






这是计算语言学的课程作业,对于n元语言模型不必多说。
先看一下程序的整体架构
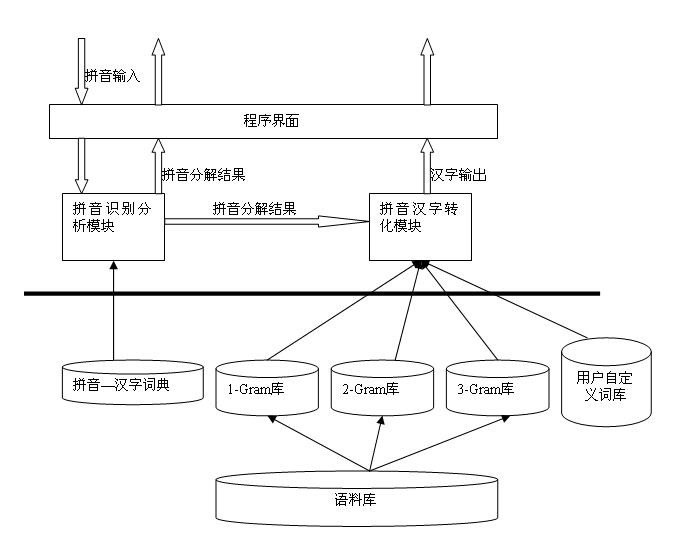
这里只对我自己在些这样一个程序时遇到的一些问题做一些总结。
1.nGram非常稀疏
因为nGram非常稀疏,会导致0概率问题出现。我在程序中使用3元语言模型,所以最终使用3元模型和1元,2元模型的加权值来代替3元模型的概率。
nGram的稀疏,还带来一个问题,提取的nGram中有一些频率极低,这种nGram我认为工程上应该舍弃,因为语料规模即使很大,对于全局空间来说还是很小的,又考虑到中文语言的一定随意性,所以这种频率极低的nGram可以取出,这样也可以减小生成nGram文件的大小。
2.加载资源文件,消耗大量内存
我首先从一个1G左右的网页数据库中生成了3个nGram文件(1gram.dict,2gram.dict,3gram.dict),经过处理,3个文件大小分被是400k,2.8M,7.2M左右,但是加载到内存中却需要消耗差不多170M内存。这个是在windows下看到的(我最初是在linux下编写的程序,之后想增加一个可视化的界面,所以移植到VC6下了)。这个问题,我现在还没有解决。值得一提的是,我是把文件加载到map这样一个容器中的,师兄说map是基于红黑树的,不知道是不是这个容器导致消耗了大量内存,有空要好好研究一下stl。
3.程序中只使用了整数运算,导致整数运算溢出
对每次运算结果做了归一化处理。这个不详细说了。
最后说几句,现在程序的主算法部分基本完成,一半的工作应该是做完了,测试了一些,结果也还不错。下一步想给程序加上一个如现在常用拼音输入法那样的界面,还需要好好研究一下windows编程。后面我会给出重要算法的源代码,并作进一步改进。















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









