







- @author : 罗正
- @date time:2016年9月18日 上午9:20:34
无向图API,深度优先搜索参照上一篇文章
深度优先搜索
本文主要解析广度优先搜索
广度优先搜索
基于邻接表实现的无向图
1. 思想:使用队列的数据结构(FIFO),首先加入顶点,然后在队列中删除顶点,并且将该顶点相连的所有顶点依次加入队列中,再循环处理这些顶点(和处理最开始的顶点相似),直至所有顶点均被访问。
如图:
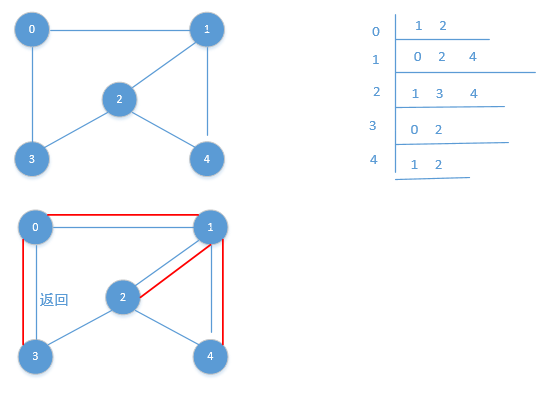
由图中可以看到:
1>最开始处理顶点若为0顶点,则先在队列中删除顶点0,再将顶点1,3加入到队列中;
2>那么接下来处理的就应该是1顶点,此时将1顶点在队列中删除,再添加2,4顶点到队列中;
3>在这个时候,处理的不是2,4顶点,而是处理队列中的第一个元素3顶点,于是在队列中删除3顶点,发现0,2顶点均是被标记了的;
4>接下来,就处理2顶点,在队列中删除2顶点,可发现1,3,4都被标记了。
5>最后处理4顶点时,在队列中删除4顶点,发现1,2顶点均被标记。
6>结束。
2. 实现
package graphTheory;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
/**
* @author : luoz
* @date time:2016年9月18日 上午9:21:08
**/
public class BreadthFirstPaths {
//the vertex is called dfs()
private boolean[] marked;
//first vertex to last vertex way
private int[] edgeTo;
//the start point
private final int s;
public boolean marked(int w)
{
return marked[w];
}
public boolean hashPathTo(int v){
return marked[v];
}
//method:set up a DepthFirstSearch
public BreadthFirstPaths(Graph G,int s){
marked = new boolean[G.V()];
edgeTo = new int[G.V()];
this.s = s;
bfs(G,s);
}
public void bfs(Graph G ,int s)
{
Queue<Integer> queue = new LinkedList<>();
//marked the start point
marked[s] = true;
//add the point to the queue
queue.add(s);
while(!queue.isEmpty())
{
//remove the next point
int v = queue.remove();
for(int w : G.adj(v))
if(!marked[w])
{
{
edgeTo[w] = v;
marked[w] = true;
queue.add(w);
}
}
}
}
public Iterable<Integer> pathTo(int v)
{
if(!hashPathTo(v))
return null;
Stack<Integer> path = new Stack<>();
for(int x = v; x != s;x = edgeTo[x])
path.push(x);
path.push(s);
return path;
}
}
广度优先搜索适合问题
单点最短路径:
给定图和一个顶点,是否存在该顶点到目的顶点的路径,若存在,输出最短路径。
有关于最短路径的问题,都应该考虑广度优先搜索。
深度优先搜索与广度优先搜索区别
深度优先搜索
可以看作是一个人走迷宫,只可以走到已经标记的顶点才能回头,而回头也是回到上一个顶点。
所以使用的数据结构是栈(后进先出LIFO)。
广度优先搜索
可以看作是一群人走迷宫,一个顶点一个顶点的走,每个人都是走到下一个顶点就回头。
使用的数据结构则是队列(先进先出FIFO)。
算法第四版















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









