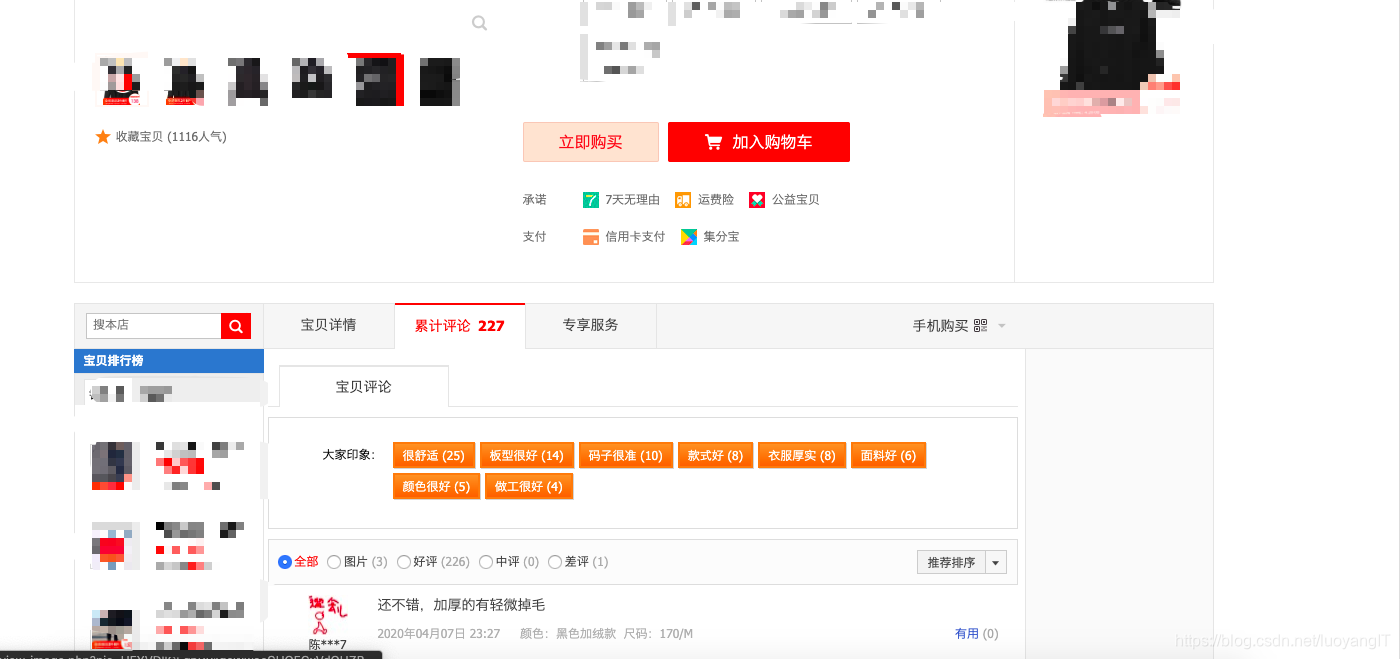
混合类型是指一个页面中分了不同的区,不同的区是不同类型的页面。常见于需要爬取评论的情况。比如上图中,是一个淘宝商品的详情页,对既需要商品详情信息又需要评论信息的人来说。这就是一个混合类型页面,上半区是详情页也就是单页类型,而评论部分则是列表翻页类型。
2.信息来源判断
网页类型判断出来之后,还需要更进一步判断,分析页面信息的来源:
信息来源就两种,静态页面 或者 Ajax异步加载
判断信息来源的方法也很简单:
F12打开页面审查,然后从网页中复制一部分需要抓取的关键信息利用F12中的搜索功能进行搜索(在审查界面中ctrl+f打开),一般情况下都能找到。然后根据信息所在的位置确定是html静态页面加载还是ajax异步加载。
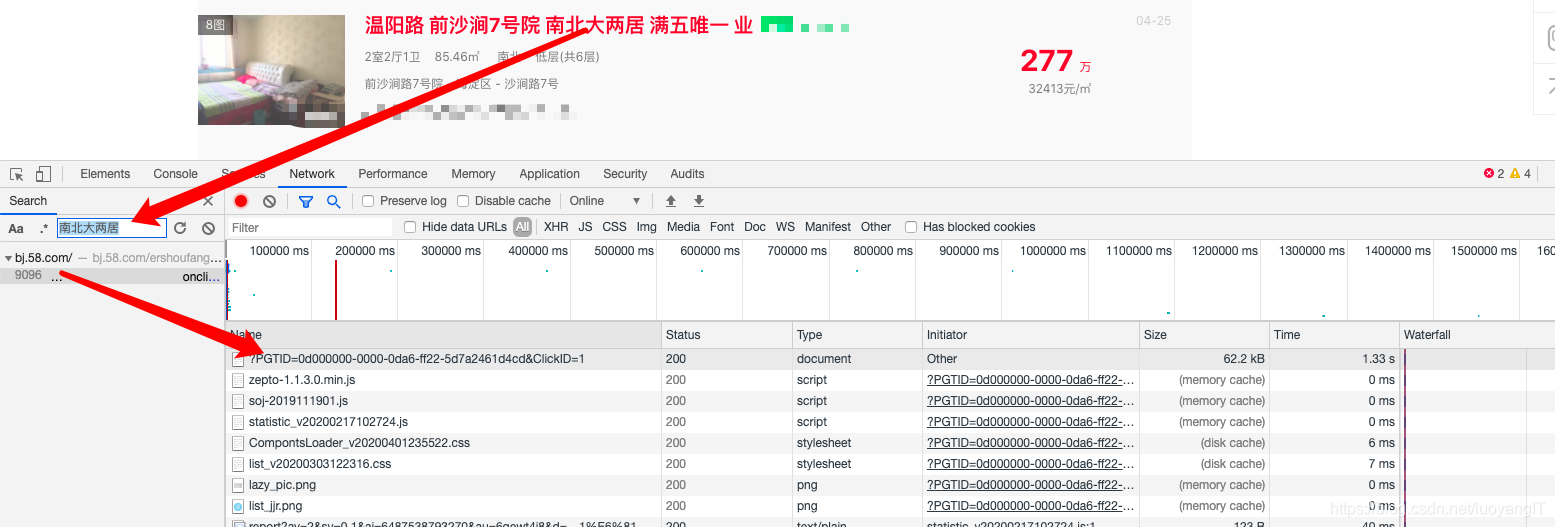
这里额外说明一下,如果搜索不到怎么办。
有两种情况:
一种是出现了css字体加密,这种情况请自行解决css字体加密的问题,本文不作介绍。
第二种是文字信息存放在异步加载的页面中,同时是处于一种被编码的状态,也就是unicode编码的状态,所以搜索不到,这种情况属于异步加载,可以通过抓包打断点的方式锁定位置,同时也请自行解码处理。
页面类型和信息来源分析完毕之后,我们进入到分析url和请求头的过程中
2.请求url优化和请求头分析处理
1.url优化
我们请求的url往往是类似这样的
https://xxxxxx.xxxx.com/xxx.html?a=xxx&b=xxx&c=xxx
在html后面加个?然后带上一大堆a=xx类似的参数并用&分割开来。
这些参数有些是必要的,但是很多都是无用的,只会降低我们请求网页的速度(在大规模爬取中这个很重要)。
所以这里需要用中间人工具mitmproxy来筛选去除那些无用的参数,以提高我们的请求速度。
2.请求头分析处理
这一步是重灾区,千千万万个爬虫在这里倒下了,因为,这一步可能会碰到一个非常难的问题:js参数加密。
首先,放轻松,js参数加密的网站数量还是不太多,我们按照正常的流程来进行。
同样的,这一步需要用到mitmproxy中间人工具。 看看下面这看花眼的request请求头
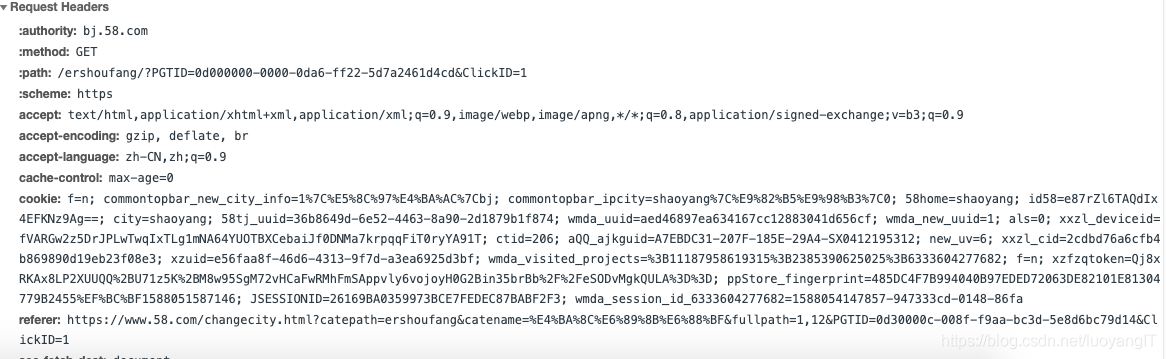
以我的经验,我可以负责任的告诉你,这些参数百分之九十以上都是不必要的!
一般,对于反爬不严的网站,我们的请求头就只需要下面这几个:
accept, accept-encoding, accept-language, user-agent
这几个参数只要放到请求头中,可以解决半数以上的网站
利用中间人工具首先判断这样是否可行,如果不可行,我们再一点点补上参数。
其中,如果网站需要登陆的话,那么cookies中需要保留其中一部分记录了登陆信息的值,至于是哪几个需要具体情况具体分析。
js加密的参数一般来说有三种存在形式
1. 放置在get请求中的cookies中。
2. 放置在get请求的QueryString参数重。
3. 放置在post请求的post参数当中。
这里大致说一下,碰到js加密参数的一般处理方法。
第一点也是最重要的一点:去搜索引擎搜索——对于js加密参数这种东西,如果网上有现成的,就千万别傻傻的去自己做,找现成的,哪怕是过时了,对于你之后分析也会有很大的参考作用。
第二就是,利用浏览器的调试功能,打断点,逆向追踪到这个加密参数开始生成的地方,中途的每一步都打上断点。 最后逆向分析完成之后,再一步步返回去,把中途的js代码扣下来,放到一个文件中去,然后利用python的运行js的库(有三种,可自行上网搜索)运行它的js代码生成加密参数。
js加密这一部分没有一劳永逸的办法,除非你用的是骇客技术,直接走后门,肛就完事了,否则的话都是需要具体情况具体分析的。
url和请求头参数分析完毕之后,就开始进行页面结构的分析和数据抓取
3.页面元素分析和数据抓取
1.静态页面数据抓取
静态页面的数据抓取没什么好说的,很简单。
一般来说用来提取网页结构的工具有两种: xpath和Beautifulsoup,个人更加喜欢xpath一点,简单明了上手快。(好吧就是我懒)
2.ajax异步请求数据抓取
这部分的变化稍微有点多。
首先到这一步需要保证已经对异步请求的接口分析完毕,能正确拿到ajax异步数据了。
然后ajax异步数据返回的格式大致有两种:
第一种就是返回json格式数据,这个是比较好抓取的,直接用json库loads一下然后提取数据就ok了。
第二种是返回html结构数据,我们拿到这部分数据之后,还往往需要利用上述两个工具之一对这部分数据进行提取,拿到需要的数据。
如果你们还发现请求到了另外结构的数据,可以发给我看一下,我也对这个挺好奇的。
页面结构和数据分析完毕之后,咱就准备真正开始跑爬虫啦,还有最后一步
4.请求头和代理的使用
1.随机请求头
据说在每次请求更换不同的请求头能在一定程度上降低爬虫被抓住的概率(理论上来说有一定道理,但是实际有没有用我也没有具体的数据,无法给大家一个明确的答案)
如果有需要可自行在搜索引擎中查找ua请求头大全。
这里有一个坑需要提醒大家(我踩过,摔的老惨了),如果你爬取的是pc端的网页,那么你的请求头里面最好不要有移动端ua头,这可能会让网页变成移动端的样式但是你依旧认为它是pc端,导致数据抓取失败。
移动端同理。
2.使用代理ip
这一步视情况而定,使用的条件如下:
1. 爬取的页面非常多,上万甚至上十万个页面。
2. 时间所迫,需要爬取的速度很快。
3. 网站反爬严格,频率控制的很低。
以上条件只要满足一个就可以考虑使用代理了。
这里我需要打一下自己的脸,之前我发过一篇文章一篇文章让你拥有用不完的ip代理,确实我没骗你们哈。ip代理确实用不完。
但是免费ip终究是免费ip,数量再多也无法弥补质量的差距,质量实在太差了,严重影响爬取速度,不适合用在正式,有一定规模的爬虫当中。
所以这里如果有需要的话,可以去购买付费代理。质量是真的好,并且提供小时包和日包,大家自行搜索,我就不打广告了。
5.爬取
以上就是编写一个爬虫的流程了,当然,即使经过每一步的认真分析,在真正爬取的时候依然会碰到一些奇怪的问题。
比如由服务器端引起的问题,比如网页结构的稀有变化,比如碰到302重定向问题。
这些问题都是需要在碰到的时候具体分析的,我在这里提个建议——多使用try语句,在出错之后把出错的网址和错误都打印出来,然后手动打开这个网址,根据错误来分析,这样可以有效的减少解决错误所用的时间。
如果爬取的数据量很大的话,不太建议手动多进程多线程,很难把握这个度。建议使用scrapy框架,这个框架是异步的,亲测可以把我i5的cpu跑满,异步请求非常快,而且资源调度很合理。
以上流程同样适用于使用scrapy框架的朋友。
6.后记
爬虫部分到这里我就告一段落了,对于这段时间的爬虫学习和经历,我还是有一些感想。
相比较于python其它的应用,比如大数据,机器学习,数据分析,人工智能来说,爬虫是一个上限比较低的技术,可能更多的是处于一种出卖劳动力的状态。(别跟我说搜素引擎,那已经不仅是爬虫了)
我这里说的是指只爬取数据,不对数据进行整理和分析。因为我个人在接单的时候,往往爬取数据是第一步,之后就是数据分析,建立模型预测等等。后面两个才是重头。
另外就是,对掌握了爬虫技术并且接单应用的人来说,其实心里还是有点顾忌,因为爬虫这项技术是处在触犯法律的边缘上了,所以在这里跟大家说一下:不要爬取不能爬的数据,比如私人信息,个人电话号码,家庭住址等等数据,这些不要去触碰,要有自己的判断力。
我和我的一位老师说过这些事情,老师的一句话让我警醒了:把接单当作学习成果的阶段性检验和巩固,而不是当作目标。
所以这里我也把这句话送给和我状态差不多或者正在朝着这个方向去的朋友们。
我是落阳,谢谢你的到访!
如果喜欢的话可以关注我的个人公众号【阳仔不想当码农】














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









